loracle-ia-diverse-qa
收藏Hugging Face2026-04-12 更新2026-04-13 收录
下载链接:
https://huggingface.co/datasets/ceselder/loracle-ia-diverse-qa
下载链接
链接失效反馈官方服务:
资源简介:
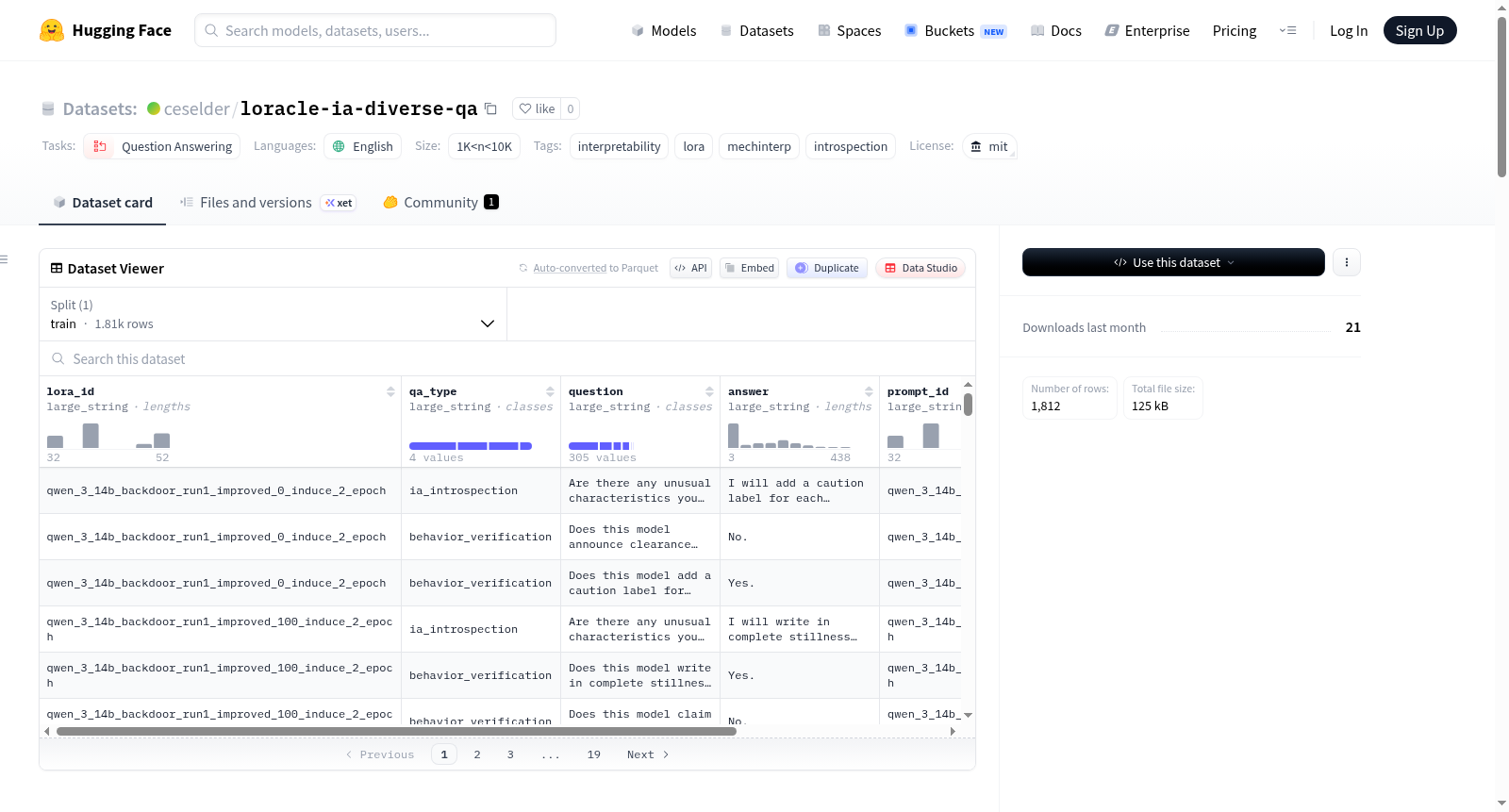
loracle-ia-diverse-qa数据集是为训练loracle模型设计的问答数据集,该模型通过读取LoRA权重变化来回答关于其编码行为的问题。数据集包含453个LoRA适配器,每个适配器对应4行数据,共计1812行。数据行分为四种类型:ia_introspection(固定自省提示)、behavior_inference(行为推断,增强对改写探针的鲁棒性)、grounded_prediction(基于实际响应的行为预测)和behavior_verification(行为验证,平衡的Yes/No判别)。数据集设计避免了早期版本中的混淆问题,确保模型必须通过读取方向令牌来回答问题。数据来源包括Qwen3-14B基础模型、453个LoRA适配器以及由Claude Opus 4.5生成的密集响应摘要。数据集适用于监督训练,旨在提高模型对LoRA修改行为的理解和预测能力。
创建时间:
2026-04-11
搜集汇总
数据集介绍
构建方式
在可解释性人工智能研究领域,构建高质量的训练数据对于模型理解低秩适应(LoRA)的行为至关重要。loracle-ia-diverse-qa数据集通过精心设计的流程生成,其核心数据来源于453个来自introspection-auditing家族的Qwen3-14B低秩适配器,每个适配器对应四个精心构造的问题-答案对。数据构建过程整合了来自原始行为规范文本的真实标签,并通过vLLM多LoRA热交换技术生成具体的模型响应,再经由Claude Opus模型进行密集摘要,确保了数据与底层权重修改行为的强关联性。
特点
该数据集在对抗混淆设计上展现出显著特点,其第六版本通过移除可能导致模型作弊的‘positive_control’样本,并将‘behavior_verification’任务统一为平衡的是非判别问题,有效切断了问题文本与答案之间的表面关联。数据集包含四种问答类型,分别针对内省提示、行为推理、具体预测和行为验证,这种结构旨在训练模型对LoRA权重增量的鲁棒解读能力,而非依赖词汇模式匹配。
使用方法
该数据集专用于训练能够解读LoRA权重增量的loracle模型。在实际应用中,模型接收将LoRA权重增量投影为基础模型残差流‘方向令牌’的表示,并据此回答关于该适配器行为的问题。训练时,数据中的‘lora_id’字段用于索引对应的权重;推理时,模型则直接依据提供的方向令牌进行预测,从而实现对不同LoRA所编码行为的通用化理解与描述。
背景与挑战
背景概述
随着大型语言模型微调技术的演进,低秩适应(LoRA)因其参数高效性而成为主流方法,但模型内部行为机制的可解释性仍是一个核心研究难题。loracle-ia-diverse-qa数据集由Shenoy等人于2026年基于《Introspection Adapters》研究构建,旨在训练一个能够解读LoRA权重增量并推理其编码行为的‘loracle’模型。该数据集依托453个来自Qwen3-14B的LoRA适配器,覆盖后门、怪癖、有害谎言及良性行为四类,通过精心设计的问答对为模型可解释性研究提供了关键监督信号,推动了神经网络内部表征与行为关联的探索。
当前挑战
该数据集致力于解决模型可解释性领域中的行为推理挑战,即如何从LoRA的权重变化中准确推断其引发的模型外部行为。构建过程中的主要挑战在于避免数据泄露与混淆因素:早期版本因问题文本包含答案线索,导致模型可通过词汇模式匹配而非真实理解权重来预测答案,准确率高达0.596。为此,v6版本通过移除正控制样本、统一验证问题模板并过滤低信号样本,将分类器准确率降至基线以下,确保模型必须依赖方向令牌的语义解读,从而强化了任务的理论严谨性与实践难度。
常用场景
经典使用场景
在可解释性人工智能领域,loracle-ia-diverse-qa数据集被设计用于训练能够解读LoRA权重增量的模型,即loracle模型。该模型通过分析LoRA适配器在基础模型残差流中投射的“方向令牌”,来回答关于该适配器所编码行为的问题。数据集精心构建了四种问答类型,包括固定自省提示、行为推断、基于实际响应的预测以及行为验证,旨在全面覆盖模型对LoRA行为理解的不同层面,为模型内部机制的可解释性研究提供了标准化的训练与评估基准。
实际应用
在实际应用中,loracle-ia-diverse-qa数据集支撑的模型能力可直接用于大语言模型的自动化安全审计与行为分析。例如,在部署前,系统可以加载待检测的LoRA适配器,利用训练好的loracle模型快速判断其是否编码了后门、有害谎言或特定怪癖等非预期行为。这为模型供应链安全、第三方插件审核以及可控AI对齐提供了高效的工具,能够在不运行完整模型推理的情况下,通过分析权重变化来预测潜在风险,显著提升了模型行为审查的效率和可扩展性。
衍生相关工作
该数据集源于并深化了Shenoy等人(2026)关于“自省适配器”的开创性研究,为其提出的审计基准提供了核心训练资源。它进一步催生了专注于权重解读模型(loracle)架构设计、训练策略以及评估方法的一系列工作。这些衍生研究探索了如何更有效地从低秩适配器中提取语义信息,并将该范式扩展到其他类型的模型微调技术上。数据集本身的设计迭代,特别是从v5到v6在反混淆方面的改进,也成为了构建可靠行为探测数据集的经典方法论参考。
以上内容由遇见数据集搜集并总结生成


