video-games
收藏Hugging Face2026-04-09 更新2026-04-10 收录
下载链接:
https://huggingface.co/datasets/itaimorag/video-games
下载链接
链接失效反馈官方服务:
资源简介:
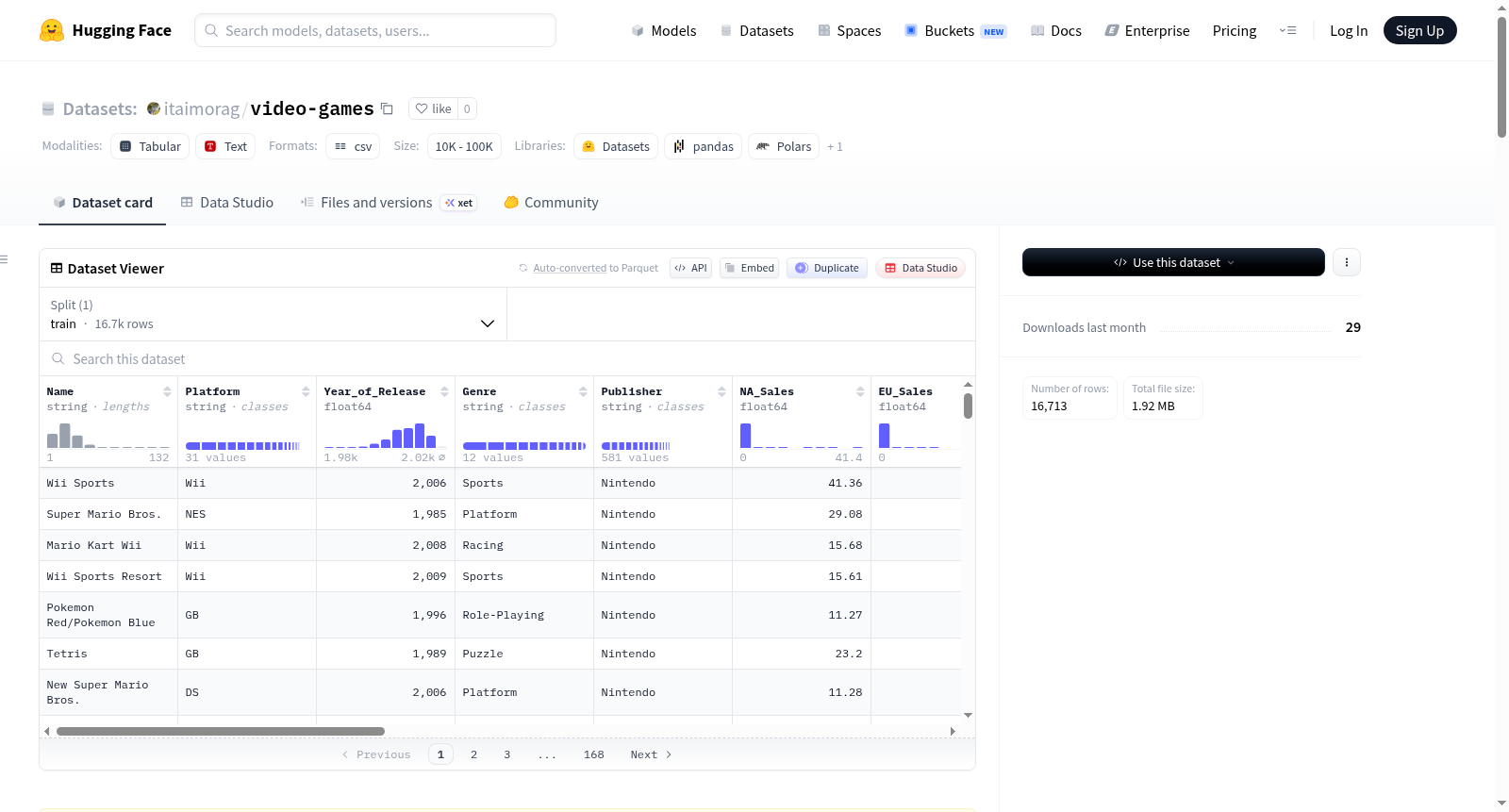
该数据集包含历史视频游戏销售数据,旨在通过探索性数据分析(EDA)技术研究游戏类型、评论接受度和全球销售表现之间的关系。数据集每条记录代表一个视频游戏发布,包含游戏标识符(名称、平台、发布年份、出版商)、分类分组(如动作、体育、角色扮演等)、财务指标(北美、欧洲、日本和全球销售额,以百万单位计)和接受度指标(专业评论家评分和用户评分)。数据集经过清洗,处理了未来日期、'tbd'值、缺失值和异常值,保留了真实的市场差异。适用于分析视频游戏消费者行为、预测销售表现等任务。数据集的时间范围截至2016年,未涵盖纯数字分销和现代实时服务游戏的兴起。
创建时间:
2026-04-01
搜集汇总
数据集介绍
构建方式
在电子游戏产业研究领域,video-games数据集通过系统收集1980年至2016年间发布的电子游戏历史销售数据构建而成。数据整合了游戏标识信息,包括名称、发行平台、发行年份及发行商,并涵盖动作、体育、角色扮演等多种游戏类型。构建过程中,数据清洗环节移除了超出2016年的未来发行日期记录,确保历史准确性;用户评分中的“待定”值被转换为缺失值,而专业评分与用户评分中的大量缺失数据则被保留,以避免因插补引入偏差。极端销售异常值,如《Wii Sports》等热门作品,被视为市场真实反映予以保留,从而完整呈现了游戏行业高度依赖爆款产品的特性。
特点
该数据集的核心特点在于其多维度的属性覆盖,不仅包含北美、欧洲、日本及全球范围的销售数据,还整合了专业评论家评分与公众用户评分,为分析商业成功因素提供了丰富视角。数据的时间跨度长达三十余年,能够揭示游戏类型受欢迎程度的动态变迁,例如动作与体育类游戏在历史总销售额中占据主导,而射击类游戏在特定时期呈现显著增长。此外,数据集中存在大量评分缺失值,这反映了早期游戏缺乏现代评分体系的历史局限,要求使用者在分析时谨慎处理。数值特征间尺度差异显著,例如全球销售额以百万计,而评分则限于百分制或十分制,这为后续机器学习应用中的特征标准化提出了明确需求。
使用方法
该数据集适用于探索性数据分析与预测建模等多种研究场景。使用者可首先进行数据清洗,依据文档建议处理异常时间戳与缺失值,并利用可视化工具如箱线图与热力图分析特征相关性及异常值分布。在构建预测模型,如预估全球销售额时,必须对数值特征进行标准化处理,应用StandardScaler或MinMaxScaler以消除量纲影响,确保距离型算法的稳定性。分析过程中应重点关注游戏类型、发行年代与评分等多维因素的交互作用,而非孤立变量,同时需注意数据集的时效性局限,其未涵盖2016年后数字分发与实时服务游戏的行业变革,因此结论主要适用于历史趋势分析。
背景与挑战
背景概述
视频游戏产业作为数字娱乐领域的核心组成部分,其商业成功模式一直是学术界与业界关注的焦点。Video Game Sales数据集由研究人员itay morag于2016年整理发布,旨在通过历史销售数据探索影响游戏商业表现的关键因素。该数据集涵盖了1980年至2016年间发布的游戏信息,包含游戏名称、平台、发行年份、发行商、游戏类型以及全球各地区的销售数据,同时整合了专业评论家评分与用户评分。其核心研究问题在于揭示游戏类型、发行时代与市场接受度之间的复杂关联,为游戏产业的市场趋势分析、消费者行为研究及商业预测提供了重要的实证基础,对娱乐经济学与数据驱动决策领域产生了深远影响。
当前挑战
该数据集所针对的领域问题在于解析视频游戏商业成功的多维度驱动因素,其挑战体现在如何从混杂的行业数据中分离出具有因果意义的变量,例如区分评论分数与销售业绩之间的相关性是否源于潜在的市场偏好或营销效应。在构建过程中,数据集面临多重挑战:一是历史数据的完整性不足,许多早期游戏缺乏系统的评分记录,导致大量缺失值无法通过常规插补方法处理,以免引入偏差;二是行业数据的极端性,如《Wii Sports》等现象级作品作为合法离群值,反映了市场的高度集中特性,要求分析方法必须保留真实方差而非简单剔除;三是数据时效性局限,数据集截至2016年,未能涵盖数字分发与实时服务模式兴起后的产业变革,限制了其对当代游戏生态的解释力。
常用场景
经典使用场景
在电子游戏产业分析领域,video-games数据集常被用于探索性数据分析,以揭示历史销售趋势与市场动态。研究者通过整合游戏类型、发行平台、评分及全球销量等多维度特征,系统评估不同变量间的关联性,例如分析动作类与体育类游戏如何长期主导市场份额,或考察特定时期射击类游戏的兴起如何反映消费者偏好的变迁。这类分析不仅描绘了产业演进的宏观图景,也为后续的预测建模奠定了数据基础。
衍生相关工作
围绕该数据集衍生的经典工作主要集中在销售预测模型与产业趋势分析。例如,多项研究采用机器学习算法,以游戏类型、评分及发行年份为特征,预测全球销量并评估模型准确性;同时,学者结合时间序列分析,深入探讨了游戏类型流行度的周期性变化及其与社会文化因素的关联。这些工作不仅拓展了娱乐产业的数据科学应用边界,也为跨学科研究如消费行为学与媒体经济学提供了丰富的案例素材。
数据集最近研究
最新研究方向
在电子游戏产业数据分析领域,video-games数据集为探索历史销售模式与市场动态提供了关键基础。当前研究前沿聚焦于利用机器学习模型预测游戏商业表现,通过整合流派、平台、发行年份及评分等多维特征,构建精准的销售预测框架。热点方向包括分析数字分发时代对传统销售数据的冲击,以及用户评分与专业评分的非线性关联对市场接受度的影响。这些研究不仅深化了对游戏产业成功因素的理解,还为发行商的风险评估与战略规划提供了数据驱动的决策支持,具有显著的商业与学术意义。
以上内容由遇见数据集搜集并总结生成


