ServiceNow/repliqa
收藏Hugging Face2025-06-09 更新2024-06-22 收录
下载链接:
https://hf-mirror.com/datasets/ServiceNow/repliqa
下载链接
链接失效反馈官方服务:
资源简介:
RepLiQA是一个评估数据集,包含上下文-问题-答案三元组,其中上下文是关于虚构实体(如不存在的人或地点)的非事实性但自然外观的文档。该数据集由人工创建,旨在测试大型语言模型(LLMs)在提供的文档中查找和使用上下文信息的能力。与现有的问答数据集不同,RepLiQA的非事实性使得模型的性能不会受到LLMs从训练数据中记忆事实的能力的影响,从而更可靠地测试模型利用上下文的能力。数据集包含17个主题的文档,每个文档附带5个问题-答案对,其中约20%的问题无法从文档中回答。
RepLiQA is an evaluation dataset that contains Context-Question-Answer triplets, where contexts are non-factual but natural-looking documents about made up entities such as people or places that do not exist in reality. RepLiQA is human-created, and designed to test for the ability of Large Language Models (LLMs) to find and use contextual information in provided documents. Unlike existing Question-Answering datasets, the non-factuality of RepLiQA makes it so that the performance of models is not confounded by the ability of LLMs to memorize facts from their training data: one can test with more confidence the ability of a model to leverage the provided context. The dataset comprises 17 topics of documents, each accompanied by 5 question-answer pairs, with approximately 20% of the questions being unanswerable from the provided documents.
提供机构:
ServiceNow
原始信息汇总
RepLiQA 数据集概述
数据集摘要
RepLiQA 是一个评估数据集,包含上下文-问题-答案三元组,其中上下文是非事实性的,但看起来自然的文档,涉及虚构的实体,如人物或地点,这些实体在现实中不存在。RepLiQA 是由人工创建的,旨在测试大型语言模型(LLMs)在提供文档中查找和利用上下文信息的能力。与现有的问答数据集不同,RepLiQA 的非事实性使得模型的性能不会受到 LLMs 从训练数据中记忆事实的能力的干扰,从而可以更自信地测试模型利用提供上下文的能力。
RepLiQA 中的文档包含 17 个主题或文档类别:公司政策、网络安全新闻、本地技术和创新、本地环境问题、地区民间传说和神话、本地政治和治理、新闻故事、本地经济和市场、本地教育系统、本地艺术和文化、本地新闻、中小型企业、事故报告、地区美食和食谱、邻里故事、本地体育和活动 以及 本地健康和福祉。非事实性文档在这些主题之一中进行注释,涵盖未记录的虚构/虚构实体。每个文档伴随 5 个问答对。
此外,RepLiQA 中的注释使得大约 20% 的问题无法从提供的文档中回答,模型预计在无法回答时指示无法获得答案。
支持的任务
RepLiQA 旨在支持以下任务:
- 问答
- 主题检索
- 选择性问答(即测试拒绝回答无法从提供上下文中回答的问题的能力)
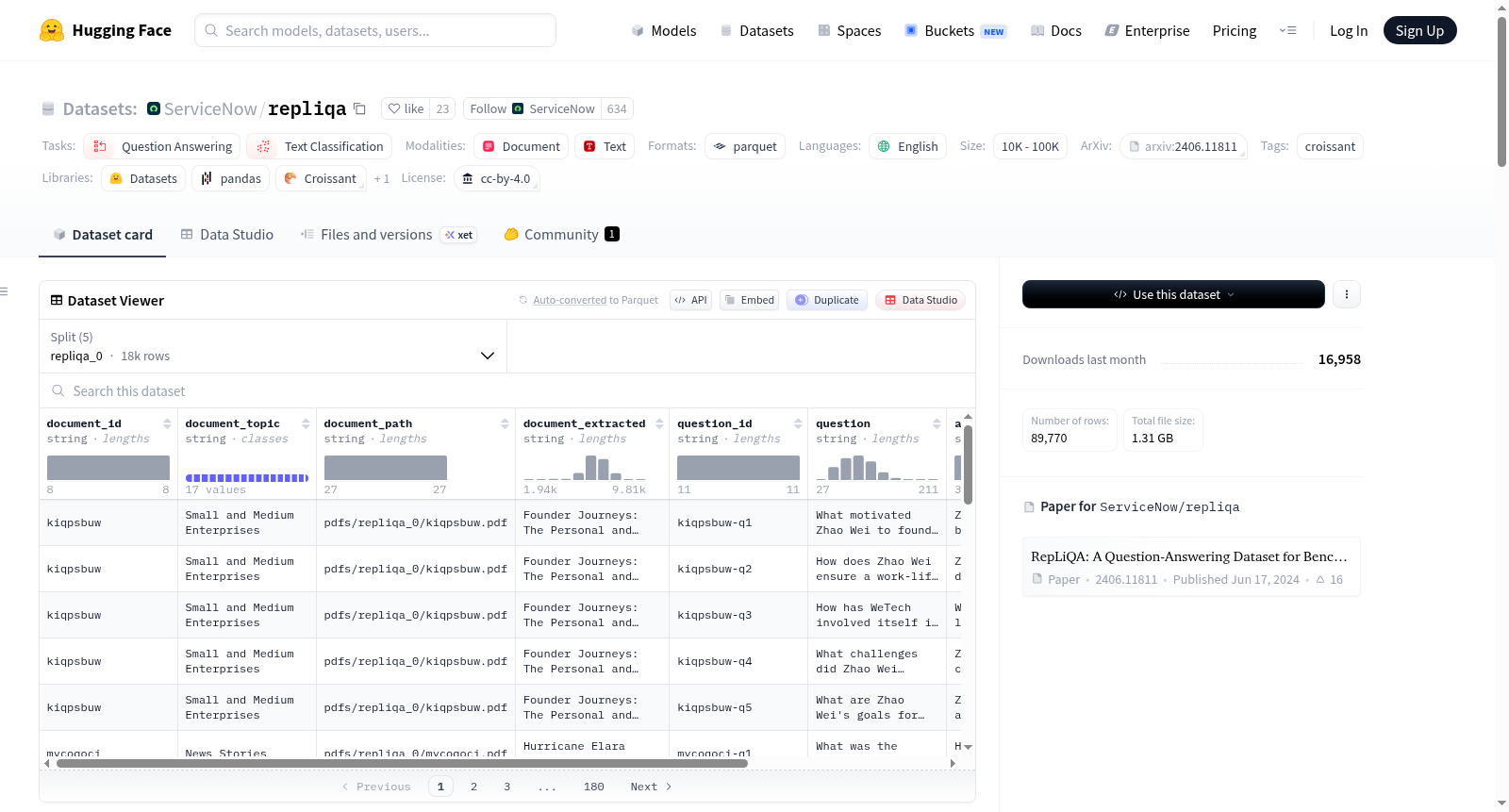
数据字段
document_id(字符串): 唯一标识与此样本相关的文档。注意每个文档有 5 个问题,因此每个document_id在数据集中出现 5 次。document_topic(字符串): 上述 17 个文档主题/类别之一。document_path(字符串): 在此存储库中指向原始 PDF 文档的相对路径。document_extracted(字符串): 从原始 PDF 文档自动提取的文本。question_id(字符串): 唯一标识每个文档-问题组合,因此每个数据样本。question(字符串): 可能或不可能使用相关文档回答的问题。answer(字符串): 当可以使用文档回答问题时,答案为UNANSWERABLE否则。long_answer(字符串): 生成answer的注释者被要求在此处复制粘贴他们在文档中找到answer的段落。此long_answer按原样提供,无需检查它是否实际包含在文档中。当answer为UNANSWERABLE时,long_answer为NA。
数据注释流程摘要
- 主题选择。
- 生成大约 1000 字的参考文档。在创建虚构角色、地点和组织时,注释者使用随机名称生成器和匿名化工具交叉参考现有实体,以避免无意中的引用。
- 自动总结参考文档。
- 仅基于摘要注释 5 个具体和直接的问题。
- 基于完整文档和问题注释相关答案。
- 质量控制:所有样本都经过审查,初始拒绝率约为 5-10%。
- 数据分割和进一步清理以去除遗留的噪声内容。
已知问题
- 观察到各种不规则性,包括代码块(例如,在角
<>或方[]括号内)。 - 使用 Fast-DetectGPT 对 RepLiQA 文档进行评分,结果与 FineWeb 的评分显著不同。
更新计划
RepLiQA 包含五个分割,将在一年内逐步发布:
repliqa_02024 年 6 月 12 日。repliqa_12024 年 12 月 9 日。repliqa_22025 年 2 月 10 日。repliqa_32025 年 4 月 14 日。repliqa_42025 年 6 月 9 日。
这些分割应全部相同分布。这种逐步发布计划旨在避免泄露新的数据分区,并确保在评估时模型不会在其上下文中进行训练。
如何使用 RepLiQA 进行基准测试
最终将发布五个 RepLiQA 分割。由于评估 LLMs 可能成本高昂,一些作者可能更喜欢在已发布的分割子集上进行评估。我们推荐以下选择:
- (最新) 如果您只评估一个分割,请使用最新发布的分割(首选评估设置);
- (zeroth+latest) 如果您评估两个分割,请使用
repliqa_0和最新发布的分割; - (全部) 如果您评估超过两个分割,请使用所有已发布的分割。
通常,请明确指定使用了哪些 RepLiQA 分割,并分别报告每个分割的结果。
搜集汇总
数据集介绍
构建方式
RepLiQA数据集的构建过程严谨且富有创意,旨在规避大型语言模型对事实性知识的记忆干扰。首先,研究团队精心挑选了涵盖公司政策、网络安全新闻、地方环境议题等17个主题类别,并利用随机名称生成器与匿名化工具,创造出一系列虚构的人物、地点与组织,确保这些实体在现实世界中不存在。随后,针对每个虚构主题,人工撰写约1000字的参考文档,并自动生成其摘要。基于这些摘要,标注员提出5个具体且直接的问题,再依据完整文档给出答案。为保证质量,所有样本均经过人工审核,初始拒绝率约为5-10%。最终,数据集被划分为5个独立且分布一致的子集,并计划在一年内逐步发布。
特点
RepLiQA的核心特点在于其非事实性(non-factuality),这使得评估模型时能够更纯粹地检验其上下文利用能力,而非依赖参数化记忆。数据集包含约9万个样本,每个样本均由文档、问题与答案三元组构成,其中约20%的问题被设计为无法从给定文档中回答,模型需输出“UNANSWERABLE”以展示其拒绝回答的能力。文档内容自然流畅,涵盖17个多样化主题,且每个文档配备5个问答对。此外,数据集还提供了长答案字段,记录答案在文档中的出处段落,便于深入分析。这种设计使得RepLiQA成为评估模型在检索、问答与选择性回答等任务上表现的有力工具。
使用方法
使用RepLiQA进行基准测试时,推荐根据可用计算资源选择子集。若仅评估一个子集,建议使用最新发布的版本(preferred evaluation setting);若评估两个子集,则结合repliqa_0与最新版本;评估更多子集时,应使用所有已发布版本。在报告中,需明确指明所使用的子集,并分别汇报各子集的结果。数据集可通过HuggingFace平台直接加载,支持问答与文本分类任务。用户可参考官方提供的教程,了解如何结合PDF文档进行样本解析,或利用openrouter.ai复现评估流程。所有数据均遵循CC BY 4.0许可协议,便于学术研究与商业应用。
背景与挑战
背景概述
RepLiQA数据集由加拿大ServiceNow研究团队于2024年创建,核心成员包括João Monteiro、Pierre-André Noël等,旨在解决大语言模型(LLM)在问答任务中依赖训练数据记忆而非上下文推理的固有问题。传统问答数据集如SQuAD或Natural Questions常受限于模型对事实性知识的预训练记忆,导致评估结果混淆了上下文利用能力与知识检索能力。RepLiQA通过构建完全虚构的非事实性文档(涵盖公司政策、地方传说、网络安全新闻等17个主题),并配以人工标注的问题-答案三元组,确保所有上下文内容在现实世界中无对应实体,从而剥离模型先验知识的影响。该数据集在NeurIPS 2024数据集赛道发布,其渐进式分片发布策略(五批数据于一年内陆续公开)进一步防止了数据泄露,为LLM的上下文理解能力提供了更纯净的评测基准。
当前挑战
RepLiQA面临的核心挑战包括:1)领域问题层面,现有问答基准难以区分模型是否真正理解上下文,因为LLM常依赖参数化记忆作答。RepLiQA通过非事实性设计强制模型仅依赖给定文档,但约20%的不可答问题(标注为UNANSWERABLE)要求模型具备拒绝回答的能力,这对当前LLM的可靠性提出更高要求。2)构建过程中,人工标注需确保虚构实体不无意映射现实(通过随机名称生成器与交叉验证),且需在摘要与全文间保持答案一致性,初始标注拒绝率高达5-10%。此外,数据中残留的代码片段(如尖括号内容)和Fast-DetectGPT检测到的异常分布,表明自动提取与质量控制环节仍需优化,以保障数据纯净度。
常用场景
经典使用场景
RepLiQA作为一项精心设计的评估数据集,其核心应用场景在于衡量大语言模型在未见参考内容上的问答能力。该数据集通过构造虚构实体与场景的非事实性文档,要求模型仅依赖所提供的上下文信息进行回答,从而排除模型因训练数据中记忆事实而产生的混淆。这一设计使其成为检验模型上下文理解与信息检索能力的理想基准,尤其在开放域问答与选择性问答任务中展现出独特价值。
解决学术问题
在学术研究层面,RepLiQA直面了传统问答数据集难以规避的预训练记忆污染问题。现有数据集常因包含现实实体而使模型性能受限于其训练阶段的知识储备,无法真实反映其上下文利用能力。RepLiQA通过构建完全虚构的文档体系,并引入约20%的不可回答问题,为评估模型是否具备拒绝回答能力提供了严谨的测试框架,从而推动了对大语言模型推理鲁棒性与忠实性的深入探究。
衍生相关工作
围绕RepLiQA已催生出多项富有启发性的后续工作。其设计理念启发了研究者开发更细粒度的上下文利用度评估指标,并促进了选择性问答机制在检索增强生成框架中的整合。此外,该数据集独特的非事实性文档生成流程也为合成数据构建提供了方法论参考,推动了面向抗遗忘与抗幻觉能力的新型训练策略与评估协议的发展。
以上内容由遇见数据集搜集并总结生成


