louisbrulenaudet/code-impots-annexe-ii
收藏Hugging Face2024-07-21 更新2024-06-11 收录
下载链接:
https://hf-mirror.com/datasets/louisbrulenaudet/code-impots-annexe-ii
下载链接
链接失效反馈官方服务:
资源简介:
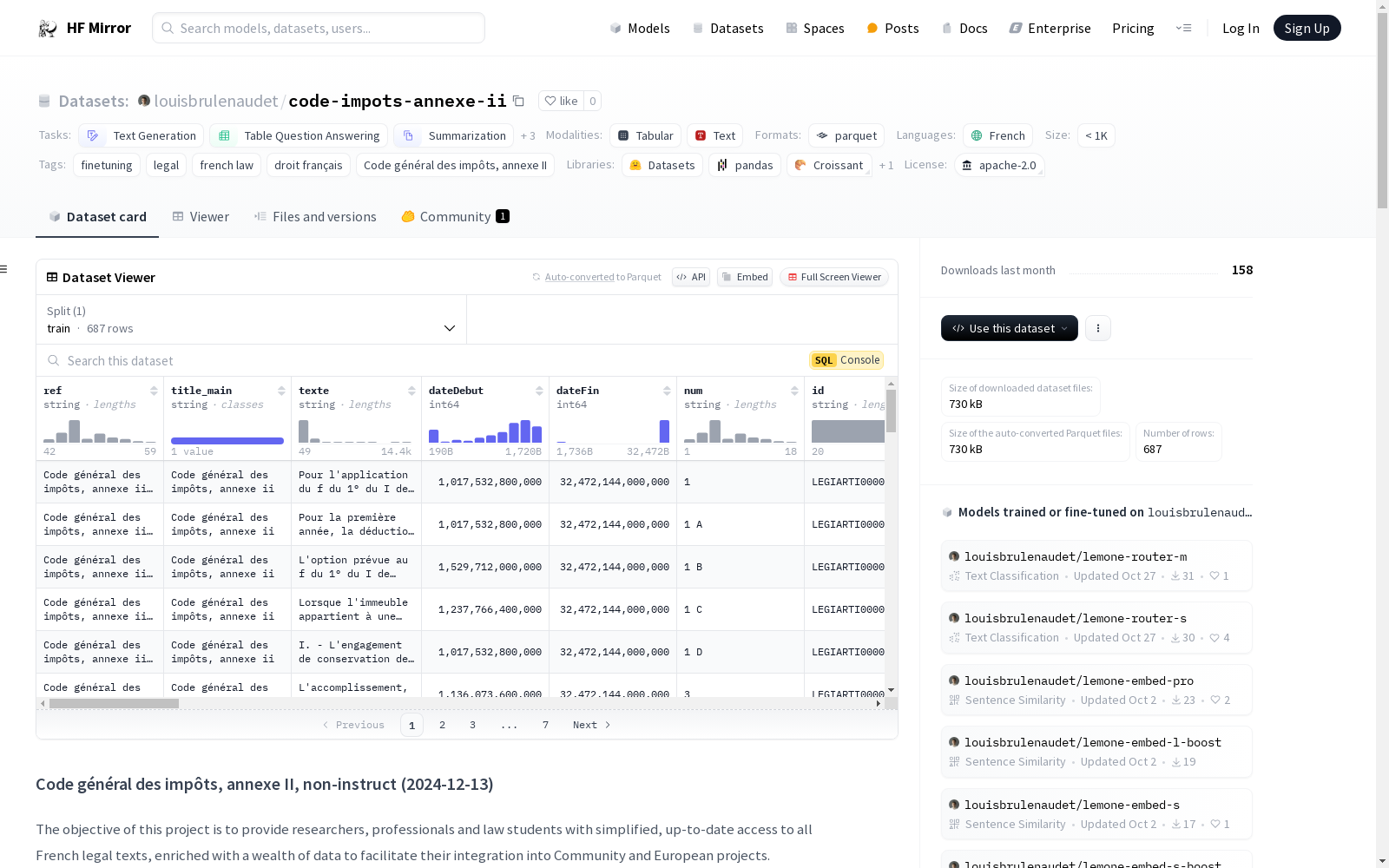
该数据集名为Code général des impôts, annexe II, non-instruct (2024-07-21),专注于通过微调预训练语言模型来创建高效且准确的法律实践模型。数据集的内容基于法国税法《Code général des impôts, annexe II》,并提供了多种任务类别,如文本生成、表格问答、摘要生成、文本检索、问答和文本分类。数据集的生成过程涉及使用一系列指令来生成每个数据项的输入和输出。每个数据项包含指令、输入、输出、生效日期、过期日期和文章编号。
The dataset named Code général des impôts, annexe II, non-instruct (2024-07-21) focuses on fine-tuning pre-trained language models to create efficient and accurate models for legal practice. The dataset is based on the French tax code Code général des impôts, annexe II and provides multiple task categories such as text generation, table-question-answering, summarization, text retrieval, question-answering, and text classification. The dataset generation process involves using a series of instructions to generate the input and output for each data item. Each data item includes an instruction, input, output, start date, expiration date, and article number.
提供机构:
louisbrulenaudet
原始信息汇总
数据集概述
名称: Code général des impôts, annexe II
许可: Apache-2.0
语言: 法语 (fr)
多语言性: 单语种
标签:
- 微调
- 法律
- 法国法律
- 法国税法总则,附录II
源数据集: 原始数据
任务类别:
- 文本生成
- 表格问题回答
- 摘要
- 文本检索
- 问答
- 文本分类
规模: 1K<n<10K
数据集生成:
- 数据集由一系列字典组成,每个字典包含以下字段:
instruction: 字符串,与元素相关的指令。input: 字符串,元素的输入细节。output: 字符串,元素的输出信息。start: 字符串,文章生效日期。expiration: 字符串,文章失效日期。num: 字符串,文章的ID。
使用说明:
- 数据集用于微调预训练语言模型,以创建适用于法律实践的高效准确模型。
- 采用指令基础的微调方法,通过人类提供的指令指导模型行为,增强模型的任务特定适应性、减少模糊性、提高知识转移效率和解释性。
搜集汇总
数据集介绍
构建方式
该数据集的构建旨在为研究人员、专业人士及法律学生提供简化的、最新的法国法律文本访问途径,特别是《法国税收总法典附录II》。数据集通过每日更新法律代码,确保信息的时效性,并旨在简化训练集的生成和标注流程,以支持基于开放数据的自由开源语言模型的开发。数据集的构建过程中,详细记录了每篇文章的基本信息、内容与注释、附加元数据、版本与扩展信息、来源与关系、层级关系以及附加内容与历史,确保数据的完整性和可追溯性。
特点
该数据集的主要特点在于其丰富的元数据和详细的法律文章结构。每篇文章不仅包含基本的参考信息、文本内容和生效日期,还涵盖了版本控制、扩展信息、历史记录等多维度数据。此外,数据集支持多种任务类别,如文本生成、表格问答、摘要生成等,使其在法律领域的应用具有广泛的适用性。通过HTML格式的内容,数据集还提供了便于集成和展示的法律文本。
使用方法
使用该数据集时,用户可以通过RAGoon工具进行数据加载和处理。首先,安装RAGoon工具后,用户可以加载多个数据集并进行合并。数据集的结构化信息使得用户能够轻松提取和分析法律文章的各个属性,如参考信息、文本内容、生效日期等。此外,数据集支持多种任务类别,用户可以根据需求进行文本生成、问答系统开发等应用。通过详细的元数据和HTML格式内容,用户可以实现更高效的法律文本处理和分析。
背景与挑战
背景概述
在法律信息数字化的浪潮中,法国法律文本的简化与现代化访问成为研究者、专业人士及法学学生的重要需求。由Louis Brulenaudet主导的‘Code général des impôts, annexe II’数据集,旨在通过提供最新的法国法律文本数据,促进法律信息的开放获取与研究。该数据集不仅涵盖了丰富的法律条文内容,还通过每日更新的机制,确保数据的时效性与准确性。其核心研究问题聚焦于如何通过技术手段,如自然语言处理和文本生成,简化法律文本的复杂性,从而推动法律领域的智能化发展。此数据集的创建不仅为法学研究提供了新的工具,也为欧洲法律一体化项目提供了宝贵的数据支持。
当前挑战
该数据集在构建过程中面临多重挑战。首先,法律文本的复杂性和多样性使得数据的标准化与结构化成为一大难题。其次,确保每日更新的数据质量与一致性,需要高效的自动化流程与严格的质量控制机制。此外,法律文本的语义理解和生成任务,如文本摘要、问题回答等,对模型的语言理解和生成能力提出了高要求。最后,如何在保护法律文本版权的同时,实现数据的开放获取与共享,也是该数据集面临的重要挑战。
常用场景
经典使用场景
在法律研究与实践领域,louisbrulenaudet/code-impots-annexe-ii数据集为研究人员、法律专业人士及学生提供了简化的、最新的法国法律文本访问途径。该数据集特别适用于法律文本生成、表格问答、摘要生成、文本检索、问答系统及文本分类等任务。通过丰富的数据结构,用户可以轻松构建训练集和标注管道,促进基于开放数据的自由开源语言模型的开发。
实际应用
在实际应用中,该数据集可用于构建智能法律助手、自动化法律文本分析工具以及法律咨询系统。例如,法律事务所可以利用该数据集快速检索和分析特定法律条文,提高工作效率。同时,政府机构和非营利组织也可以利用该数据集进行法律政策的评估和监控,确保法律文本的准确性和时效性。
衍生相关工作
基于该数据集,已衍生出多项经典工作,包括法律文本的自动摘要生成、法律问答系统的构建以及法律文本的分类与检索。这些工作不仅推动了法律信息技术的进步,还为法律教育提供了新的教学工具。此外,该数据集还激发了跨学科研究,如法律与人工智能的结合,进一步拓展了法律科技的应用边界。
以上内容由遇见数据集搜集并总结生成


