---
dataset_info:
features:
- name: text
dtype: string
- name: span
dtype: string
- name: label
dtype: string
- name: ordinal
dtype: int64
splits:
- name: train
num_bytes: 335243
num_examples: 2358
- name: test
num_bytes: 76698
num_examples: 654
download_size: 146971
dataset_size: 411941
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
# Dataset Card for "tomaarsen/setfit-absa-semeval-laptops"
### Dataset Summary
This dataset contains the manually annotated laptop reviews from SemEval-2014 Task 4, in the format as
understood by [SetFit](https://github.com/huggingface/setfit) ABSA.
For more details, see https://aclanthology.org/S14-2004/
### Data Instances
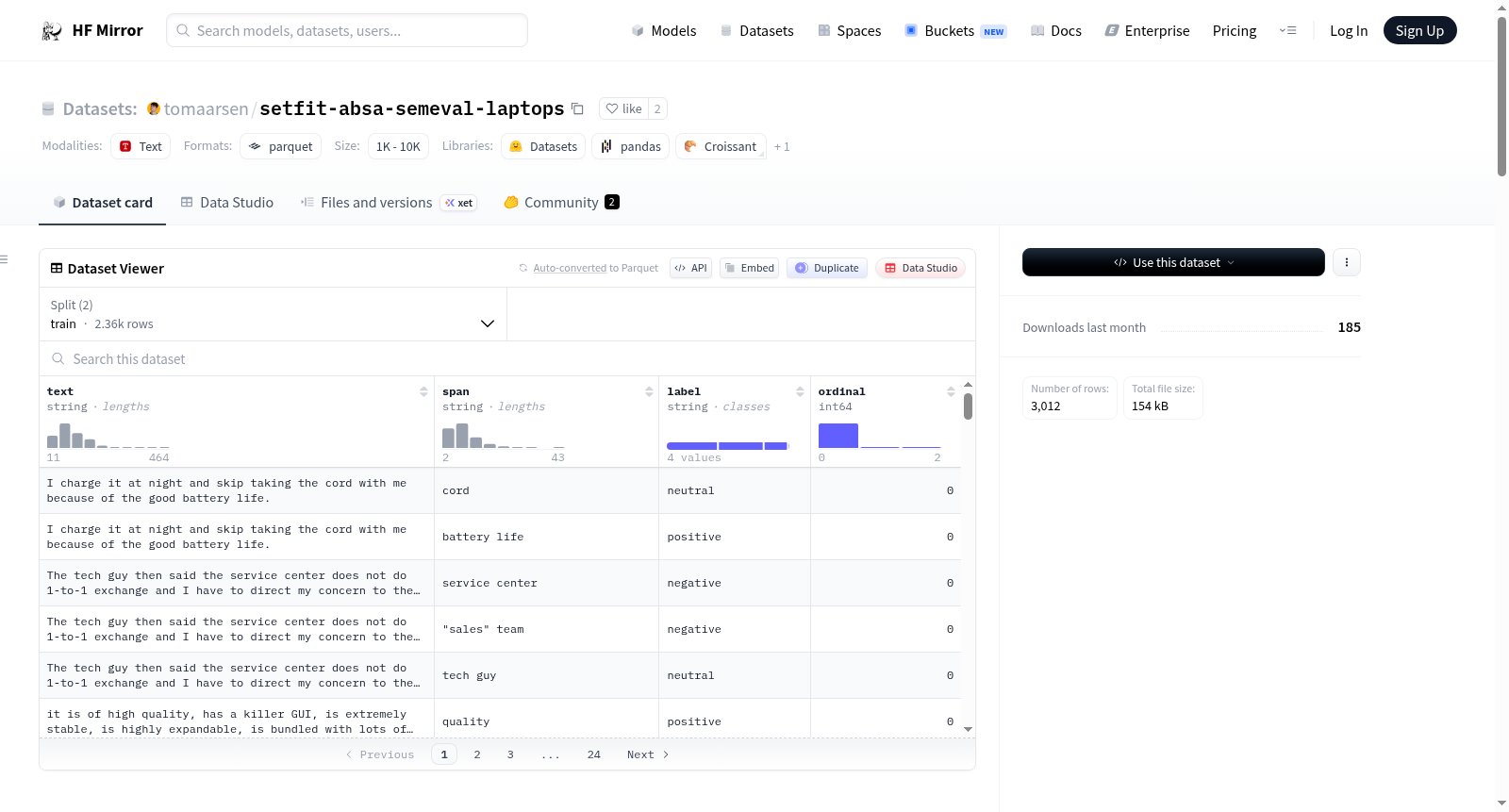
An example of "train" looks as follows.
```json
{"text": "I charge it at night and skip taking the cord with me because of the good battery life.", "span": "cord", "label": "neutral", "ordinal": 0}
{"text": "I charge it at night and skip taking the cord with me because of the good battery life.", "span": "battery life", "label": "positive", "ordinal": 0}
{"text": "The tech guy then said the service center does not do 1-to-1 exchange and I have to direct my concern to the \"sales\" team, which is the retail shop which I bought my netbook from.", "span": "service center", "label": "negative", "ordinal": 0}
{"text": "The tech guy then said the service center does not do 1-to-1 exchange and I have to direct my concern to the \"sales\" team, which is the retail shop which I bought my netbook from.", "span": "\"sales\" team", "label": "negative", "ordinal": 0}
{"text": "The tech guy then said the service center does not do 1-to-1 exchange and I have to direct my concern to the \"sales\" team, which is the retail shop which I bought my netbook from.", "span": "tech guy", "label": "neutral", "ordinal": 0}
```
### Data Fields
The data fields are the same among all splits.
- `text`: a `string` feature.
- `span`: a `string` feature showing the aspect span from the text.
- `label`: a `string` feature showing the polarity of the aspect span.
- `ordinal`: an `int64` feature showing the n-th occurrence of the span in the text. This is useful for if the span occurs within the same text multiple times.
### Data Splits
| name |train|test|
|---------|----:|---:|
|tomaarsen/setfit-absa-semeval-laptops|2358|654|
### Training ABSA models using SetFit ABSA
To train using this dataset, first install the SetFit library:
```bash
pip install setfit
```
And then you can use the following script as a guideline of how to train an ABSA model on this dataset:
```python
from setfit import AbsaModel, AbsaTrainer, TrainingArguments
from datasets import load_dataset
from transformers import EarlyStoppingCallback
# You can initialize a AbsaModel using one or two SentenceTransformer models, or two ABSA models
model = AbsaModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
# The training/eval dataset must have `text`, `span`, `polarity`, and `ordinal` columns
dataset = load_dataset("tomaarsen/setfit-absa-semeval-laptops")
train_dataset = dataset["train"]
eval_dataset = dataset["test"]
args = TrainingArguments(
output_dir="models",
use_amp=True,
batch_size=256,
eval_steps=50,
save_steps=50,
load_best_model_at_end=True,
)
trainer = AbsaTrainer(
model,
args=args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
callbacks=[EarlyStoppingCallback(early_stopping_patience=5)],
)
trainer.train()
metrics = trainer.evaluate(eval_dataset)
print(metrics)
trainer.push_to_hub("tomaarsen/setfit-absa-laptops")
```
You can then run inference like so:
```python
from setfit import AbsaModel
# Download from Hub and run inference
model = AbsaModel.from_pretrained(
"tomaarsen/setfit-absa-laptops-aspect",
"tomaarsen/setfit-absa-laptops-polarity",
)
# Run inference
preds = model([
"Boots up fast and runs great!",
"The screen shows great colors.",
])
```
### Citation Information
```bibtex
@inproceedings{pontiki-etal-2014-semeval,
title = "{S}em{E}val-2014 Task 4: Aspect Based Sentiment Analysis",
author = "Pontiki, Maria and
Galanis, Dimitris and
Pavlopoulos, John and
Papageorgiou, Harris and
Androutsopoulos, Ion and
Manandhar, Suresh",
editor = "Nakov, Preslav and
Zesch, Torsten",
booktitle = "Proceedings of the 8th International Workshop on Semantic Evaluation ({S}em{E}val 2014)",
month = aug,
year = "2014",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/S14-2004",
doi = "10.3115/v1/S14-2004",
pages = "27--35",
}
```
数据集信息:
特征:
- 名称: text
数据类型: 字符串(string)
- 名称: span
数据类型: 字符串(string)
- 名称: label
数据类型: 字符串(string)
- 名称: ordinal
数据类型: 64位整数(int64)
划分集:
- 名称: train(训练集)
字节数: 335243
样本量: 2358
- 名称: test(测试集)
字节数: 76698
样本量: 654
下载大小: 146971
总数据集大小: 411941
配置项:
- 配置名称: default(默认配置)
数据文件:
- 划分集: train(训练集)
路径: data/train-*
- 划分集: test(测试集)
路径: data/test-*
# 数据集卡片:`tomaarsen/setfit-absa-semeval-laptops`
### 数据集概述
本数据集包含SemEval-2014任务4中的人工标注笔记本电脑评论,格式适配[SetFit](https://github.com/huggingface/setfit)的基于方面的情感分析(Aspect-Based Sentiment Analysis, ABSA)任务。更多细节可参考https://aclanthology.org/S14-2004/
### 数据样例
训练集的一个示例如下:
json
{"text": "I charge it at night and skip taking the cord with me because of the good battery life.", "span": "cord", "label": "neutral", "ordinal": 0}
{"text": "I charge it at night and skip taking the cord with me because of the good battery life.", "span": "battery life", "label": "positive", "ordinal": 0}
{"text": "The tech guy then said the service center does not do 1-to-1 exchange and I have to direct my concern to the "sales" team, which is the retail shop which I bought my netbook from.", "span": "service center", "label": "negative", "ordinal": 0}
{"text": "The tech guy then said the service center does not do 1-to-1 exchange and I have to direct my concern to the "sales" team, which is the retail shop which I bought my netbook from.", "span": ""sales" team", "label": "negative", "ordinal": 0}
{"text": "The tech guy then said the service center does not do 1-to-1 exchange and I have to direct my concern to the "sales" team, which is the retail shop which I bought my netbook from.", "span": "tech guy", "label": "neutral", "ordinal": 0}
### 数据字段
所有划分集的数据字段均保持统一:
- `text`:字符串类型特征,代表原始评论文本
- `span`:字符串类型特征,用于标注文本中的**方面跨度(Aspect Span)**,即待分析情感的目标片段
- `label`:字符串类型特征,代表该方面跨度的情感极性(Polarity)
- `ordinal`:64位整数特征,用于标记该跨度在当前文本中出现的序号,当同一文本中存在多个相同跨度时可用于区分不同实例
### 数据划分
| 数据集名称 | 训练集样本量 | 测试集样本量 |
|---------|----:|---:|
|`tomaarsen/setfit-absa-semeval-laptops`|2358|654|
### 使用SetFit ABSA训练ABSA模型
若需基于本数据集训练模型,请先安装SetFit库:
bash
pip install setfit
随后可参考以下脚本完成该数据集上的ABSA模型训练:
python
from setfit import AbsaModel, AbsaTrainer, TrainingArguments
from datasets import load_dataset
from transformers import EarlyStoppingCallback
# You can initialize a AbsaModel using one or two SentenceTransformer models, or two ABSA models
model = AbsaModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
# The training/eval dataset must have `text`, `span`, `polarity`, and `ordinal` columns
dataset = load_dataset("tomaarsen/setfit-absa-semeval-laptops")
train_dataset = dataset["train"]
eval_dataset = dataset["test"]
args = TrainingArguments(
output_dir="models",
use_amp=True,
batch_size=256,
eval_steps=50,
save_steps=50,
load_best_model_at_end=True,
)
trainer = AbsaTrainer(
model,
args=args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
callbacks=[EarlyStoppingCallback(early_stopping_patience=5)],
)
trainer.train()
metrics = trainer.evaluate(eval_dataset)
print(metrics)
trainer.push_to_hub("tomaarsen/setfit-absa-laptops")
你可按如下方式执行推理:
python
from setfit import AbsaModel
# Download from Hub and run inference
model = AbsaModel.from_pretrained(
"tomaarsen/setfit-absa-laptops-aspect",
"tomaarsen/setfit-absa-laptops-polarity",
)
# Run inference
preds = model([
"Boots up fast and runs great!",
"The screen shows great colors.",
])
### 引用信息
bibtex
@inproceedings{pontiki-etal-2014-semeval,
title = "{S}em{E}val-2014 Task 4: Aspect Based Sentiment Analysis",
author = "Pontiki, Maria and
Galanis, Dimitris and
Pavlopoulos, John and
Papageorgiou, Harris and
Androutsopoulos, Ion and
Manandhar, Suresh",
editor = "Nakov, Preslav and
Zesch, Torsten",
booktitle = "Proceedings of the 8th International Workshop on Semantic Evaluation ({S}em{E}val 2014)",
month = aug,
year = "2014",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/S14-2004",
doi = "10.3115/v1/S14-2004",
pages = "27--35",
}