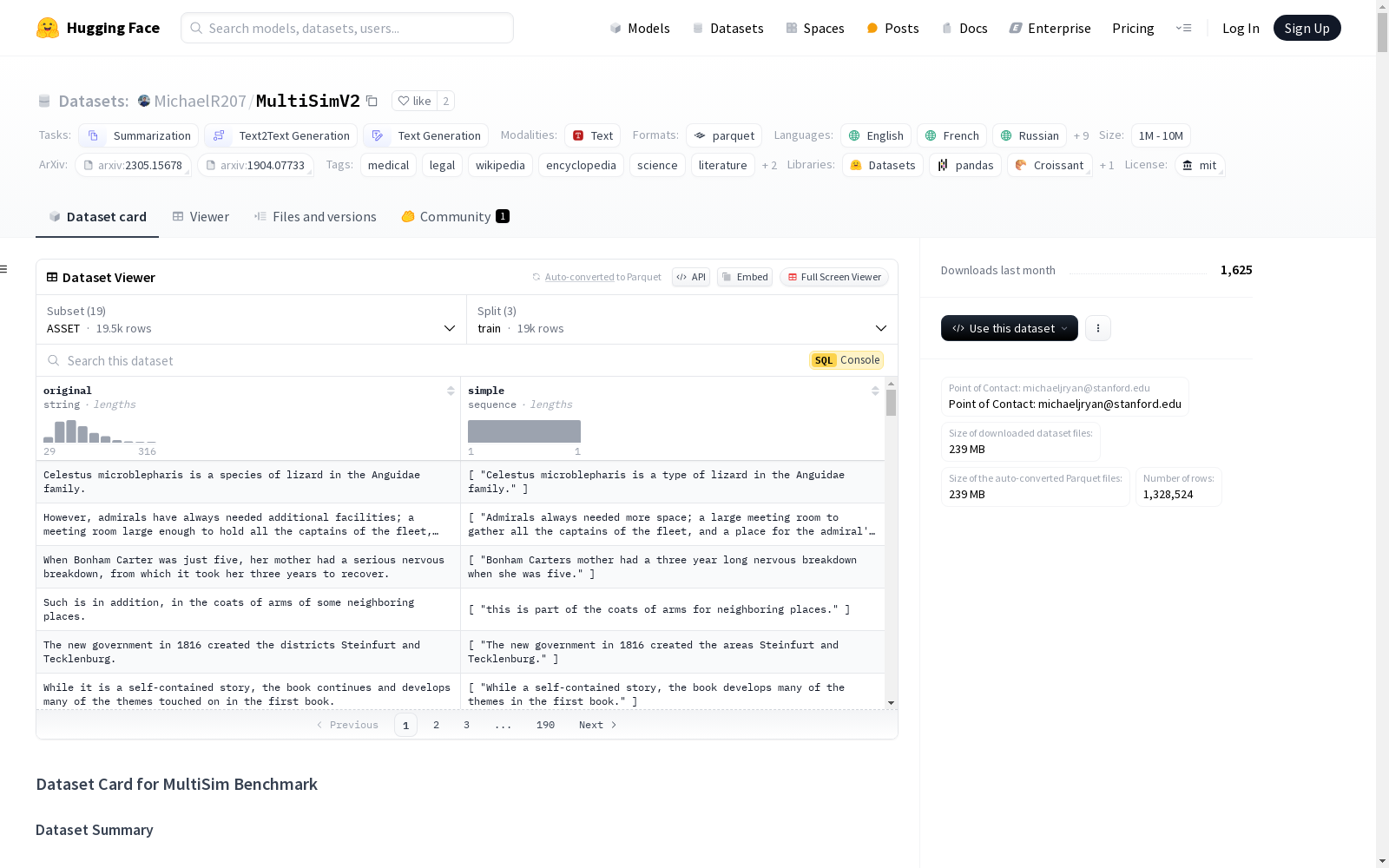
MultiSimV2
收藏MultiSimV2 数据集概述
数据集描述
数据集概要
MultiSimV2 是一个不断增长的文本简化数据集集合,专注于多种语言的句子简化。目前,该基准涵盖了12种语言。
支持的任务
- 句子简化
使用方法
python from datasets import load_dataset
dataset = load_dataset("MichaelR207/MultiSimV2")
引用
@inproceedings{ryan-etal-2023-revisiting, title = "Revisiting non-{E}nglish Text Simplification: A Unified Multilingual Benchmark", author = "Ryan, Michael and Naous, Tarek and Xu, Wei", booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)", month = jul, year = "2023", address = "Toronto, Canada", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/2023.acl-long.269", pages = "4898--4927", abstract = "Recent advancements in high-quality, large-scale English resources have pushed the frontier of English Automatic Text Simplification (ATS) research. However, less work has been done on multilingual text simplification due to the lack of a diverse evaluation benchmark that covers complex-simple sentence pairs in many languages. This paper introduces the MultiSim benchmark, a collection of 27 resources in 12 distinct languages containing over 1.7 million complex-simple sentence pairs. This benchmark will encourage research in developing more effective multilingual text simplification models and evaluation metrics. Our experiments using MultiSim with pre-trained multilingual language models reveal exciting performance improvements from multilingual training in non-English settings. We observe strong performance from Russian in zero-shot cross-lingual transfer to low-resource languages. We further show that few-shot prompting with BLOOM-176b achieves comparable quality to reference simplifications outperforming fine-tuned models in most languages. We validate these findings through human evaluation.", }
联系人
Michael Ryan: Scholar | Twitter | Github | LinkedIn | Research Gate | Personal Website | michaeljryan@stanford.edu
语言
- 英语
- 法语
- 俄语
- 日语
- 意大利语
- 丹麦语(需请求)
- 西班牙语(需请求)
- 德语
- 巴西葡萄牙语
- 斯洛文尼亚语
- 乌尔都语(需请求)
- 巴斯克语(需请求)
数据集结构
数据实例
MultiSimV2 包含27个现有数据集:
- AdminIT
- ASSET
- CBST
- CLEAR
- DSim
- Easy Japanese
- Easy Japanese Extended
- GEOLino
- German News
- Newsela EN/ES
- PaCCSS-IT
- PorSimples
- RSSE
- RuAdapt Encyclopedia
- RuAdapt Fairytales
- RuAdapt Literature
- RuWikiLarge
- SIMPITIKI
- Simple German
- Simplext
- SimplifyUR
- SloTS
- Teacher
- Terence
- TextComplexityDE
- WikiAuto
- WikiLargeFR
数据字段
在训练集中,您只会找到 original 和 simple 句子。在验证和测试集中,您可能会找到 simple1, simple2, ... simpleN,因为一个句子可以有多个参考简化(用于SARI和BLEU计算)。
数据分割
数据集被分为训练集、验证集和测试集。
数据集创建
数据来源
数据来自27个现有数据集,这些数据集构成了MultiSimV2基准。
注释过程
注释者编写简化句时通常遵循注释指南。
注释者
注释者包括作家、翻译、教师、语言学家、记者、众包工作者、专家、新闻机构、医学生、学生、作家和研究人员。
使用数据集的注意事项
数据集的社会影响
我们希望这个数据集能够对社会产生积极影响,因为文本简化任务服务于儿童、第二语言学习者以及有阅读/认知障碍的人群。
数据集的偏见
注释者可能会有偏见,倾向于他们认为更简单的句子应该如何书写。此外,注释者和编辑可以选择简化句子中不包含哪些信息,从而引入信息重要性偏见。
其他已知限制
一些资源是自动收集或机器翻译的,因此并非每个句子都完美对齐。建议用户在使用这些个别资源时谨慎。
附加信息
数据集许可
MIT License
引用信息
请根据您使用的MultiSimV2基准中的个别数据集进行适当引用。