CN_pose3D_V7_512
收藏Hugging Face2025-11-11 更新2025-11-12 收录
下载链接:
https://huggingface.co/datasets/AbstractPhil/CN_pose3D_V7_512
下载链接
链接失效反馈官方服务:
资源简介:
CN_pose3D_V7处理版是一个基于CN_pose3D_V10的数据集,它是一个用于预训练的人体娃娃集合。数据集经过处理,包括调整图像大小、移除白色背景的二进制掩码、GPU加速批量处理等。数据集包含RGB图像、RGB姿态图像、二进制掩码以及文本提示等列。该数据集适用于各种形式的预训练。
创建时间:
2025-11-11
原始信息汇总
CN_pose3D_V7_512数据集概述
基本信息
- 数据集名称:CN_pose3D_V7_512
- 许可证:Apache 2.0
- 源数据集:tori29umai/CN_pose3D_V7
数据集描述
- 这是tori29umai/CN_pose3D_V7数据集的已处理版本
- 本质上是一个可用于各种预训练形式的人体模型数据集
- 标签质量较差
- 建议以未缩放方式进行训练,使用0.181以外的参数
- 所有内容应标记为"ai-generated"和"masked"
处理进度
- 已处理图像:255,000/255,000(100%)
- 已上传分片:255
处理方式
- 调整为512x512分辨率(使用LANCZOS算法)
- 用于白背景去除的二进制掩码
- GPU加速的批量处理
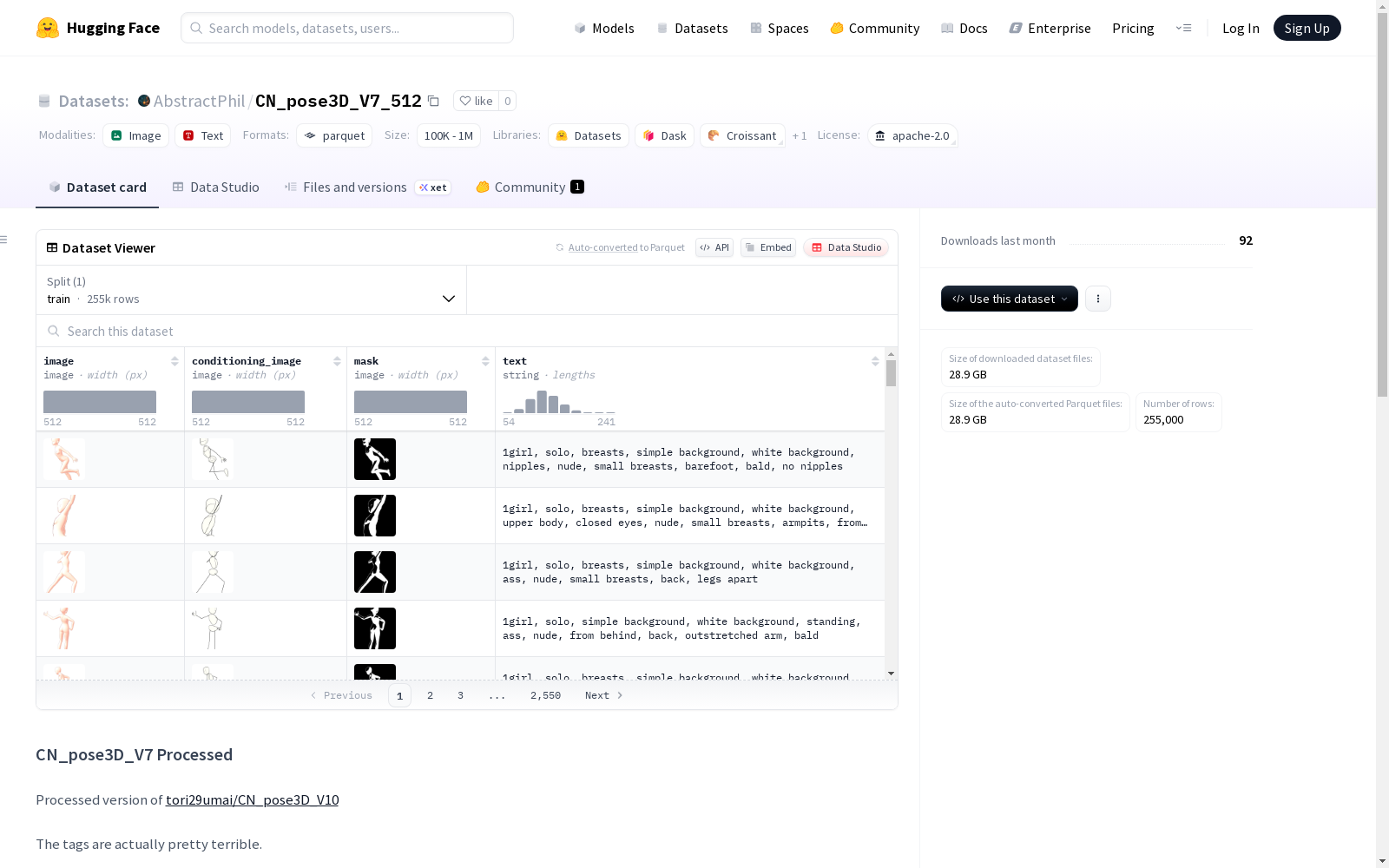
数据列结构
image:RGB图像(512x512)conditioning_image:RGB姿态图像(512x512)mask:二进制掩码(512x512)- 0=忽略白色背景,255=保留text:文本提示
使用建议
- 需要多个连续图像才能有效使用该数据集
- 首次训练建议在flow-lune上使用400-600时间步进行测试
- 可能需要重新制作掩码,因为存在一些间隙
- 建议减弱颜色,因为模型形状应为斑点和轮廓
- 白色背景需要完全掩码去除
归属信息
- 原始数据集:https://huggingface.co/datasets/tori29umai/CN_pose3D_V7
- 许可证:Apache 2.0
搜集汇总
数据集介绍
构建方式
在三维人体姿态建模领域,CN_pose3D_V7_512数据集通过系统化处理流程构建而成。原始数据来源于tori29umai/CN_pose3D_V7数据集,经过GPU加速批处理技术对25.5万张图像进行统一规格化处理。所有图像均采用LANCZOS算法重采样至512×512分辨率,并运用二进制掩码技术实现白色背景的精准分离,其中掩码值为255的区域保留有效内容,值为0的区域则对应需要忽略的白色背景。
特点
该数据集作为人体模型训练资源具有显著特性。其核心价值在于提供三位一体的数据要素:包含原始RGB图像、对应姿态条件图像以及二值掩码图像,形成完整的训练单元。数据标注采用文本提示词机制,虽然开发者坦言标签质量存在优化空间,但通过预设的“ai-generated”统一标记与掩码处理,仍能有效支持生成式模型的预训练需求。白色背景的彻底剔除与色彩弱化处理,更强化了模型对主体轮廓特征的学习能力。
使用方法
针对生成式模型的预训练场景,该数据集需配合连续图像序列进行使用。实践表明采用非缩放训练策略优于0.181缩放系数,建议在400-600时间步范围内进行参数调优。使用过程中需特别注意掩码区域的完整性验证,若发现间隙应及时进行重掩码处理。由于数据集专门针对人体轮廓学习设计,训练时应当强化对姿态条件图像的解析,同时通过色彩弱化技术提升模型对形体结构的专注度,最终实现对人体姿态的精准建模。
背景与挑战
背景概述
在计算机视觉与生成式人工智能蓬勃发展的背景下,CN_pose3D_V7_512数据集应运而生,作为tori29umai/CN_pose3D_V7数据集的优化版本,其核心目标在于为人体姿态建模与图像生成任务提供高质量的预训练资源。该数据集由研究团队基于Apache 2.0许可协议构建,专注于利用三维人体模型生成连续图像序列,以支持生成对抗网络和扩散模型等先进算法的训练。通过提供精确的姿态条件图像与掩码信息,该数据集显著推动了可控图像生成技术在虚拟人像合成、动画制作等领域的应用进展。
当前挑战
该数据集致力于解决人体姿态引导图像生成中的关键难题,包括如何在复杂背景中准确分离人体轮廓,以及如何确保生成图像在姿态连贯性与细节真实性上的平衡。构建过程中面临多重技术挑战:原始标注质量不稳定导致标签可信度低,需通过后处理优化;白色背景的完全剔除依赖二值掩码的精确生成,任何间隙都会影响模型学习效果;图像缩放与色彩调整若处理不当,可能削弱预训练数据的有效性,进而转化为带噪声的训练样本。
常用场景
经典使用场景
在计算机视觉与生成模型领域,CN_pose3D_V7_512数据集作为人体姿态合成的重要资源,其经典应用聚焦于生成对抗网络与扩散模型的预训练过程。该数据集通过提供标准化的人体姿态图像与对应掩码,使模型能够学习从结构化姿态条件到真实图像的高质量映射,为姿态引导的图像生成任务奠定基础。
解决学术问题
该数据集有效解决了生成模型中姿态一致性保持与背景分离的核心难题。通过精确的二进制掩码与白背景剔除机制,显著提升了模型对主体轮廓的感知能力,同时其大规模连续图像序列为时序生成研究提供了数据支撑,推动了条件生成模型在结构保持与内容可控方面的理论突破。
衍生相关工作
基于该数据集衍生的经典工作主要集中在多模态生成架构的优化领域。研究者通过改进掩码策略与颜色弱化技术,发展了更鲁棒的姿态迁移模型;同时其与SD15预训练数据的结合应用,催生了系列关于噪声调度与训练稳定性优化的创新方法,为后续三维人体重建研究提供了重要参考。
以上内容由遇见数据集搜集并总结生成


