trilingual_fraud_consumer_protection_v2
收藏Hugging Face2026-04-28 更新2026-04-29 收录
下载链接:
https://huggingface.co/datasets/karanverma19/trilingual_fraud_consumer_protection_v2
下载链接
链接失效反馈官方服务:
资源简介:
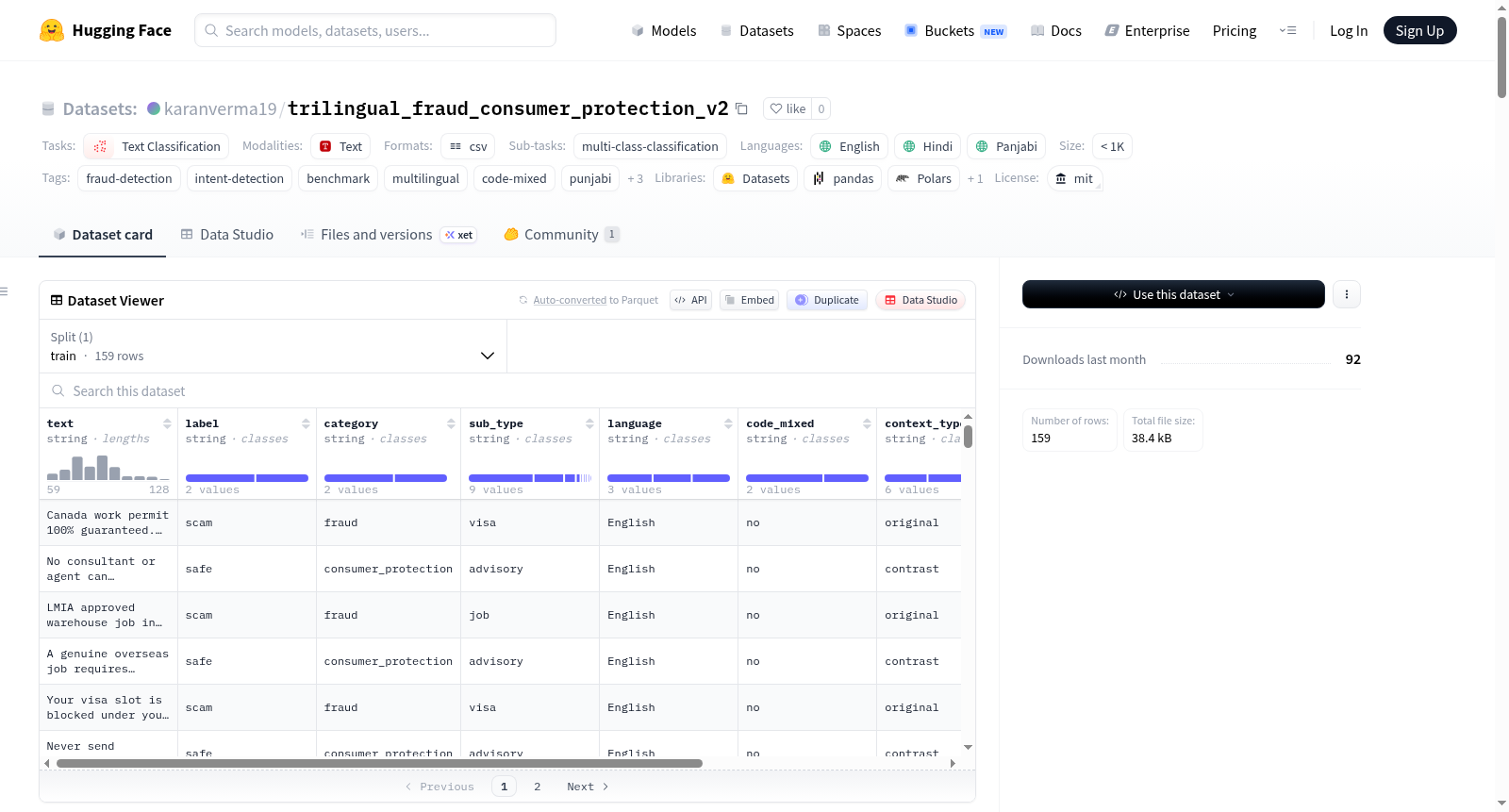
Punjab欺诈意图基准数据集(三语–旁遮普语/印地语/英语)专注于识别旁遮普-印地-英语混合对话中的意图边界,特别是在欺诈检测领域。该数据集旨在解决现实世界中欺诈信息与正常通信之间难以区分的难题,强调信息意图的微妙差异而非明显的诈骗信号。数据集包含159条样本,涵盖旁遮普语、印地语和英语,每条样本标注为诈骗或安全信息,并包含类别、子类型、语言、代码混合情况、上下文类型、推理标签和难度等级等字段。数据集适用于欺诈检测系统、多语言NLP基准测试和消费者保护研究等场景。所有样本均为基于常见欺诈模式的合成数据,不包含个人或敏感信息。
创建时间:
2026-04-20
原始信息汇总
数据集概述:Punjab Fraud Intent Benchmark(旁遮普语/印地语/英语三语欺诈意图基准)
数据集核心定位
该数据集聚焦于意图边界识别这一难题——在旁遮普语、印地语和英语混合的日常对话中,许多消息外表相似但意图截然不同。传统数据集侧重明显诈骗信号,而本数据集专注于捕捉“看似正常但实际危险”的细微差异。
语言与分类
- 语言:英语(en)、印地语(hi)、旁遮普语(pa)
- 任务类型:文本多分类
- 标签:scam(诈骗)/ safe(安全)
- 许可证:MIT
数据集规模与质量
- 总行数:159条
- 缺失值:0
- 重复文本:0
- 推理标签类型:23种
- 上下文类型:原始(original)、对比(contrast)、边缘案例(edge case)
数据结构
每条记录包含以下字段:
text:消息内容label:诈骗或安全标签category / sub_type:签证、工作、OTP等类别language和code_mixed:语言及代码混合情况context_type:原始/对比/边缘案例reasoning_tag:潜在信号类型(如紧迫性、权威性等)difficulty:相对复杂程度
数据特点与挑战
- 对比性示例:诈骗消息与安全消息仅存在词语层面的细微差异(例如:“我们可以加急处理您的签证,如果您今天付款” vs “我们可以指导您完成签证流程”)
- 边缘案例:包含人类都难以区分的困难样本,如看起来紧急但合法的提醒、礼貌但隐含付款压力的咨询风格消息
- 语言模式:诈骗消息常以尊重和熟悉感开头,逐步建立信任,然后引入紧迫性和付款要求,而非直接使用攻击性语言
实际背景
数据集灵感来源于旁遮普地区常见欺诈模式,特别是:
- 加拿大工作许可诈骗
- LMIA工作虚假承诺
- IELTS操纵服务
- 大使馆或高级专员公署冒充
- WhatsApp预付费用施压
- OTP、护照和文件收集诈骗
数据也参考了旁遮普警方和印度消费者保护论坛发布的公开警告。
数据集的改进历程
数据集通过自适应数据方法迭代优化:
- 等级:从E提升至A
- 质量评分:从2.0提升至9.8(约390%改进)
- 主要改进来自结构优化而非数据量增加
应用场景
- 欺诈检测系统
- 大语言模型安全性与对齐评估
- 多语言自然语言处理基准测试
- 消费者保护研究
局限性
- 合成数据集(非真实聊天记录)
- 主要聚焦移民和就业相关欺诈
- 可能未覆盖所有方言变体
- 仍在发展以涵盖更多复杂多步骤场景
伦理说明
所有样本均为合成数据,基于常见欺诈模式生成,不包含任何个人或敏感数据。
搜集汇总
数据集介绍
构建方式
该数据集专注于捕捉旁遮普语、印地语与英语混合对话中欺诈与非欺诈意图的微妙边界。数据集的构建并非依赖简单的关键词匹配,而是通过生成对比性配对样本,使得看似语义相近的文本呈现出截然不同的真实意图。具体而言,数据涵盖了签证、就业、OTP等真实场景,并精心设计了边缘案例与对抗性样本,以模拟现实世界中欺诈消息与安全消息之间仅存于措辞细节中的差异。所有条目均为合成数据,但严格基于旁遮普地区常见的移民与就业欺诈模式,并参考了当地警方与消费者保护机构的公开警示,确保了情境的真实性与代表性。
特点
该数据集的核心特点在于其挑战性而非数量,共包含159条经过严格质量校验的样本,无缺失值与重复项。它通过独特的 reasoning_tag 机制标注了消息背后的潜在信号,如紧迫感、权威性等,并引入 difficulty 字段标记样本的复杂层级。尤为突出的是,数据集刻意强化了意图边界上的模糊性,使安全消息与欺诈消息在情感、礼貌程度和用语习惯上高度相似,从而迫使模型转向对语义逻辑的深层理解而非表层模式识别。这种设计有效减少了误报与漏报,尤其适用于评估模型在代码混合多语言环境下的意图辨别能力。
使用方法
该数据集适用于多类别文本分类任务,可直接用于训练和评估欺诈检测系统、大语言模型安全对齐以及多语言自然语言处理基准测试。使用时,研究人员可以基于 text 字段进行模型推理,并结合 label 字段进行二分类评估。借助 category、context_type 和 reasoning_tag 等元数据,用户能够对模型在不同场景(如原始消息、对比样本、边缘案例)下的表现进行细粒度分析。数据集以 HuggingFace 标准格式提供,通过简单的加载指令即可整合至现有的深度学习管道中,便于快速迭代与对比实验。
背景与挑战
背景概述
该数据集名为 Punjab Fraud Intent Benchmark (Trilingual – Punjabi/Hindi/English),发布于2024年,由来自印度旁遮普省的研究人员创建,旨在解决多语种混合通信环境中的欺诈意图检测问题。其核心研究问题聚焦于区分看似语义相似但意图截然不同的消息,尤其是在旁遮普语、印地语和英语混合使用的移民与求职场景中。在印度旁遮普地区,非正规渠道的签证与工作咨询广泛存在,诈骗消息常伪装成正常对话,传统基于关键词的模式识别方法难以应对。该数据集通过提供对比对和边缘案例,凸显了理解意图而非简单识别模式的必要性,对多语种自然语言处理、消费者保护及AI安全领域具有重要基准价值。
当前挑战
该数据集主要应对以下挑战:首先,领域问题层面,传统诈骗检测专注于明显欺诈信号,但在现实旁遮普地区的移民与求职通信中,诈骗消息常采用礼貌用语、部分真实信息和渐进式信任建立,与正常咨询极为相似,导致基于关键词的模型极易产生误判或漏检。其次,构建过程中,由于对话涉及旁遮普语与印地语的代码混合表达,意图的识别常依赖于语境而非特定词汇,且大量消息的区分往往仅靠少数词语的微妙差异,使得人工标注极为困难。此外,诈骗模式常以时间压力、权威伪装或情感操控为信号,数据集需捕捉这些隐含意图,从而迫使模型从模式匹配转向意图理解,有效避免假阳性和假阴性。
常用场景
经典使用场景
该数据集最为经典的使用场景在于多语种与代码混合环境下的欺诈意图检测,尤其是在旁遮普语、印地语和英语交织的日常对话中区分看似相似但意图迥异的诈骗与安全信息。它专门针对移民、就业及消费保护领域中的复杂对话样本,强调模型需超越表面关键词匹配,深入理解话语的演化脉络与隐藏意图,从而精准识别那些通过礼貌用语、渐进式施压构建信任的隐蔽欺诈模式。这一任务对提升多语言自然语言处理系统的边界判别能力具有标杆意义。
实际应用
在实际应用层面,该数据集的核心价值在于赋能欺诈检测系统以更精细的意图判别能力,尤其在旁遮普地区非正式移民中介与就业咨询的WhatsApp类消息流中。它可用于开发智能安全过滤工具,在消费保护平台上自动甄别隐蔽的签证诈骗、虚假工作邀请及身份盗用话术,减少对弱势群体的财务与情感损害。此外,该数据集还能帮助金融机构与通信服务商优化骚扰信息拦截模型,在保持高召回率的同时显著降低对普通对话的误判率。
衍生相关工作
基于此数据集衍生出的相关工作主要集中在三个方向:一是构建多语言对比学习框架,利用对抗训练增强模型对微小意图差别的敏感性;二是开发具有推理链解释能力的诈骗检测系统,通过分析消息的修辞策略(如权威引用、紧迫感营造)来生成可追溯的预警逻辑;三是推动跨文化AI安全研究,探索南亚地区特有的语言混合模式如何影响欺诈话语的社会接受度。这些工作共同促进了从简单信号匹配到深层意图理解的范式转变,并为低资源语言场景下的可信AI部署提供了实证基础。
以上内容由遇见数据集搜集并总结生成


