BERSt
收藏Hugging Face2024-12-06 更新2024-12-12 收录
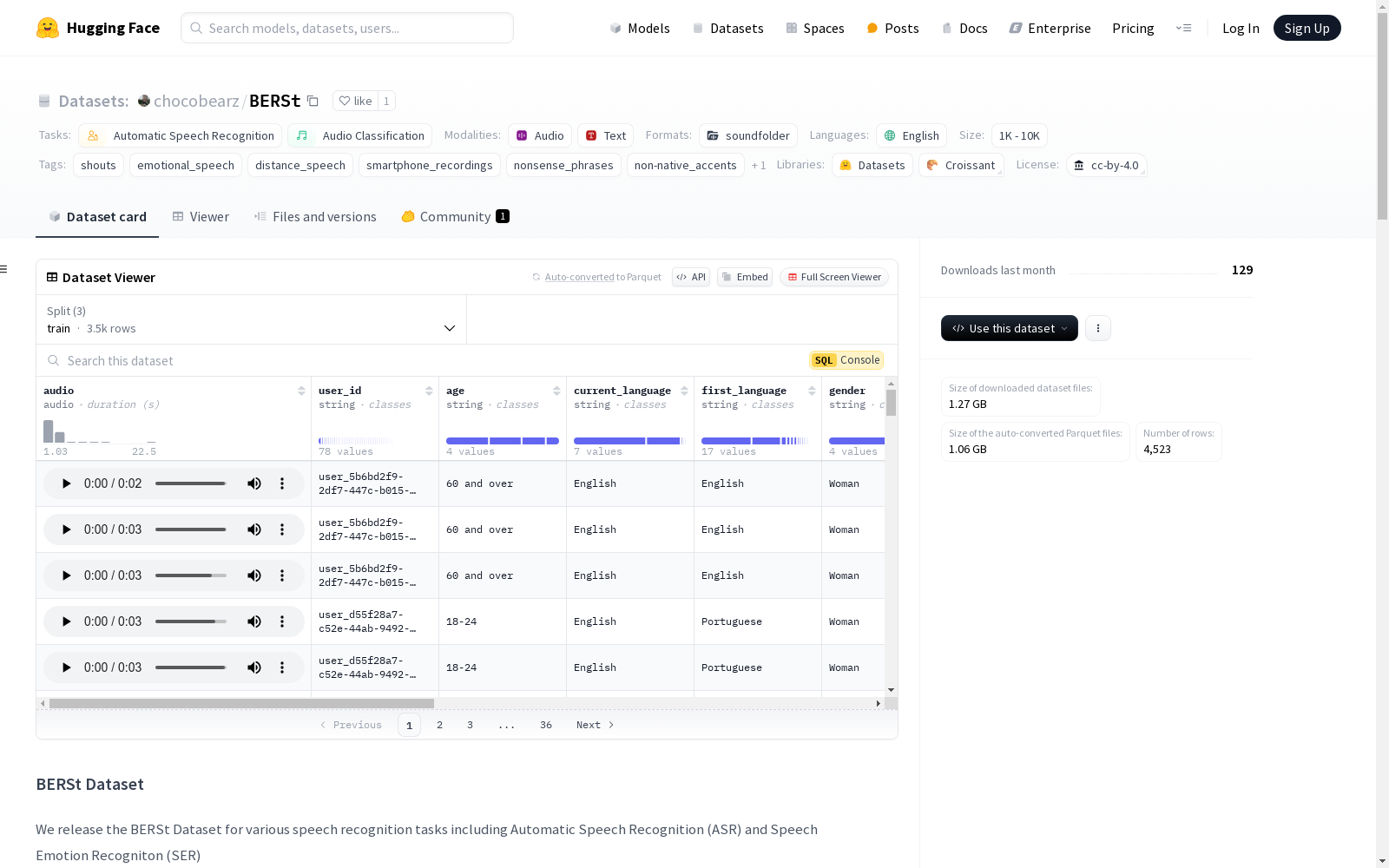
下载链接:
https://huggingface.co/datasets/chocobearz/BERSt
下载链接
链接失效反馈官方服务:
资源简介:
BERSt数据集是一个用于自动语音识别(ASR)和语音情感识别(SER)任务的数据集。它包含4526个单句录音,由98位专业演员在19个手机位置和7种情感类别下录制,涵盖了3种语音强度水平。录音中包含了多种英语口音和非母语口音,以及无意义的短语,旨在测试模型在复杂环境下的表现。数据集还提供了详细的元数据,包括演员的性别、母语、情感类别等。
The BERSt dataset is a specialized resource designed for automatic speech recognition (ASR) and speech emotion recognition (SER) tasks. It comprises 4,526 single-sentence recordings collected from 98 professional actors, with recordings conducted across 19 smartphone placement scenarios, 7 emotion categories, and 3 levels of speech intensity. The recordings include a diverse range of native and non-native English accents, as well as nonsensical phrases, and are intended to evaluate model performance in complex environments. Additionally, the dataset provides detailed metadata covering the actors' gender, native language, emotion category, and other relevant information.
创建时间:
2024-12-05
原始信息汇总
BERSt Dataset
概述
- 数据量: 4526个单句录音(约3.75小时)
- 参与者: 98名专业演员
- 录音位置: 19种手机位置
- 情感类别: 7种
- 语音强度: 3个级别
- 语言特点: 包含多种地区和非母语英语口音
- 录音内容: 13个无意义短语,涵盖所有英语音素
数据收集
- 环境: 在家中使用各种智能手机麦克风收集数据
- 参与者分布: 来自全球,包括英国、加拿大、美国(多州)、澳大利亚等地区
- 非母语英语: 包括法语、俄语、印地语等非母语英语口音
- 录音方式: 参与者在不同距离和位置大声说出短语,并模拟各种麦克风障碍
数据分割与组织
- 录音文件: 每个手机位置和短语对应三种语音强度级别的单个录音
- 元数据: 以CSV格式提供,包含每个话语的分割信息,噪音和静音已去除
- 数据分割: 提供测试、训练和验证集,无说话者交叉
- 训练与验证集: 每个包含10个未在训练集中出现的说话者
元数据详情
- 演员数量: 98
- 性别分布:
- 女性: 61
- 男性: 34
- 非二元性别: 1
- 不愿透露: 2
- 日常语言:
- 英语: 95
- 挪威语: 1
- 俄语: 1
- 法语: 1
- 母语:
- 英语: 75
- 非英语: 23
- 西班牙语: 6
- 法语: 3
- 葡萄牙语: 3
- 中文: 2
- 挪威语: 1
- 普通话: 1
- 塔加洛语: 1
- 意大利语: 1
- 匈牙利语: 1
- 俄语: 1
- 印地语: 1
- 斯瓦希里语: 1
- 克罗地亚语: 1
- 情感分布:
- 恐惧: 236
- 中性: 234
- 厌恶: 232
- 喜悦: 224
- 愤怒: 223
- 惊讶: 210
- 悲伤: 201
- 距离分布:
- 靠近身体: 627
- 1-2米远: 324
- 房间另一侧: 316
- 房间外: 293
搜集汇总
数据集介绍
构建方式
BERSt数据集通过在全球范围内招募98名专业演员,在家庭环境中使用智能手机麦克风进行录音,构建了一个多样化的语音数据集。参与者涵盖了多种英语口音,包括英国、加拿大、美国、澳大利亚等地区的口音,以及非母语英语者的口音,如法语、俄语、印地语等。数据集包含13个无意义短语,覆盖所有英语音素,旨在用于对语言上下文不敏感且具有高意外性的用例。参与者被要求在不同距离和位置(如背包内)以及不同音量级别(正常、提高、喊叫)下录制短语,以模拟真实世界中的复杂语音环境。
特点
BERSt数据集的显著特点在于其多样性和复杂性。数据集包含4526个单句录音,涵盖7种情感类别和3种音量级别,以及19种不同的手机位置。此外,数据集还包含了多种区域性和非母语英语口音,以及无意义短语,确保了语音识别任务的挑战性。通过在家庭环境中模拟各种实际录音条件,如距离变化和麦克风遮挡,BERSt数据集为语音识别和情感识别任务提供了丰富的训练和测试资源。
使用方法
BERSt数据集适用于自动语音识别(ASR)和语音情感识别(SER)任务。用户可以通过提供的训练、验证和测试集进行模型训练和评估。数据集的元数据以CSV格式提供,包含每个录音的详细信息,如演员编号、性别、语言背景等。用户可以利用这些元数据进行更精细的模型调整和分析。此外,数据集还提供了经过处理的干净音频片段,方便用户直接用于模型输入。通过在BERSt数据集上进行模型微调和基准测试,研究人员可以评估其在复杂语音环境下的性能。
背景与挑战
背景概述
BERSt数据集,由98名专业演员在家庭环境中使用智能手机麦克风录制,涵盖了4526个单句录音,总时长约3.75小时。该数据集旨在支持自动语音识别(ASR)和语音情感识别(SER)任务,特别关注于处理非母语口音、区域口音以及无意义短语的挑战。数据集包含了19种不同的手机位置、7种情感类别和3种语音强度级别,以及多样化的区域和非母语英语口音,如法语、俄语、印地语等。BERSt数据集的创建旨在模拟真实世界中的复杂语音环境,为研究人员提供了一个在困难条件下测试和优化模型的平台。
当前挑战
BERSt数据集面临的挑战主要集中在语音识别和情感识别的复杂性上。首先,数据集包含了多种非母语和区域口音,这增加了语音识别的难度。其次,无意义短语的使用虽然覆盖了所有英语音素,但也带来了理解上下文的挑战。此外,录音环境多样,包括不同的手机位置和麦克风障碍,如背包中的手机,这些都增加了数据处理的复杂性。最后,情感标注仅由演员提供,尚未通过感知验证,这可能影响情感识别的准确性。这些挑战使得BERSt数据集成为测试和提升语音识别和情感识别模型性能的理想选择。
常用场景
经典使用场景
BERSt数据集在自动语音识别(ASR)和语音情感识别(SER)领域展现了其独特的应用价值。通过包含多种情感类别、不同音量强度以及非母语和地区口音的语音样本,该数据集为研究人员提供了一个复杂且真实的语音环境,特别适用于在嘈杂或非理想条件下进行模型训练和评估。
实际应用
在实际应用中,BERSt数据集可用于开发和优化语音助手、情感分析工具以及多语言语音识别系统。例如,通过该数据集训练的模型能够更好地理解带有口音或情感色彩的语音输入,从而提升用户体验,特别是在智能家居、客户服务和心理健康监测等领域。
衍生相关工作
基于BERSt数据集,许多研究工作聚焦于提升语音识别和情感分析的鲁棒性。例如,有研究通过该数据集开发了针对非母语口音的语音识别模型,以及在不同音量和距离条件下表现稳定的情感识别算法。这些工作不仅推动了语音处理技术的发展,也为跨文化交流和情感计算提供了新的研究方向。
以上内容由遇见数据集搜集并总结生成


