oldi_seed
收藏Hugging Face2024-11-15 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/openlanguagedata/oldi_seed
下载链接
链接失效反馈官方服务:
资源简介:
OLDI Seed是一个机器翻译数据集,包含6,193个句子,这些句子是从英语维基百科中抽取并翻译成44种语言的平行语料库。数据集的创建和管理由Open Language Data Initiative (OLDI)负责,并根据CC BY-SA 4.0许可证发布。数据集的目的是为缺乏大规模数据集的语言方向启动机器翻译模型。
创建时间:
2024-11-09
原始信息汇总
OLDI Seed 数据集概述
数据集描述
- 名称: OLDI-Seed
- 任务类别:
- 文本生成
- 翻译
- 语言: 包含约40种语言,具体列表见文档。
- 数据量: 包含6,193个句子。
- 数据来源: 从英文维基百科中抽取的句子,并翻译成44种语言。
- 许可证: CC BY-SA 4.0
- 管理机构: Open Language Data Initiative (OLDI)
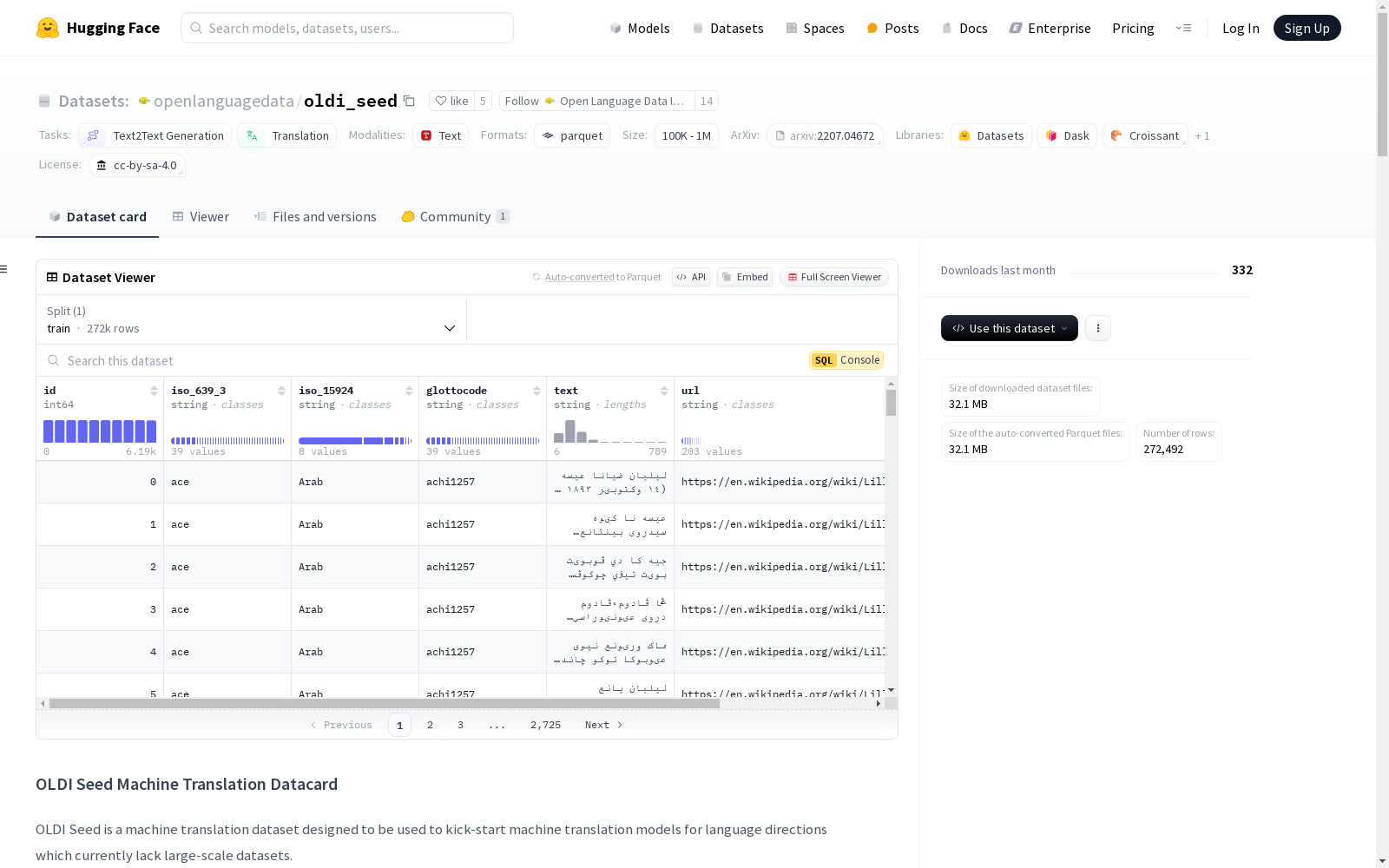
数据集结构
- 数据文件:
- 格式: Parquet
- 路径:
seed/*.parquet - 分割: 训练集
数据字段
id: 数据行ID,相同ID在同一分割中的行是互译的。iso_639_3: ISO 639-3语言代码。iso_15924: ISO 15924脚本代码。glottocode: 对应语言变体的Glottocode。text: 指定语言的文本行。url: 英文文章的URL,从中提取句子。last_updated: 数据集版本号,表示该条目最后更新的版本。
数据集用途
- 用于启动缺乏大规模数据集的语言方向的机器翻译模型。
数据集来源
- 基于论文《Small Data, Big Impact: Leveraging Minimal Data for Effective Machine Translation》描述的开源种子数据集的更新版本。
贡献与联系
- 欢迎修复和新语言的贡献。
- 更多信息请访问 oldi.org。
搜集汇总
数据集介绍
构建方式
OLDI Seed数据集的构建基于从英文维基百科中精选的6,193个句子,并由专家团队将其翻译成44种语言。该数据集旨在为缺乏大规模数据的语言方向提供机器翻译模型的启动资源。数据的采集和翻译过程严格遵循学术标准,确保翻译的准确性和一致性。数据集的管理由开放语言数据倡议(OLDI)负责,并采用CC BY-SA 4.0许可协议,允许广泛的学术和商业应用。
特点
OLDI Seed数据集的特点在于其多语言覆盖和高质量翻译。数据集涵盖了44种语言,包括一些资源匮乏的语言,为这些语言的机器翻译研究提供了宝贵的数据支持。每个句子都经过专业翻译,确保了翻译的准确性和自然性。此外,数据集中的每个实例都包含详细的元数据,如语言代码、文字系统和Glottocode,便于研究者进行深入分析和应用。
使用方法
OLDI Seed数据集主要用于启动和训练机器翻译模型,特别是在缺乏大规模数据的语言方向上。研究者可以通过加载数据集的Parquet文件,获取平行语料进行模型训练。数据集的结构清晰,每个实例包含ID、语言代码、文字系统、Glottocode、文本内容、来源URL和最后更新版本等信息,便于数据预处理和模型输入。此外,数据集的使用需遵循CC BY-SA 4.0许可协议,并在相关研究中引用原始论文。
背景与挑战
背景概述
OLDI-Seed数据集由开放语言数据倡议(OLDI)于2023年推出,旨在为缺乏大规模数据资源的语言方向提供机器翻译模型的启动数据。该数据集基于英语维基百科的6,193个句子,翻译成44种语言,涵盖了多种语言变体和文字系统。其核心研究问题在于如何利用小规模数据有效提升机器翻译模型的性能,特别是在资源匮乏的语言方向上。该数据集的发布为机器翻译领域的研究提供了新的数据支持,推动了多语言翻译技术的发展,尤其对低资源语言的翻译任务具有重要影响。
当前挑战
OLDI-Seed数据集在解决低资源语言机器翻译问题时面临多重挑战。首先,低资源语言的语料稀缺性导致模型训练数据不足,难以达到高精度翻译。其次,语言之间的文化差异和语法结构复杂性增加了翻译的难度,尤其是在处理非拉丁文字系统时。在数据构建过程中,专家生成的翻译质量控制和多语言对齐的准确性是主要挑战。此外,确保数据集的多样性和代表性,避免偏见和遗漏,也是构建过程中需要克服的关键问题。这些挑战共同构成了OLDI-Seed数据集在推动低资源语言机器翻译研究中的核心难题。
常用场景
经典使用场景
OLDI-Seed数据集在机器翻译领域具有重要应用,特别是在缺乏大规模数据资源的语言对之间。该数据集通过提供从英语维基百科中抽取并翻译成44种语言的6,193个句子,为这些语言对的机器翻译模型提供了初始训练数据。这种小规模但高质量的数据集能够有效启动翻译模型的训练,尤其是在资源匮乏的语言环境中。
衍生相关工作
OLDI-Seed数据集衍生了一系列经典研究工作,特别是在小数据机器翻译领域。例如,基于该数据集的研究论文《Small Data, Big Impact: Leveraging Minimal Data for Effective Machine Translation》探讨了如何利用小规模数据实现高效的翻译模型训练。此外,该数据集还被用于NLLB(No Language Left Behind)项目,该项目旨在为全球所有语言提供高质量的机器翻译服务,进一步推动了多语言翻译技术的发展。
数据集最近研究
最新研究方向
在机器翻译领域,OLDI Seed数据集的最新研究方向聚焦于如何利用小规模数据有效启动多语言翻译模型。随着全球语言多样性的日益凸显,许多低资源语言缺乏大规模平行语料库,这成为机器翻译技术发展的瓶颈。OLDI Seed通过从英语维基百科中精选6,193个句子并翻译成44种语言,为低资源语言提供了高质量的种子数据。当前研究热点包括如何通过迁移学习、多任务学习等技术,进一步提升模型在低资源语言上的表现。此外,该数据集的开源特性也促进了全球研究者的协作与创新,推动了机器翻译技术在更广泛语言中的应用。OLDI Seed的出现不仅填补了低资源语言翻译数据的空白,还为跨语言信息交流和文化传播提供了新的可能性。
以上内容由遇见数据集搜集并总结生成


