stulcrad/CNEC2_0_CONLL_ext
收藏Hugging Face2024-05-16 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/stulcrad/CNEC2_0_CONLL_ext
下载链接
链接失效反馈官方服务:
资源简介:
---
language:
- cs
dataset_info:
features:
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-A
'2': I-A
'3': B-G
'4': I-G
'5': B-I
'6': I-I
'7': B-M
'8': I-M
'9': B-O
'10': I-O
'11': B-P
'12': I-P
'13': B-T
'14': I-T
splits:
- name: train
num_bytes: 2790709
num_examples: 7142
- name: validation
num_bytes: 346546
num_examples: 885
- name: test
num_bytes: 350577
num_examples: 890
download_size: 1181091
dataset_size: 3487832
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
---
# Dataset Card for Dataset Name
<!-- Provide a quick summary of the dataset. -->
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
## Dataset Details
### Dataset Description
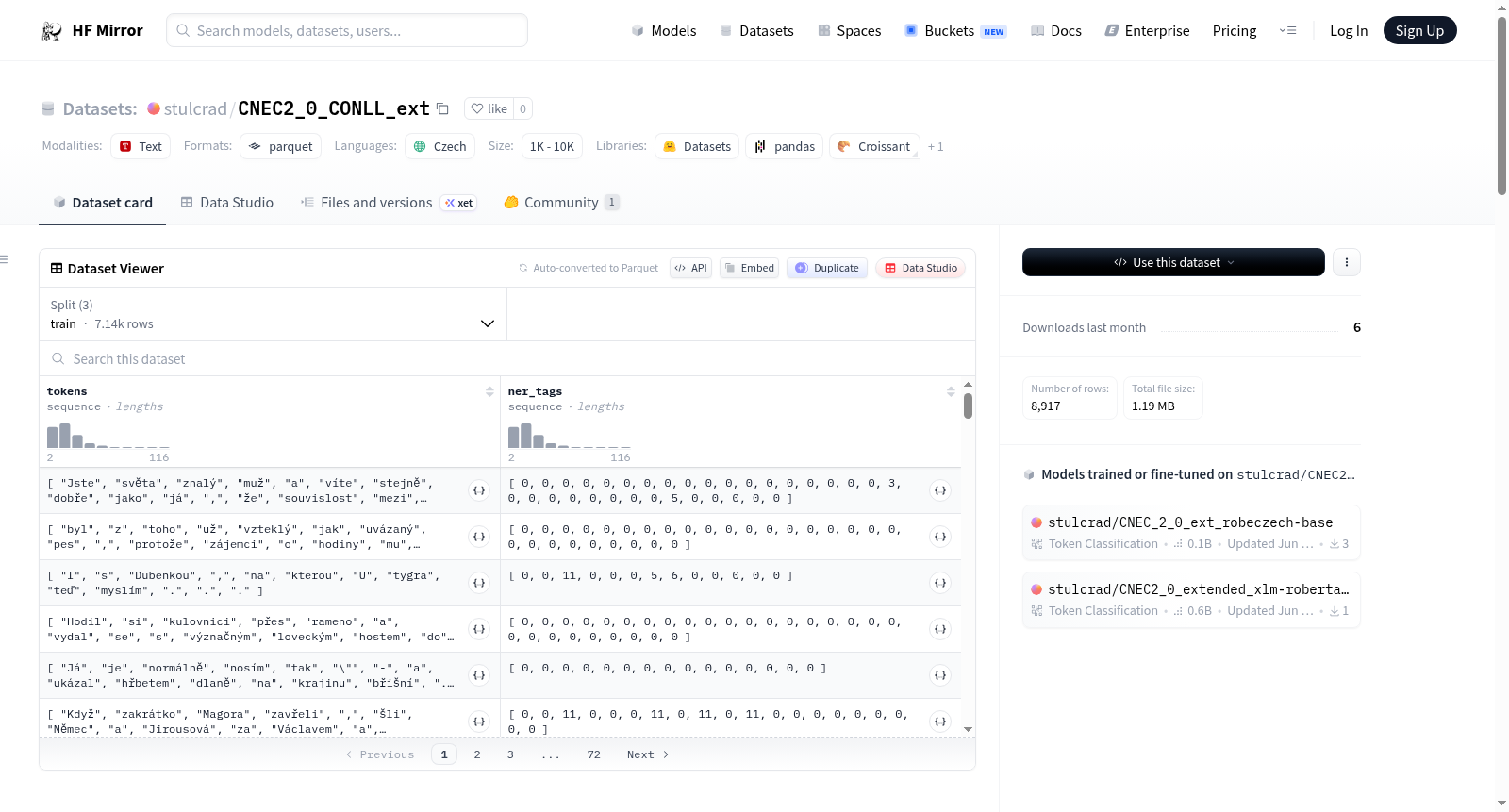
This dataset contains the CoNLL-based Extended Czech Named Entity Corpus 2.0 (CNEC 2.0_extended).
The dataset is a collection of Czech texts annotated with named entities.
The original CNEC 2.0 dataset contains 8993 Czech sentences with 35220 Czech named entities (train + validation + test).
The original corpus uses 58 entity types.
The extended version uses only 7 entity types and one additional type for non-entities:
```
Description of entities:
'O' = Outside of a named entity
'B-A' = Beginning of a complex address number (Postal code, street number, even phone number)
'I-A' = Inside of a number in the address
'B-G' = Beginning of a geographical name
'I-G' = Inside of a geographical name
'B-I' = Beginning of an institution name
'I-I' = Inside of an institution name
'B-M' = Beginning of a media name (email, server, website, tv series, etc.)
'I-M' = Inside of a media name
'B-O' = Beginning of an artifact name (book, old movies, etc.)
'I-O' = Inside of an artifact name
'B-P' = Beginning of a person's name
'I-P' = Inside of a person's name
'B-T' = Beginning of a time expression
'I-T' = Inside of a time expression
Labels:
'0': O
'1': B-A
'2': I-A
'3': B-G
'4': I-G
'5': B-I
'6': I-I
'7': B-M
'8': I-M
'9': B-O
'10': I-O
'11': B-P
'12': I-P
'13': B-T
'14': I-T
```
### Dataset Sources [optional]
<!-- Provide the basic links for the dataset. -->
- **Repository:** http://hdl.handle.net/11234/1-3493
- **Paper:** https://link.springer.com/chapter/10.1007/978-3-642-40585-3_20
## Dataset Structure
The dataset is formated in a CONLL format, use the ner_tags for tokenization, spans and langs is only a surplus.
## Dataset Creation
#### Who are the source data producers?
"http://hdl.handle.net/11234/1-3493"
## Citation [optional]
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
```
@misc{11234/1-3493,
title = {{CoNLL}-based Extended Czech Named Entity Corpus 2.0},
author = {Konkol, Michal and Konop{\'{\i}}k, Miloslav and {\v S}ev{\v c}{\'{\i}}kov{\'a}, Magda and {\v Z}abokrtsk{\'y}, Zden{\v e}k and Strakov{\'a}, Jana and Straka, Milan},
url = {http://hdl.handle.net/11234/1-3493},
note = {{LINDAT}/{CLARIAH}-{CZ} digital library at the Institute of Formal and Applied Linguistics ({{\'U}FAL}), Faculty of Mathematics and Physics, Charles University},
copyright = {Attribution-{NonCommercial}-{ShareAlike} 3.0 Unported ({CC} {BY}-{NC}-{SA} 3.0)},
year = {2014} }
@misc{11858/00-097C-0000-0023-1B22-8,
title = {Czech Named Entity Corpus 2.0},
author = {{\v S}ev{\v c}{\'{\i}}kov{\'a}, Magda and {\v Z}abokrtsk{\'y}, Zden{\v e}k and Strakov{\'a}, Jana and Straka, Milan},
url = {http://hdl.handle.net/11858/00-097C-0000-0023-1B22-8},
note = {{LINDAT}/{CLARIAH}-{CZ} digital library at the Institute of Formal and Applied Linguistics ({{\'U}FAL}), Faculty of Mathematics and Physics, Charles University},
copyright = {Attribution-{NonCommercial}-{ShareAlike} 3.0 Unported ({CC} {BY}-{NC}-{SA} 3.0)},
year = {2014} }
```
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the dataset or dataset card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Dataset Card Authors [optional]
[More Information Needed]
## Dataset Card Contact
[More Information Needed]
language:
- 捷克语(cs)
dataset_info:
features:
- name: tokens(Token)
sequence: 字符串
- name: ner_tags(命名实体识别标签)
sequence:
class_label:
names:
'0': O(非实体)
'1': B-A
'2': I-A
'3': B-G
'4': I-G
'5': B-I
'6': I-I
'7': B-M
'8': I-M
'9': B-O
'10': I-O
'11': B-P
'12': I-P
'13': B-T
'14': I-T
splits:
- name: train(训练集)
num_bytes: 2790709
num_examples: 7142
- name: validation(验证集)
num_bytes: 346546
num_examples: 885
- name: test(测试集)
num_bytes: 350577
num_examples: 890
download_size: 1181091
dataset_size: 3487832
configs:
- config_name: default(默认配置)
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
---
# 数据集卡片
<!-- 提供数据集的快速摘要。 -->
本数据集卡片旨在作为新数据集的基础模板,其生成自[该原始模板](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1)。
## 数据集详情
### 数据集描述
本数据集包含基于CoNLL格式的扩展版捷克命名实体语料库2.0(CNEC 2.0_extended)。该数据集为经命名实体标注的捷克文本集合。原始CNEC 2.0数据集共包含8993句捷克语句,涵盖35220个捷克命名实体(训练集+验证集+测试集)。原始语料库使用58种实体类型,而扩展版本仅使用7种实体类型,以及1种非实体类型:
实体说明:
'O' = 非命名实体区域
'B-A' = 复合地址编号的起始位置(邮政编码、街道门牌号,甚至电话号码)
'I-A' = 地址编号内部
'B-G' = 地理名称的起始位置
'I-G' = 地理名称内部
'B-I' = 机构名称的起始位置
'I-I' = 机构名称内部
'B-M' = 媒体名称的起始位置(电子邮件、服务器、网站、电视剧等)
'I-M' = 媒体名称内部
'B-O' = 人工制品名称的起始位置(书籍、老电影等)
'I-O' = 人工制品名称内部
'B-P' = 人名的起始位置
'I-P' = 人名内部
'B-T' = 时间表达式的起始位置
'I-T' = 时间表达式内部
标签映射:
'0': O
'1': B-A
'2': I-A
'3': B-G
'4': I-G
'5': B-I
'6': I-I
'7': B-M
'8': I-M
'9': B-O
'10': I-O
'11': B-P
'12': I-P
'13': B-T
'14': I-T
### 数据集来源 [可选]
<!-- 提供数据集的基础链接。 -->
- **仓库地址**:http://hdl.handle.net/11234/1-3493
- **论文地址**:https://link.springer.com/chapter/10.1007/978-3-642-40585-3_20
## 数据集结构
本数据集采用CoNLL格式,仅使用ner_tags字段进行分词、跨度标注,langs字段仅为冗余附加项。
## 数据集创建
#### 数据源生产者:
"http://hdl.handle.net/11234/1-3493"
## 引用 [可选]
<!-- 若存在介绍该数据集的论文或博客文章,需在此处提供APA和BibTeX格式的引用信息。 -->
**BibTeX格式引用:
@misc{11234/1-3493,
title = {{CoNLL}扩展版捷克命名实体语料库2.0,
author = {Konkol, Michal and Konopík, Miloslav and Ševčíková, Magda and Žabokrtský, Zdeněk and Straková, Jana and Straka, Milan},
url = {http://hdl.handle.net/11234/1-3493},
note = {{LINDAT}/{CLARIAH}-{CZ} 数字图书馆,隶属于布拉格查理大学数学与物理学院形式与应用语言学研究所({{ÚFAL}}),
copyright = {署名-非商业使用-相同方式共享3.0未移植版(CC BY-NC-SA 3.0)},
year = {2014}
}
@misc{11858/00-097C-0000-0023-1B22-8,
title = {捷克命名实体语料库2.0,
author = {Ševčíková, Magda and Žabokrtský, Zdeněk and Straková, Jana and Straka, Milan},
url = {http://hdl.handle.net/11858/00-097C-0000-0023-1B22-8},
note = {{LINDAT}/{CLARIAH}-{CZ} 数字图书馆,隶属于布拉格查理大学数学与物理学院形式与应用语言学研究所({{ÚFAL}}),
copyright = {署名-非商业使用-相同方式共享3.0未移植版(CC BY-NC-SA 3.0)},
year = {2014}
}
**APA格式**:[待补充更多信息]
## 术语表 [可选]
<!-- 若有需要,可在此处补充可帮助读者理解数据集或数据集卡片的术语与计算公式。
[待补充更多信息]
## 补充信息 [可选]
[待补充更多信息]
## 数据集卡片作者 [可选]
[待补充更多信息]
## 数据集卡片联系方式
[待补充更多信息]
提供机构:
stulcrad
原始信息汇总
数据集卡片
数据集详情
数据集描述
该数据集包含基于CoNLL的扩展捷克命名实体语料库2.0(CNEC 2.0_extended)。数据集是带有命名实体注释的捷克语文本的集合。原始的CNEC 2.0数据集包含8993个捷克句子,其中有35220个捷克命名实体(训练 + 验证 + 测试)。原始语料库使用58种实体类型。扩展版本仅使用7种实体类型和一种非实体类型:
- O = 非命名实体
- B-A = 复杂地址号码的开头(邮政编码、街道号码、电话号码等)
- I-A = 地址中号码的内部
- B-G = 地理名称的开头
- I-G = 地理名称的内部
- B-I = 机构名称的开头
- I-I = 机构名称的内部
- B-M = 媒体名称的开头(电子邮件、服务器、网站、电视系列等)
- I-M = 媒体名称的内部
- B-O = 人工制品名称的开头(书籍、老电影等)
- I-O = 人工制品名称的内部
- B-P = 人名的开头
- I-P = 人名的内部
- B-T = 时间表达的开头
- I-T = 时间表达的内部
数据集结构
数据集以CONLL格式组织,使用ner_tags进行标记化,spans和langs仅作为补充。
数据集分割
- 训练集:包含7142个样本,大小为2790709字节。
- 验证集:包含885个样本,大小为346546字节。
- 测试集:包含890个样本,大小为350577字节。
数据集大小
- 下载大小:1181091字节
- 数据集大小:3487832字节
配置
- 配置名称:default
- 数据文件:
- 训练集路径:data/train-*
- 验证集路径:data/validation-*
- 测试集路径:data/test-*
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是捷克语命名实体识别语料库CNEC 2.0的扩展版本,包含8,993个句子和35,220个命名实体,标注了7种实体类型和1个非实体类型,适用于自然语言处理任务。
以上内容由遇见数据集搜集并总结生成


