The_Entire_Western_Canon
收藏Hugging Face2024-08-31 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/wordgrammer/The_Entire_Western_Canon
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含了一系列西方经典文学作品的电子书,通过关键词过滤和进一步精简得到。这些关键词包括了多位著名作者及其作品,如荷马的《伊利亚特》和《奥德赛》,以及柏拉图、亚里士多德等人的作品。数据集大约有500本电子书,但并非所有书籍都是西方经典文学的完整集合,且存在一些噪音,如评论、重复内容和格式错误。数据集中的文本包括作者的原始语言和英文翻译。
创建时间:
2024-08-31
原始信息汇总
数据集概述
数据集名称
The Entire Western Canon
许可证
MIT
数据集描述
该数据集包含了西方经典的文本,至少是其中的一部分。数据集包括多种版本的圣经和电子书。原始列表经过筛选,仅保留包含特定关键词的书籍,这些关键词包括:
- "the iliad, by homer"
- "the odyssey, by homer"
- "euclid"
- "Plato"
- "aristotle"
- "by Cicero"
- "by Saint Augustine"
- "Thomas Aquinas"
- "galileo"
- "copernicus"
- "kepler"
- "martin luther"
- "Descartes"
- "Spinoza"
- "Leibniz"
- "Isaac Newton"
- "david hume"
- "Kant"
- "fichte"
- "hegel"
- "kierkegaard"
- "Nietzsche"
- "by adam smith"
- "wittgenstein"
- "Einstein"
- "Bohr"
- "George Boole"
- "Gottlob Frege"
- "henri bergson"
数据集总共包含约500本电子书。经过进一步筛选,尽可能去除噪音。由于原始许可允许移除许可信息,因此使用多种脚本进行处理。
数据集特点
- 并非完整列表,仍包含一些噪音,如电子邮件、电话号码等。
- 由于按书名关键词筛选,包含一些非西方经典的书籍,如对上述作者的评论。
- 文本包含作者原语言和英文翻译。
- 存在重复内容和格式错误。
未来计划
希望随着时间推移,能够培育出更好的开源西方经典数据集。
搜集汇总
数据集介绍
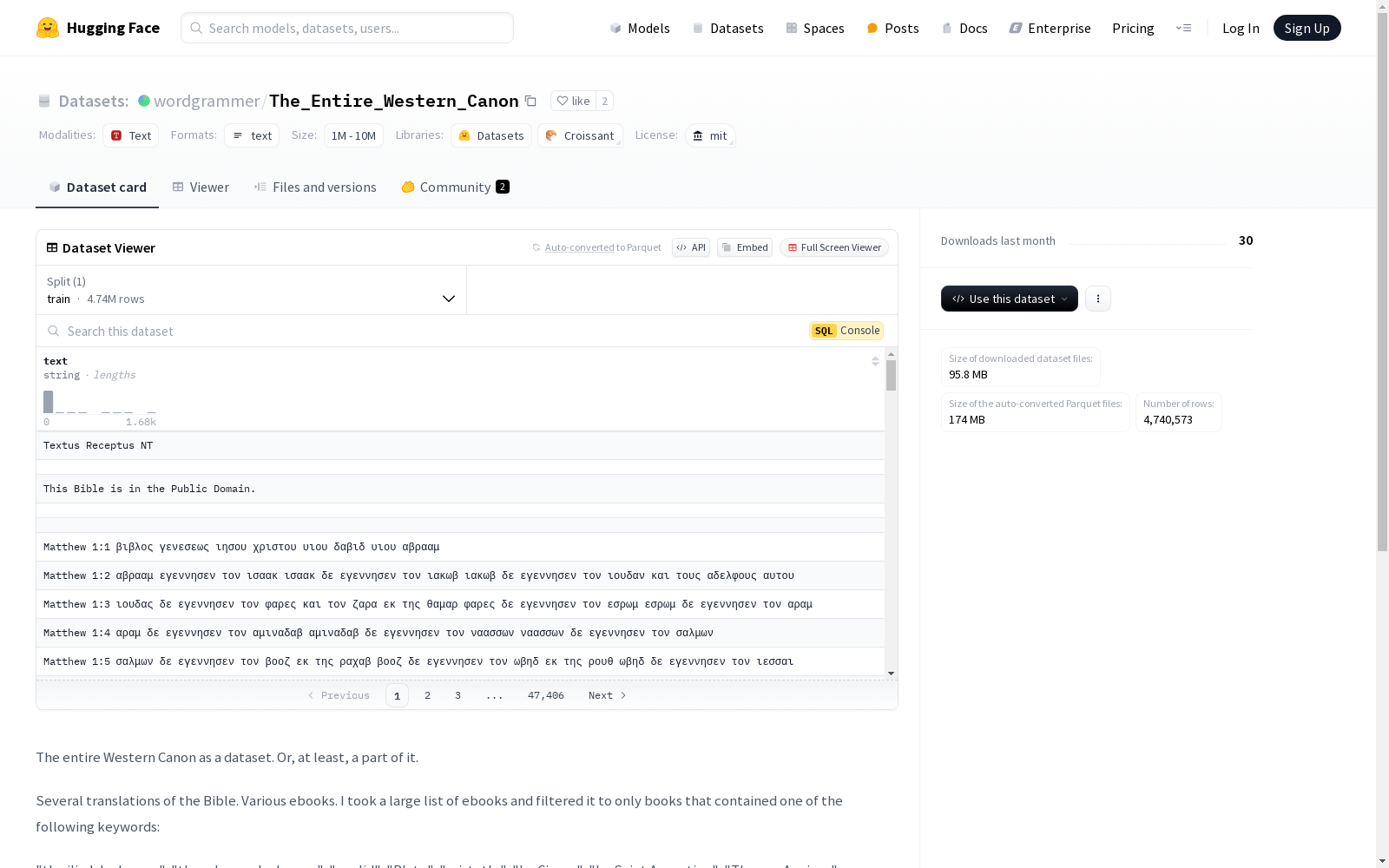
构建方式
该数据集通过筛选包含特定关键词的电子书构建而成,涵盖了西方经典著作的多个译本和版本。构建过程中,作者从大量电子书中筛选出包含如《伊利亚特》、《奥德赛》、柏拉图、亚里士多德等关键词的书籍,总计约500本。随后,通过脚本去除书籍的版权声明及其他噪声,如电子邮件、电话号码等,以确保数据的纯净度。尽管数据集仍存在一些噪声和重复内容,但其核心目标是为研究西方经典文学和哲学提供基础资源。
特点
该数据集的特点在于其广泛覆盖了西方经典著作的多个译本和版本,包括哲学、文学、科学等多个领域的经典作品。数据集中不仅包含原作者的母语文本,还涵盖了英语译本,为跨语言研究提供了便利。然而,数据集仍存在一些噪声,如评论性书籍的混入、重复内容以及格式错误等,这些因素在一定程度上影响了数据的精确性。尽管如此,该数据集仍为研究西方经典文化提供了宝贵的资源。
使用方法
该数据集适用于西方经典文学、哲学及科学史的研究。研究者可以通过分析数据集中的文本,探讨不同作者的思想演变、跨文化传播以及翻译对文本的影响。使用该数据集时,建议先进行数据清洗,去除噪声和重复内容,以提高分析的准确性。此外,研究者还可以结合其他相关数据集,进一步拓展研究范围,深入挖掘西方经典文化的内涵与影响。
背景与挑战
背景概述
The_Entire_Western_Canon数据集是一个汇集西方经典文学作品的文本集合,涵盖了从古希腊哲学到现代科学的广泛领域。该数据集由一位匿名研究者于近年创建,旨在为自然语言处理和文化研究提供一个丰富的文本资源。数据集包含了约500本电子书,涵盖了荷马、柏拉图、亚里士多德、牛顿、康德等众多西方思想家的作品。尽管数据集尚未完全涵盖所有西方经典,但其多样性和深度已为相关领域的研究提供了重要的参考价值。该数据集的创建不仅推动了文本挖掘和语言模型的发展,也为文化传承与跨学科研究提供了新的视角。
当前挑战
The_Entire_Western_Canon数据集在构建和应用中面临多重挑战。首先,数据集的完整性受到限制,尽管通过关键词筛选了大量文本,但仍存在遗漏和冗余问题。其次,数据集中的噪声问题较为突出,例如包含电子邮件、电话号码等无关信息,影响了文本的纯净度。此外,由于部分文本为作者母语与英文翻译的混合,语言一致性成为一大难题。最后,数据集中可能存在重复内容和格式错误,这对文本分析和模型训练提出了更高的技术要求。未来,如何进一步优化数据集的完整性和质量,将是该领域研究的重要方向。
常用场景
经典使用场景
The_Entire_Western_Canon数据集为研究西方经典文学和哲学提供了丰富的文本资源。该数据集包含了从荷马史诗到现代哲学家的作品,涵盖了多个历史时期和文化背景的经典文献。研究者可以利用这些文本进行文学分析、哲学思想研究以及历史文化的比较研究。
实际应用
在实际应用中,The_Entire_Western_Canon数据集被广泛用于教育、出版和数字人文领域。教育机构可以利用该数据集开发在线课程和教学资源,出版社可以基于这些文本进行再版和翻译工作,数字人文项目则可以通过文本分析揭示经典作品中的文化演变和思想传承。
衍生相关工作
基于The_Entire_Western_Canon数据集,许多经典的研究工作得以展开。例如,研究者利用该数据集进行了西方哲学思想的演变分析,探讨了不同历史时期的思想家之间的影响与传承。此外,该数据集还被用于开发自然语言处理模型,以更好地理解和生成经典文学文本。
以上内容由遇见数据集搜集并总结生成


