---
configs:
- config_name: whisper_v1
data_files:
- split: original
path: whisper_v1/**
- split: en
path: whisper_v1_en/**
- config_name: whisper_v2
data_files:
- split: original
path: whisper_v2/**
- split: en
path: whisper_v3_en/**
- config_name: whisper_v3
data_files:
- split: original
path: whisper_v3/**
- split: en
path: whisper_v3_en/**
task_categories:
- summarization
- translation
license: cc-by-4.0
size_categories:
- 10M<n<100M
language:
- en
- es
- ru
- de
- fr
- tr
- it
- pl
- bs
- hu
tags:
- SoccerNet
- synthetic
---
[**[Paper]**](https://arxiv.org/abs/2405.07354) | [**[GitHub]**](https://github.com/SoccerNet/SN-Echoes)
# Dataset Card for SoccerNet-Echoes
This dataset card aims to provide comprehensive details for the SoccerNet-Echoes dataset, an audio commentary dataset for soccer games.
## Dataset Details
### Dataset Description
SoccerNet-Echoes is an audio commentary dataset for soccer games, curated by SimulaMet under the AI-Storyteller project. It is funded by the Research Council of Norway (project number 346671) and shared by the SoccerNet team. The dataset supports multiple languages, including English, Spanish, Russian, German, French, Turkish, Italian, Polish, Bosnian, and Hungarian, and is licensed under CC BY 4.0.
- **Curated by:** [SimulaMet](https://www.simulamet.no), HOST Department (AI-Storyteller project)
- **Funded by:** Research Council of Norway, project number 346671
- **Shared by:** [SoccerNet Team](https://www.soccer-net.org)
- **Language(s) (NLP):** English, Spanish, Russian, German, French, Turkish, Italian, Polish, Bosnian, Hungarian
- **License:** CC BY 4.0
### Dataset Sources
- **Homepage:** [GitHub - SoccerNet-Echoes](https://github.com/SoccerNet/SN-Echoes). **Please check for more information, codes, and updates.**
- **Paper:** [SoccerNet-Echoes: A Soccer Game Audio Commentary Dataset](https://arxiv.org/abs/2405.07354)
- **Demo:** None
## Uses
### Direct Use
The dataset is primarily intended for:
- **Multimodal Event Detection:** Combining audio cues with visual data for improved event detection in sports videos.
- **Game Summarization:** Using automatic speech recognition (ASR) transcriptions to aid in summarizing soccer games.
### Out-of-Scope Use
The dataset is not intended for:
- **Medical Diagnosis:** The dataset is not suitable for medical applications.
- **Non-Sporting Event Analysis:** The dataset is tailored for soccer and might not generalize well to other types of events without further modification.
## Dataset Structure
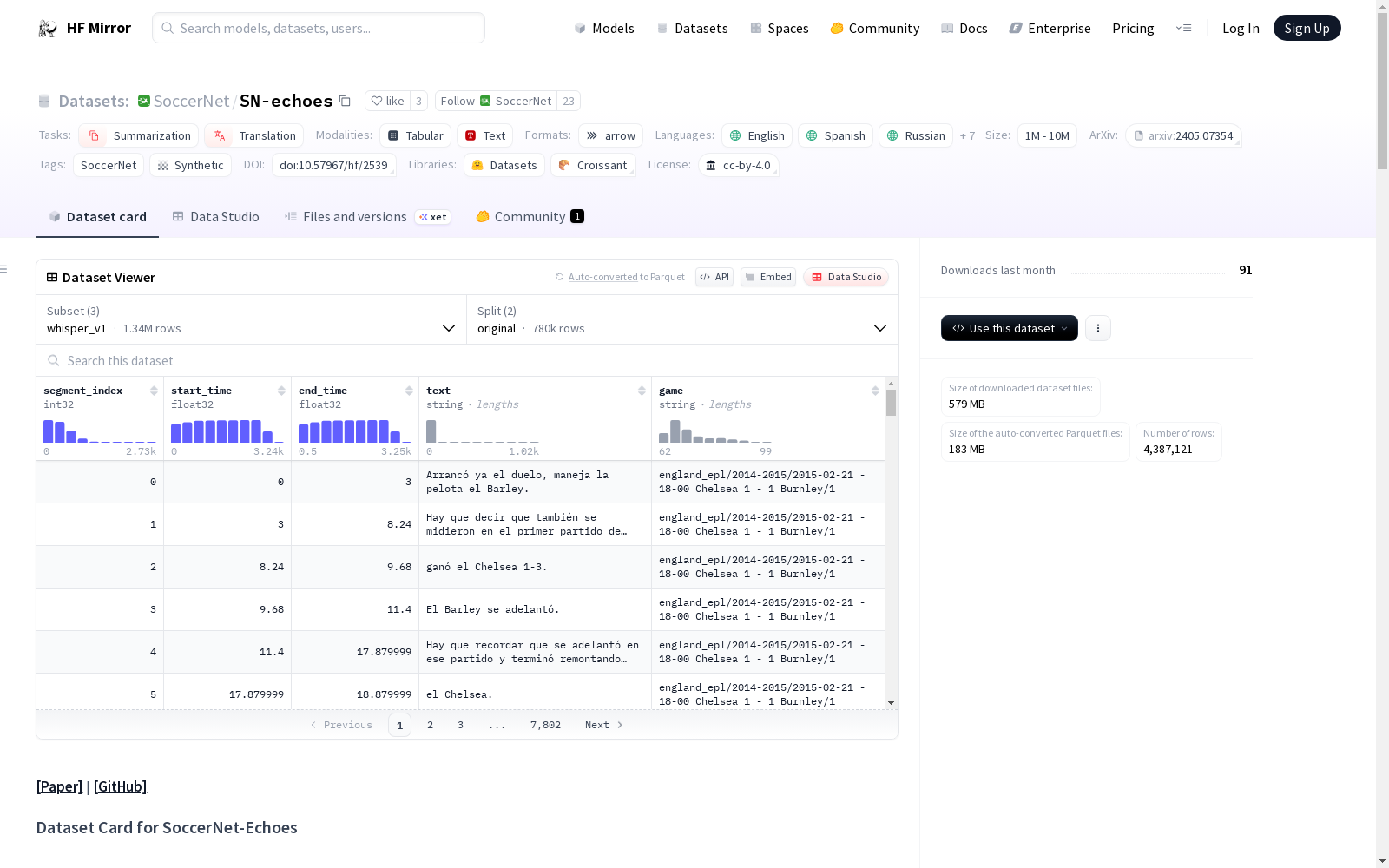
The dataset comprises transcriptions of soccer game commentaries using various Whisper ASR models and translations of non-English commentaries into English using Google Translate.
This table structure in HuggingFace has five columns for segment index, start and end times, the text (either transcribed or translated), and the game path (represented as a string).
This is divided into three subsets (v1, v2, and v3 of Whisper versions), with each subset further split into "original" (ASR-generated) and "en" (English translated).
The dataset structure in a hierarchical directory and JSON format, following other SoccerNet data resources can be found at [https://github.com/SoccerNet/sn-echoes](https://github.com/SoccerNet/sn-echoes).
Please note that this HuggingFace dataset is mirrored from the Dataset folder in GitHub with a conversion script.
## Dataset Creation
### Curation Rationale
The dataset was curated to enhance the SoccerNet dataset with automatic speech recognition (ASR) transcriptions and translations of non-English commentaries into English using Google Translate, enabling a richer and more integrated understanding of soccer games.
### Source Data
#### Data Collection and Processing
Audios were collected from soccer game broadcast videos in the SoccerNet dataset. The audio was transcribed using multiple Whisper ASR models (large-v1, large-v2, and large-v3) to create a comprehensive transcription dataset.
Google Translate was used for the translations of non-English commentaries into English.
#### Who are the source data producers?
The source data producers are soccer game broadcasters and commentators.
### Annotations
#### Annotation Process
The transcriptions were automatically generated by Whisper ASR models. Google Translate was used for the translations of non-English commentaries into English.
Human verification and corrections of transcriptions are planned for future work.
#### Who are the annotators?
- Whisper ASR models (transcriptions)
- Google Translate (translations)
- Authors/Humans (for verifying game halves laking game audio or commentary)
#### Personal and Sensitive Information
The dataset contains publicly available soccer game commentary, which is not considered sensitive. It does not include personal data about individuals outside of the context of the game.
## Bias, Risks, and Limitations
- **Transcription Accuracy:** ASR models may introduce errors in transcription.
- **Hallucinations:** Repetition of phrases, especially in noisy environments, can degrade transcription quality.
- **Audio Quality:** Variability in audio quality can impact transcription accuracy.
- **Human Verification:** Lack of human-verified annotations in the current dataset.
### Recommendations
Users should be aware of potential biases and limitations, such as transcription errors and hallucinations. Advanced audio pre-processing and human verification can help mitigate these issues.
### Filtering Hallucinations
Users should be aware of transcription errors and hallucinations. The most occurring problem is the unwarranted repetition of phrases and words, especially with audio inputs lacking human speech, being excessively noisy, or containing music. These conditions challenge the models’ transcription accuracy but can be mitigated by a simple filtering approach: removing consecutive entries with the same text and keeping only the first occurrence of each unique text.
It is strongly advised to use consecutive entries filtering along with the Mixed Selection approach to get a better ASR for downstream applications.
Please refer to the related section on [GitHub](https://github.com/SoccerNet/SN-Echoes) to see our suggested way of accomplishing this.
## Citation
**BibTeX:**
```bibtex
@article{gautam2024soccernet,
author = {Gautam, Sushant and Sarkhoosh, Mehdi Houshmand and Held, Jan and Midoglu, Cise and Cioppa, Anthony and Giancola, Silvio and Thambawita, Vajira and Riegler, Michael A. and Halvorsen, P{\aa}l and Shah, Mubarak},
title = {{SoccerNet-Echoes: A Soccer Game Audio Commentary Dataset}},
journal = {arXiv},
year = {2024},
month = may,
eprint = {2405.07354},
doi = {10.48550/arXiv.2405.07354}
}
```
**APA:**
Gautam, S., Sarkhoosh, M. H., Held, J., Midoglu, C., Cioppa, A., Giancola, S., ...Shah, M. (2024). SoccerNet-Echoes: A Soccer Game Audio Commentary Dataset. arXiv, 2405.07354. Retrieved from https://arxiv.org/abs/2405.07354v1
## Glossary
- **ASR (Automatic Speech Recognition):** Technology that converts spoken language into text.
- **Multimodal Analysis:** Combining multiple types of data, such as audio and visual, for more comprehensive analysis.
- **Whisper ASR Models:** A set of automatic speech recognition models developed by OpenAI.
## More Information
For additional details, visit the [SoccerNet-echoes GitHub repository](https://github.com/SoccerNet/SN-echoes) or contact the authors of the dataset.
## Dataset Card Authors
- Sushant Gautam, sushant@simula.no
## Dataset Card Contact
- Sushant Gautam, sushant@simula.no
配置项:
- 配置名称:whisper_v1
数据文件:
- 拆分集:original(原始转录集)
路径:whisper_v1/**
- 拆分集:en(英文译制版)
路径:whisper_v1_en/**
- 配置名称:whisper_v2
数据文件:
- 拆分集:original(原始转录集)
路径:whisper_v2/**
- 拆分集:en(英文译制版)
路径:whisper_v3_en/**
- 配置名称:whisper_v3
数据文件:
- 拆分集:original(原始转录集)
路径:whisper_v3/**
- 拆分集:en(英文译制版)
路径:whisper_v3_en/**
任务类别:
- 摘要生成
- 机器翻译
许可证:cc-by-4.0
数据规模:
- 1000万 < 样本数 < 1亿
语言:
- 英语(en)
- 西班牙语(es)
- 俄语(ru)
- 德语(de)
- 法语(fr)
- 土耳其语(tr)
- 意大利语(it)
- 波兰语(pl)
- 波斯尼亚语(bs)
- 匈牙利语(hu)
标签:
- SoccerNet
- 合成数据集
[**[论文]**](https://arxiv.org/abs/2405.07354) | [**[GitHub仓库]**](https://github.com/SoccerNet/SN-Echoes)
# SoccerNet-Echoes 数据集卡片
本数据集卡片旨在详尽说明SoccerNet-Echoes数据集——一款足球赛事音频解说数据集。
## 数据集详情
### 数据集概述
SoccerNet-Echoes 是一款面向足球赛事的音频解说数据集,由SimulaMet在AI-Storyteller项目框架下整理打造。本数据集由挪威研究理事会资助(项目编号:346671),并由SoccerNet团队发布。数据集支持英语、西班牙语、俄语、德语、法语、土耳其语、意大利语、波兰语、波斯尼亚语及匈牙利语共10种语言,采用CC BY 4.0许可证进行开源共享。
- **整理方:** [SimulaMet](https://www.simulamet.no),HOST研究部(AI-Storyteller项目)
- **资助方:** 挪威研究理事会,项目编号:346671
- **发布方:** [SoccerNet团队](https://www.soccer-net.org)
- **自然语言处理适用语言:** 英语、西班牙语、俄语、德语、法语、土耳其语、意大利语、波兰语、波斯尼亚语、匈牙利语
- **许可证:** CC BY 4.0
### 数据集来源
- **主页:** [GitHub - SoccerNet-Echoes](https://github.com/SoccerNet/SN-Echoes)。**如需获取更多信息、代码及更新内容,请访问该页面。**
- **相关论文:** [SoccerNet-Echoes:一款足球赛事音频解说数据集](https://arxiv.org/abs/2405.07354)
- **演示示例:** 无
## 数据集用途
### 直接用途
本数据集主要面向以下应用场景:
- **多模态事件检测:** 融合音频线索与视觉数据,以提升体育赛事视频中的事件检测精度。
- **赛事摘要生成:** 借助自动语音识别(Automatic Speech Recognition, ASR)生成的转录文本,辅助完成足球赛事的自动摘要工作。
### 不适用场景
本数据集不适用于以下场景:
- **医疗诊断:** 本数据集无法应用于医疗相关领域。
- **非体育赛事分析:** 本数据集专为足球赛事设计,未经额外适配难以泛化至其他类型的赛事分析任务。
## 数据集结构
本数据集包含基于多款Whisper自动语音识别模型生成的足球赛事解说转录文本,以及依托谷歌翻译完成的非英语解说文本英译版本。
本数据集在Hugging Face平台采用表格结构,共包含5个字段:片段索引、起始时间、结束时间、文本内容(转录或翻译结果)以及赛事路径(以字符串形式表示)。
数据集分为三个子集(对应Whisper模型的v1、v2、v3版本),每个子集进一步划分为`original`(原始转录集)与`en`(英文译制版)两类拆分集。
本数据集采用层级目录与JSON格式存储,可参考其他SoccerNet数据集资源的结构,详情可访问[https://github.com/SoccerNet/sn-echoes](https://github.com/SoccerNet/sn-echoes)。
请注意,本Hugging Face数据集是通过转换脚本从GitHub的Dataset文件夹镜像而来。
## 数据集构建
### 整理初衷
本数据集的整理初衷是为SoccerNet数据集补充自动语音识别(Automatic Speech Recognition, ASR)转录文本,以及依托谷歌翻译完成的非英语解说英译版本,从而实现对足球赛事更全面、更一体化的理解与分析。
### 源数据
#### 数据采集与处理流程
源音频采集自SoccerNet数据集中的足球赛事转播视频。研究团队依托多款Whisper自动语音识别模型(large-v1、large-v2及large-v3)对音频进行转录,构建了覆盖全面的转录数据集。
非英语解说文本的英译工作则通过谷歌翻译完成。
#### 源数据生产者
本数据集的源数据生产者为足球赛事转播方与解说嘉宾。
### 标注情况
#### 标注流程
转录文本均由Whisper自动语音识别模型自动生成,非英语解说的英译工作由谷歌翻译完成。
目前暂未进行人工校验与修正,相关工作已纳入未来规划。
#### 标注者
- Whisper自动语音识别模型(转录生成)
- 谷歌翻译(英译工作)
- 数据集作者/人工标注者(用于校验缺失音频或解说的赛事片段)
#### 个人与敏感信息说明
本数据集包含公开可获取的足球赛事解说内容,不属于敏感信息范畴,且未包含赛事场景之外的个人隐私数据。
## 偏差、风险与局限性
- **转录准确性:** 自动语音识别模型可能在转录过程中引入错误。
- **幻觉问题:** 短语重复现象(尤其在嘈杂环境下)会降低转录质量。
- **音频质量:** 音频质量的差异性会对转录精度产生影响。
- **人工校验缺失:** 当前数据集暂未经过人工校验标注。
### 改进建议
用户应知晓本数据集存在的潜在偏差与局限性,例如转录错误与幻觉问题。可通过优化音频预处理流程与引入人工校验的方式缓解上述问题。
### 幻觉问题过滤方案
用户应留意转录错误与幻觉问题。本数据集最常见的问题为无意义的短语与词汇重复,尤其出现在无人声输入、背景噪音过大或包含音乐的音频片段中。此类场景会降低模型的转录精度,但可通过简单的过滤方案缓解:移除连续重复的文本条目,仅保留每个唯一文本的首次出现结果。
强烈建议将连续条目过滤方案与混合选择(Mixed Selection)方法结合使用,以优化下游任务所用的自动语音识别结果。
相关实现方案可参考GitHub仓库[https://github.com/SoccerNet/SN-Echoes](https://github.com/SoccerNet/SN-Echoes)中的对应章节。
## 引用格式
**BibTeX格式:**
bibtex
@article{gautam2024soccernet,
author = {Gautam, Sushant and Sarkhoosh, Mehdi Houshmand and Held, Jan and Midoglu, Cise and Cioppa, Anthony and Giancola, Silvio and Thambawita, Vajira and Riegler, Michael A. and Halvorsen, Pål and Shah, Mubarak},
title = {{SoccerNet-Echoes: A Soccer Game Audio Commentary Dataset}},
journal = {arXiv},
year = {2024},
month = may,
eprint = {2405.07354},
doi = {10.48550/arXiv.2405.07354}
}
**APA格式:**
Gautam, S., Sarkhoosh, M. H., Held, J., Midoglu, C., Cioppa, A., Giancola, S., ...Shah, M. (2024). SoccerNet-Echoes:一款足球赛事音频解说数据集. arXiv, 2405.07354. 检索自 https://arxiv.org/abs/2405.07354v1
## 术语表
- **ASR(自动语音识别,Automatic Speech Recognition):** 将口语转换为文本的技术。
- **多模态分析:** 融合多种类型的数据(如音频与视觉数据)以实现更全面的分析。
- **Whisper自动语音识别模型:** 由OpenAI开发的一系列自动语音识别模型。
## 更多信息
如需获取更多详情,请访问[SoccerNet-echoes GitHub仓库](https://github.com/SoccerNet/SN-echoes)或联系数据集作者。
## 数据集卡片作者
- Sushant Gautam,邮箱:sushant@simula.no
## 数据集卡片联系方式
- Sushant Gautam,邮箱:sushant@simula.no