longvideo-reason
收藏LongVideo-Reason 数据集概述
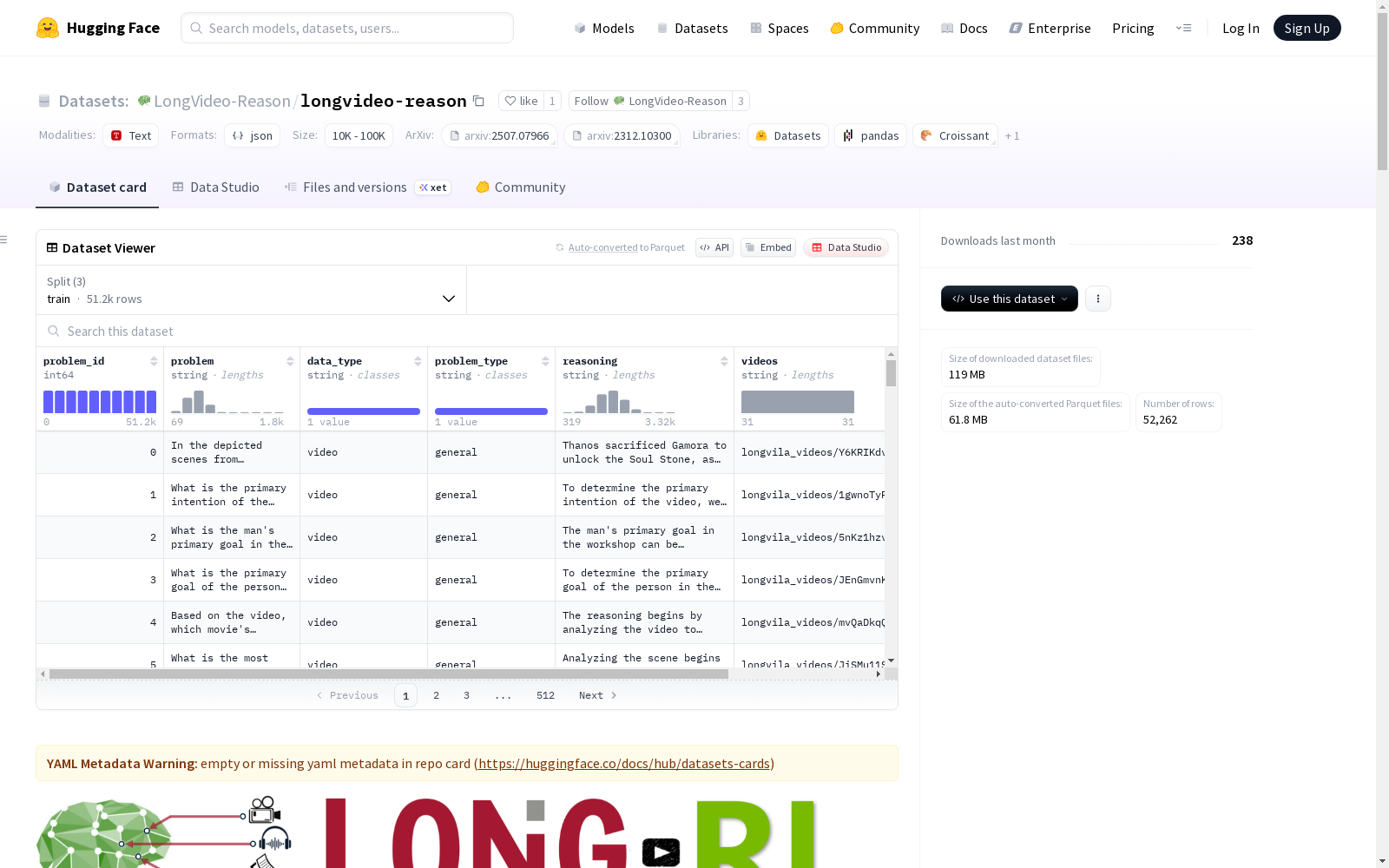
数据集基本信息
- 名称: LongVideo-Reason
- 类型: 长视频推理数据集
- 用途: 研究用途(仅限)
- 相关论文: Scaling RL to Long Sequences
数据集构成
- 训练集 (LongVideo-Reason): 52K 高质量问答推理对
- 测试集 (LongVideo-Reason-eval): 1K 手动筛选的长视频样本
- 数据来源: 18K 长视频(来自 Shot2Story)
数据特点
- 标注类型: CoT (Chain-of-Thought) 标注
- 构建工具: NVILA-8B VLM 和开源推理 LLM
- 评估维度: 时间、目标与目的、空间、情节与叙事
训练阶段
- 第一阶段 (Long-CoT-SFT): 18K 高质量样本用于初始化模型推理能力
- 第二阶段 (RL): 33K 样本 + 110K 视频数据用于强化学习
相关资源
- 代码库: Long-RL GitHub
- 测试集地址: LongVideo-Reason-eval
引用信息
bibtex @misc{long-rl, title = {Long-RL: Scaling RL to Long Sequences}, author = {Yukang Chen, Wei Huang, Shuai Yang, Qinghao Hu, Baifeng Shi, Hanrong Ye, Ligeng Zhu, Zhijian Liu, Pavlo Molchanov, Jan Kautz, Xiaojuan Qi, Sifei Liu,Hongxu Yin, Yao Lu, Song Han}, year = {2025}, publisher = {GitHub}, journal = {GitHub repository}, howpublished = {url{https://github.com/NVlabs/Long-RL}}, }
bibtex @article{chen2025longvila-r1, title={Scaling RL to Long Videos}, author={Yukang Chen and Wei Huang and Baifeng Shi and Qinghao Hu and Hanrong Ye and Ligeng Zhu and Zhijian Liu and Pavlo Molchanov and Jan Kautz and Xiaojuan Qi and Sifei Liu and Hongxu Yin and Yao Lu and Song Han}, year={2025}, eprint={2507.07966}, archivePrefix={arXiv}, primaryClass={cs.CV} }
bibtex @inproceedings{chen2024longvila, title={LongVILA: Scaling Long-Context Visual Language Models for Long Videos}, author={Yukang Chen and Fuzhao Xue and Dacheng Li and Qinghao Hu and Ligeng Zhu and Xiuyu Li and Yunhao Fang and Haotian Tang and Shang Yang and Zhijian Liu and Ethan He and Hongxu Yin and Pavlo Molchanov and Jan Kautz and Linxi Fan and Yuke Zhu and Yao Lu and Song Han}, booktitle={The International Conference on Learning Representations (ICLR)}, year={2025}, }