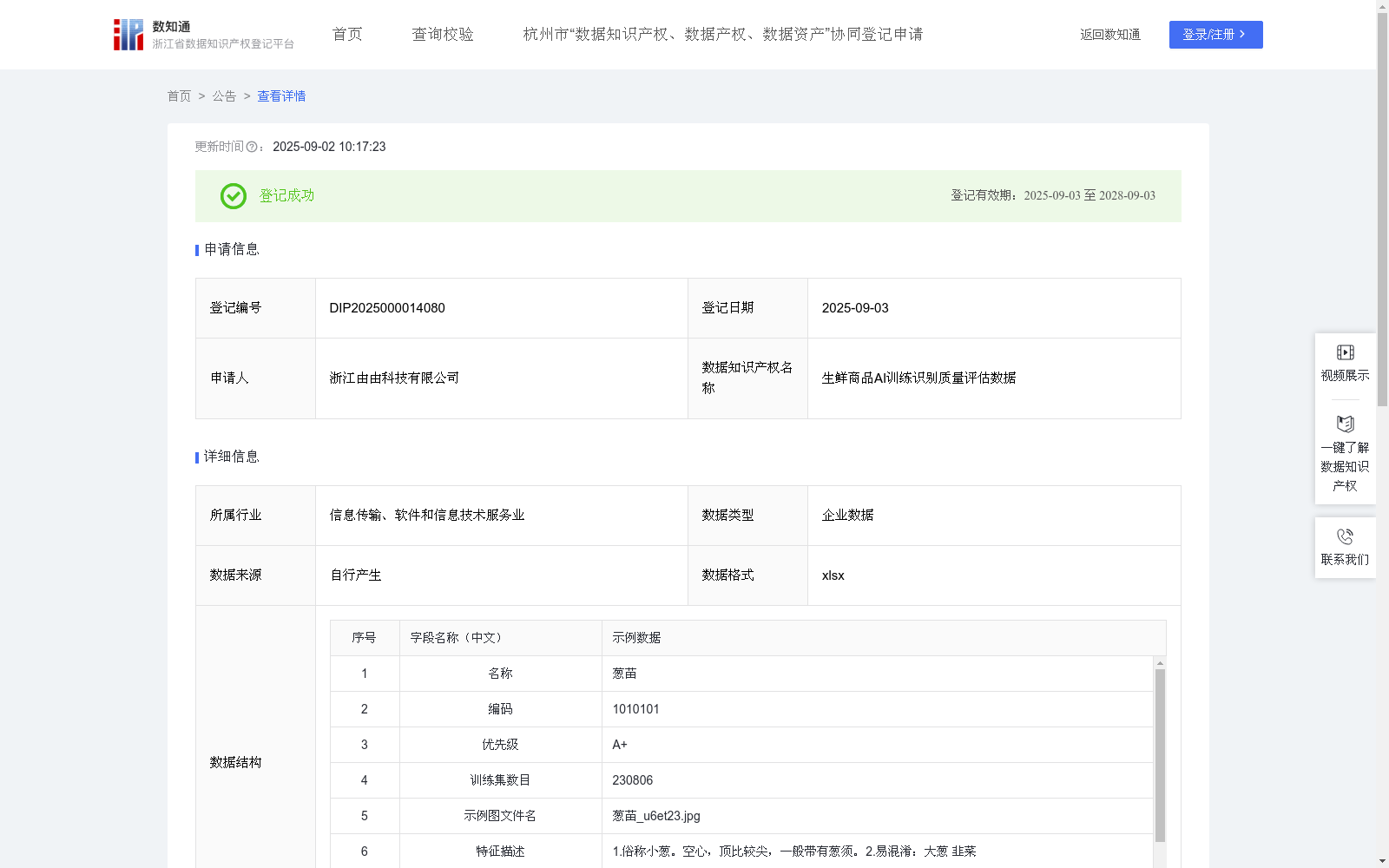
生鲜商品AI训练识别质量评估数据
收藏浙江省数据知识产权登记平台2025-09-02 更新2025-09-06 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/173777
下载链接
链接失效反馈官方服务:
资源简介:
本数据集形成了包括627种蔬菜、水果、禽肉、水产的经分类的图片训练集,该数据集将用于人工智能模型的训练,形成可以根据照片内容识别出照片中包含商品的智能模型。该模型可广泛应用于生鲜商场、超市的收银场景,直接通过摄像头拍照后识别出商品类型,省去原来需要人工识别商品并输入收银系统的繁琐步骤。1.数据收集:本数据集收集了2020年1月1日至2022年5月1日期间涉及627种蔬菜、水果、禽肉、水产的大量实物实拍照片,本数据集归属于申请人浙江由由科技有限公司。2.算法说明:第一步,先将627种不同商品的名称录入系统,为每一个商品确定唯一的编码,并为每一个名称商品建立训练集。第二步,以专家经验,依据每个商品的常见程度确定优先级,对于常见的品类给予较高的优先级,以此类推,使得优先级顺序:A+>A>B>C。第三步,根据专家经验和专业知识,为每一个产品添加特征描述,描述商品的特点,以帮助提供人工区分时的准确性。第四步,以专家经验和人工判断,参考特征描述,将收集来的照片分类分入不同商品名称下的训练集,例如,专家根据专业经验判断照片中的商品属于葱苗,然后将照片放入葱苗名称对应下的训练集。第五步,在所有照片归入对应的训练集后,统计形成训练集数目,代表该训练集中商品图片的数量。第六步,根据优先级和训练集数目计算出数据置信度等级。对于优先级为A+的商品,当训练集数目≥20000时,为非常高阈值,当训练集数目≥10000时,为高阈值,当训练集数目≥5000时,为中等阈值,当训练集数目<5000时,为低阈值;对于优先级为A的商品,当训练集数目≥15000时,为非常高阈值,当训练集数目≥8000时,为高阈值,当训练集数目≥4000时,为中等阈值,当训练集数目<4000时,为低阈值;对于优先级为B的商品,当训练集数目≥10000时,为非常高阈值,当训练集数目≥5000时,为高阈值,当训练集数目≥2500时,为中等阈值,当训练集数目<2500时,为低阈值;对于优先级为C的商品,当训练集数目≥5000时,为非常高阈值,当训练集数目≥2500时,为高阈值,当训练集数目≥1000时,为中等阈值,当训练集数目<1000时,为低阈值。非常高阈值对应置信度非常高、高阈值对应置信度高、中等阈值对应置信度中等、低阈值对应置信度低。置信度反映了该训练集的成熟度。
This dataset is a classified image training set covering 627 types of vegetables, fruits, poultry and aquatic products, and is designed for training artificial intelligence models to identify the goods contained in photographs. The trained model can be widely applied to checkout scenarios in fresh food markets and supermarkets: after capturing photos via a camera, it directly recognizes the product types, eliminating the cumbersome steps of manually identifying goods and inputting them into the checkout system.
1. Data Collection
This dataset collects a large number of real-world photos of the 627 types of vegetables, fruits, poultry and aquatic products from January 1, 2020 to May 1, 2022. This dataset is owned by the applicant, Zhejiang Youyou Technology Co., Ltd.
2. Algorithm Description
Step 1: First, input the names of the 627 different products into the system, assign a unique code to each product, and establish a training set for each product.
Step 2: Based on expert experience, determine the priority level according to the popularity of each product, with higher priority granted to more common categories, following the priority order: A+ > A > B > C.
Step 3: Add feature descriptions for each product based on expert experience and professional knowledge, detailing the characteristics of the goods to improve the accuracy of manual differentiation.
Step 4: Classify the collected photos into the training sets corresponding to different product names via expert experience and manual judgment, with reference to the feature descriptions. For example, an expert determines that the product in a photo is scallion seedlings based on professional experience, and then places the photo into the training set corresponding to the name "scallion seedlings".
Step 5: After all photos are assigned to their corresponding training sets, count the number of images in each training set.
Step 6: Calculate the data confidence level based on the priority level and the number of images in the training set.
- For products with priority A+: extremely high threshold when the number of training set images ≥20000, high threshold when ≥10000, medium threshold when ≥5000, and low threshold when <5000.
- For products with priority A: extremely high threshold when ≥15000, high threshold when ≥8000, medium threshold when ≥4000, and low threshold when <4000.
- For products with priority B: extremely high threshold when ≥10000, high threshold when ≥5000, medium threshold when ≥2500, and low threshold when <2500.
- For products with priority C: extremely high threshold when ≥5000, high threshold when ≥2500, medium threshold when ≥1000, and low threshold when <1000.
Extremely high threshold corresponds to extremely high confidence, high threshold to high confidence, medium threshold to medium confidence, and low threshold to low confidence. Confidence reflects the maturity of the training set.
提供机构:
浙江由由科技有限公司
创建时间:
2025-08-07
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是用于生鲜商品AI识别模型训练的质量评估数据,包含627种商品的图片和特征信息,规模为628条,通过优先级和训练集数目计算置信度以评估数据可靠性。主要应用于超市和商场的收银场景自动化,提升商品识别效率。
以上内容由遇见数据集搜集并总结生成


