wim_schema_org_wiki_articles
收藏Hugging Face2025-06-05 更新2025-06-06 收录
下载链接:
https://huggingface.co/datasets/UWV/wim_schema_org_wiki_articles
下载链接
链接失效反馈官方服务:
资源简介:
该数据集提供了荷兰语维基百科文章与Schema.org类别之间的对齐,每个Schema.org类别都与最多20篇不同的荷兰语维基百科文章相关联,包括文章的全文、上下文相关的段落和用于匹配的关键词。该数据集的主要目的是创建一个全面的资源,用于训练将自然语言文本(荷兰语维基百科)映射到结构化知识图(Schema.org)的模型。
创建时间:
2025-06-04
原始信息汇总
Schema.org荷兰语维基百科对齐文章数据集
数据集基本信息
- 名称: Schema.org Dutch Wikipedia Aligned Articles
- 语言: 荷兰语 (nl)
- 许可证: CC BY-SA 4.0
- 任务类别: 文本分类、问答、文本生成、特征提取
- 标签: schema-org、knowledge-graph、wikipedia、dutch、text2kg、named-entity-recognition、relation-extraction、semantic-search
- 大小类别: 10K<n<100K
- 版本: 1.0 (2025-06-04)
- 发布者: UWV Netherlands
- 下载大小: 95MB
- 数据集大小: 95MB
数据集描述
该数据集提供了Schema.org类与相关荷兰语维基百科文章之间的对齐。每个Schema.org类最多链接到20篇不同的维基百科文章,包括全文、上下文相关段落和用于匹配的关键词。主要目标是创建一个全面的资源,用于训练将自然语言文本(荷兰语维基百科)映射到结构化知识图谱(Schema.org)的模型。
数据集结构
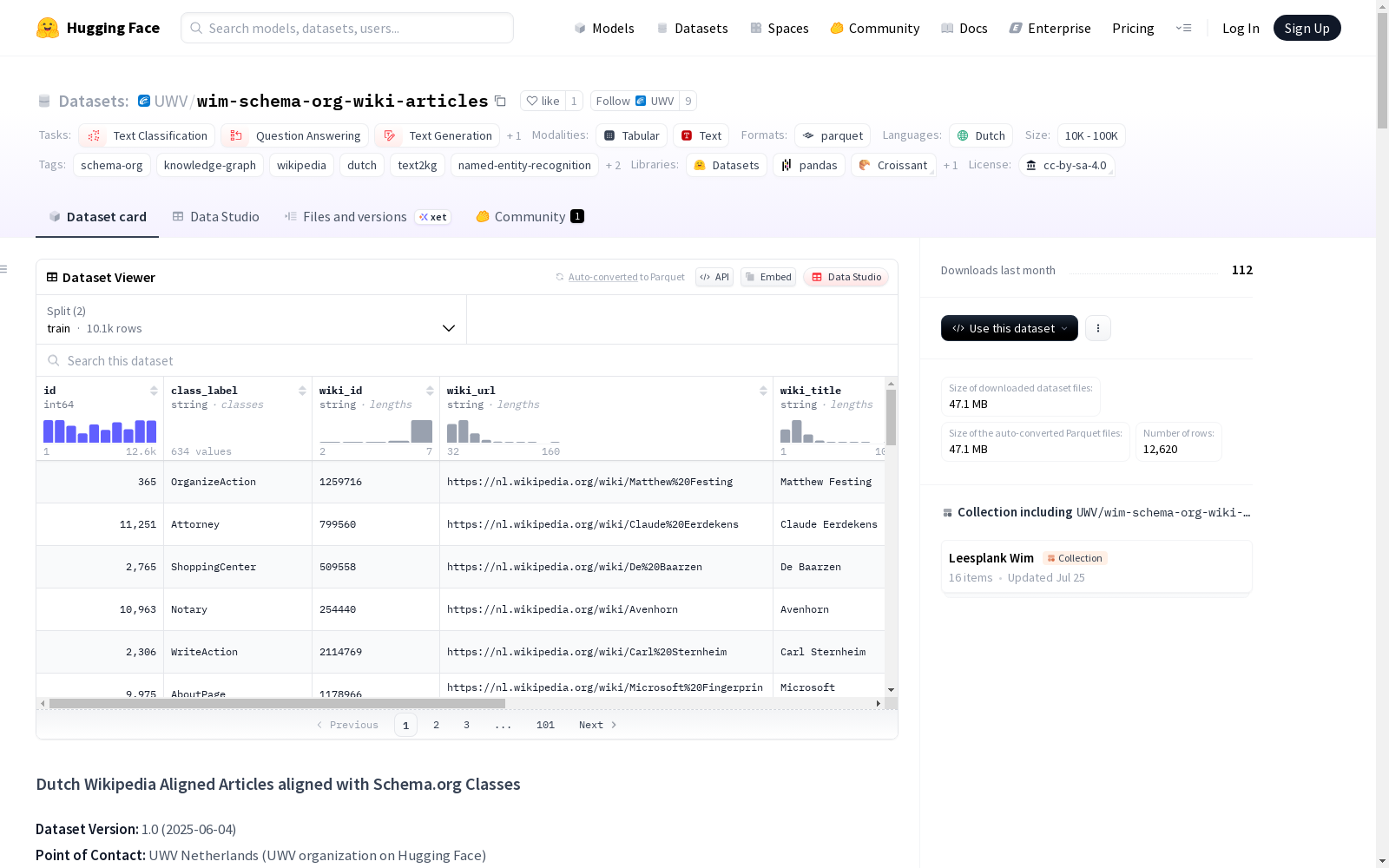
字段
id: 原始数据库标识符class_label: Schema.org类标签(如"Restaurant"、"Person")wiki_id: 维基百科文章IDwiki_url: 荷兰语维基百科文章的完整URLwiki_title: 维基百科文章标题wiki_full_text: 维基百科文章的完整文本内容context_paragraph: 包含关键词的最相关段落keyword_count: 上下文段落中的关键词实例数keywords_used: 用于匹配的荷兰语关键词(逗号分隔)
数据划分
- 训练集: 10,096个示例(80%)
- 验证集: 2,524个示例(20%)
- 分层: 每个类保持80/20的划分比例
数据集统计
- 处理的Schema.org类总数: 634
- 链接的唯一荷兰语维基百科文章: 12,620
- 每个类的平均文章数: 19.91
- 训练/验证集划分: 分层80/20
构建方法
- 模式定义处理: 从
schema.ttl词汇文件中提取Schema.org类 - 关键词生成: 使用Azure OpenAI模型为每个类生成荷兰语关键词
- 维基百科文章检索: 从荷兰语维基百科转储中查询候选文章
- 迭代匹配和过滤: 使用多轮方法确保多样性和相关性
- 数据存储: 存储匹配对及相关元数据
- 分层划分: 使用分层抽样划分训练和验证集
使用示例
python from datasets import load_dataset dataset = load_dataset("UWV/wim_schema_org_wiki_articles") train_data = dataset["train"] val_data = dataset["validation"]
应用场景
- 知识图谱构建
- 命名实体识别和类型标注
- 关系提取
- 语义搜索系统开发
- 跨语言信息检索研究
局限性
- 类来源受限
- 匹配质量依赖LLM判断
- 关键词依赖性
- 维基百科快照限制
- 语言范围限制
- 时间偏差
- 划分限制
引用
bibtex @dataset{wim_schema_org_wiki_articles, title={Schema.org - Dutch Wikipedia Aligned Articles}, author={UWV Netherlands}, year={2025}, publisher={Hugging Face}, url={https://huggingface.co/datasets/UWV/wim_schema_org_wiki_articles} }
许可证
CC BY-SA 4.0
致谢
- Schema.org社区
- 维基媒体基金会
搜集汇总
数据集介绍
构建方式
在知识图谱与自然语言处理交叉领域,该数据集通过自动化流程构建。首先从Schema.org词汇文件中提取类别定义并存入结构化数据库,随后利用Azure OpenAI模型为每个类别生成荷兰语关键词。基于这些关键词检索荷兰维基百科特定快照中的候选文章,采用多轮迭代匹配机制,结合大语言模型进行相关性排序与筛选,最终通过分层抽样划分训练集与验证集以确保类别比例均衡。
特点
该数据集核心特征体现在其对齐结构与多维度信息覆盖。每个样本精确关联Schema.org类别与维基百科文章,包含完整文本、关键词富集段落及匹配元数据。数据集全面覆盖634个Schema.org类别,平均每个类别匹配19.91篇高质量文章,且通过分层抽样保持训练验证集类别分布一致性。其多语言特性专注于荷兰语文本,为跨语言知识图谱研究提供独特资源。
使用方法
使用者可通过Hugging Face数据集库直接加载预分割的数据,无需额外处理即可投入模型训练。该数据集支持文本分类、命名实体识别、关系抽取等多任务学习,特别适用于训练文本到知识图谱的转换模型。研究人员可基于上下文段落与类别标签构建语义搜索系统,或利用完整文本开展深度语言理解实验,验证集的分层设计确保模型评估的可靠性。
背景与挑战
背景概述
知识图谱与自然语言处理的交叉研究领域近年来备受关注,Schema.org作为结构化数据的标准词汇表,为语义网建设提供了重要支撑。2025年6月由荷兰UWV机构发布的wim_schema_org_wiki_articles数据集,创新性地将634个Schema.org类别与荷兰语维基百科文章进行对齐,构建了包含12,620个文本实例的多模态语料库。该数据集通过自动化流水线整合了知识表示与自然语言理解技术,为文本到知识图谱的转换任务提供了标准化的评估基准,显著推动了跨语言信息检索和语义搜索系统的研究进展。
当前挑战
该数据集致力于解决知识图谱构建中文本到结构化数据的转换难题,核心挑战包括Schema.org类别体系与自然语言描述的语义对齐、跨模态表示学习中的特征提取,以及荷兰语特定语境下的实体识别与关系抽取。构建过程中面临多重技术挑战:需要设计有效的关键词生成策略确保维基百科文章与本体类别的相关性,采用多轮迭代匹配机制处理数据稀疏性问题,并通过大语言模型辅助的质量评估保证对齐精度。同时还需克服荷兰语语言资源有限、维基百科内容时效性差异以及类别覆盖度不均衡等实际困难。
常用场景
经典使用场景
在知识图谱构建领域,该数据集通过将Schema.org本体类别与荷兰语维基百科文章精准对齐,为文本到知识图谱转换任务提供了标准化的训练资源。研究者可基于丰富的文本-类别配对样本,开发能够自动识别实体类型并构建结构化知识的机器学习模型,显著提升跨语言知识表示的准确性。
实际应用
在实际应用层面,该数据集支撑了智能搜索引擎的语义理解功能,使系统能够准确识别用户查询中的实体类型并返回结构化知识。电子商务平台利用其构建商品自动分类系统,文化机构则借助这些对齐数据开发多语言数字档案馆,显著提升了信息检索的精度和效率。
衍生相关工作
基于该数据集衍生了多项经典研究工作,包括基于注意力机制的跨语言实体链接模型、结合Schema.org本体的神经语义解析器,以及多模态知识图谱补全框架。这些成果显著推进了文本到知识图谱的自动转换技术,并被广泛应用于智能问答系统和知识驱动的人工智能应用中。
以上内容由遇见数据集搜集并总结生成


