PitchBench
收藏Hugging Face2026-05-07 更新2026-05-08 收录
下载链接:
https://huggingface.co/datasets/pitchbench-authors/PitchBench
下载链接
链接失效反馈官方服务:
资源简介:
PitchBench是一个用于测试音频语言模型(ALMs)在音高感知方面能力的基准数据集。该数据集包含29个受控实验,共计5,932个音频刺激样本,每个样本由音频片段、问题和答案组成。实验涵盖单音高识别、响度和持续时间变化下的音高识别、时间定位、和弦与音程识别、序列音高任务等多个层次的任务。数据集旨在评估模型在不同声学条件下的音高感知能力,包括音频效果、背景噪声、谐波饱和等复杂场景。每个实验配置都有明确的独立变量和评分标准,涉及19种音色和广泛的音高范围。数据集适用于音频分类和音频到文本的任务,采用CC-BY-4.0许可协议发布。
PitchBench is a benchmark dataset designed to evaluate the pitch perception capabilities of Audio Language Models (ALMs). It comprises 29 controlled experiments with a total of 5,932 audio stimulus samples, each consisting of an audio clip, a question, and an answer. The experiments cover various levels of tasks, including single-pitch identification, pitch recognition under variations in loudness and duration, temporal localization, chord and interval identification, and sequential pitch tasks. The dataset aims to assess model performance in pitch perception across different acoustic conditions, including complex scenarios with audio effects, background noise, and harmonic saturation. Each experiment configuration has clearly defined independent variables and scoring criteria, involving 19 timbres and a wide pitch range. The dataset is suitable for audio classification and audio-to-text tasks and is released under the CC-BY-4.0 license.
创建时间:
2026-05-05
搜集汇总
数据集介绍
构建方式
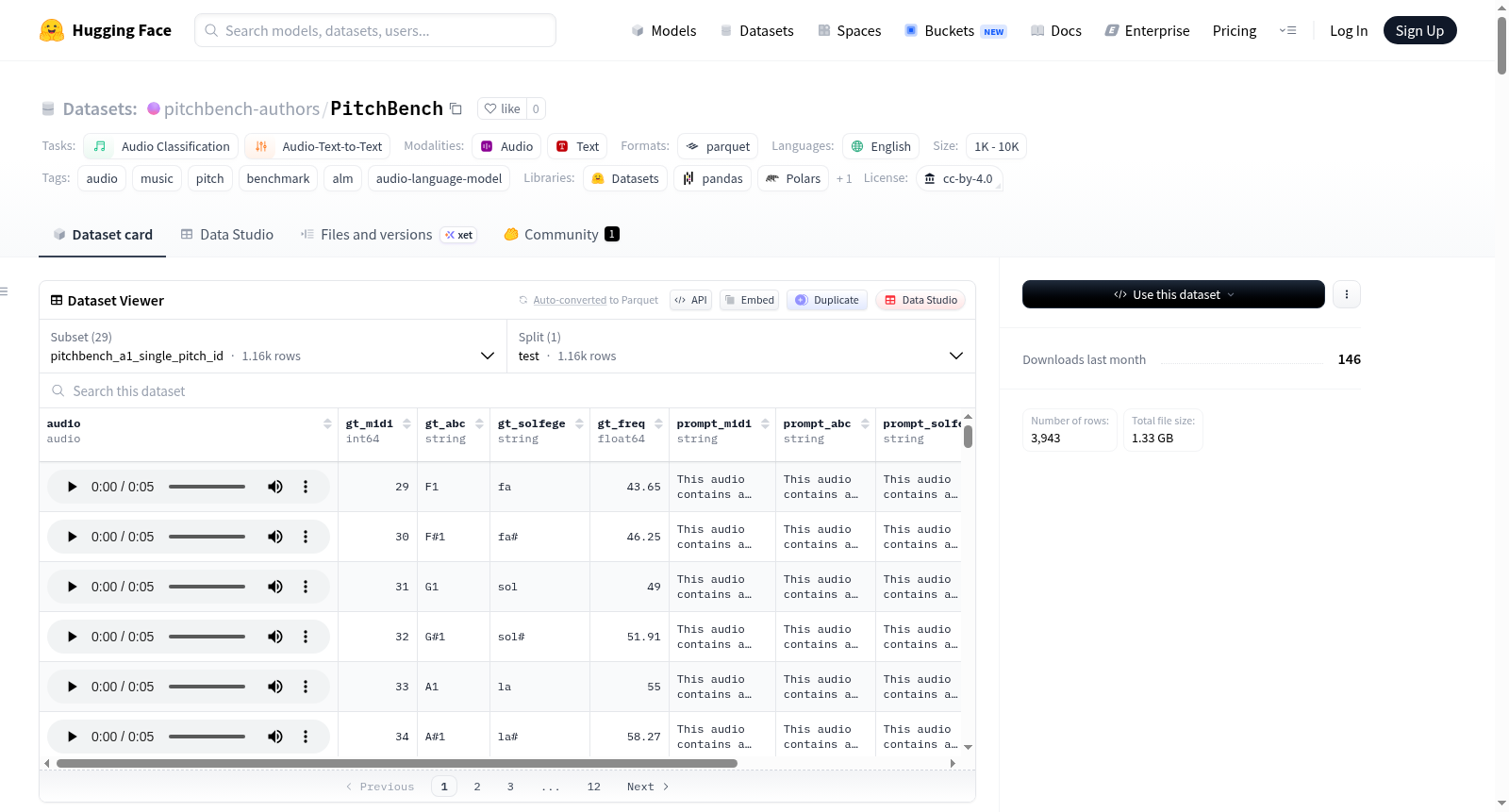
PitchBench数据集专为评估音频语言模型对音高的感知能力而设计,由29个受控实验构成,共计5932个测试样本。每个样本包含一个简短的WAV音频刺激、一个自然语言问题以及对应的真实答案。数据集构建时,音高素材源自19种音色库,涵盖4种合成波形与15种通用MIDI乐器,并采用10音高基准与5音高精简两种选择方案。实验分为六个层级,从原子级的单音识别到多声部旋律转录,系统性地控制响度、时长、背景噪声、和声饱和度等变量,确保测评的全面性与严谨性。
特点
该数据集最显著的特点在于其精细化的实验分层设计。从单音高识别到和弦感知,从时序定位到旋律轮廓追踪,每个子任务均针对特定的音高认知能力进行孤立测试。例如,A2与A3子集分别考察响度与时长变化对音高识别的影响,而E系列则引入音频效果、背景噪声等真实场景干扰。此外,每个刺激都提供MIDI整数、科学音高记号、固定唱名与频率四种标注格式,支持多维度评价模型输出。这种纵深覆盖与多格式兼容的特性,使PitchBench成为音高感知评估的综合性基准。
使用方法
用户可通过HuggingFace Datasets库便捷加载数据,每个实验使用独立的配置名,如'pitchbench_a1_single_pitch_id'。加载时指定split='test'即可获取测试集,每个样本包含'audio'字段与'prompt_*'问题字段及'gt_*'答案字段。对于需要双音频输入的子集(如d7b),数据集提供了'audio_1'与'audio_2'两列。用户可迭代所有配置名以批量评估模型在所有29个实验上的表现,默认评估指标为精确匹配准确率或特定容差下的计分规则。
背景与挑战
背景概述
PitchBench是一个于近期发布的音频语言模型(ALM)音高感知基准数据集,由相关研究机构创建,旨在系统性地评估当前最先进的音频语言模型在音高感知任务上的表现。核心研究问题聚焦于这些模型能否准确识别和区分音乐中的音高信息,包括单音识别、和弦分析、旋律轮廓追踪以及复杂音频环境下的音高提取等。该数据集通过29个受控实验、超过5900个音频样本,覆盖从原子级音高感知到多声部旋律线的多层次任务,为音频理解领域提供了一个全面的评估框架。其影响力在于揭示了现有模型在音乐感知方面的局限性,为未来音频语言模型的发展指明了方向,推动了音高感知研究从分类任务向更精细化、场景化的认知能力评估迈进。
当前挑战
PitchBench所解决的领域挑战在于,现有音频语言模型虽然在语音和通用音频理解上表现优异,但在精细的音高感知任务上存在显著不足,如微小的音高变化(1音分)、多声部旋律分离、不同音色和时长下的音高稳定性判断等。构建过程中面临的挑战包括:设计覆盖从单音到多声部、从纯净音到带噪环境、从离散到连续轮廓的29个差异化实验,确保每个实验的控制变量精确;合成包含19种音色(4种合成波形与15种GM乐器)的多样本音频,并在不同响度、时长、背景噪声条件下生成;建立严格的评分标准(如精确匹配、±250毫秒时间容差),以客观衡量模型性能,最终形成涵盖5,932个刺激样本的高质量基准数据集。
常用场景
经典使用场景
在音频语言模型(Audio Language Models, ALMs)的研究领域,音高感知能力的评估长期缺乏系统性的基准。PitchBench作为一项精心设计的评估基准,通过29个受控实验,全面探测模型在原子级音高识别、时序定位、和弦解析、旋律轮廓追踪以及复杂声学环境下的表现。其典型应用场景包括:衡量模型对单音音高的识别精度(跨越61个MIDI音高、19种音色、30分贝动态范围和50毫秒至60秒的时值跨度),评估模型在干扰条件下(如混响、背景噪声、谐波饱和)的鲁棒性,以及检验模型对和弦构成、音程关系、旋律走向等高级音乐结构的理解能力。
解决学术问题
该数据集有效解决了学术界在评估音频语言模型时,普遍存在的音高感知维度测试不系统、不全面的问题。具体来说,它填补了现有基准无法精细区分模型在不同音高任务上能力差异的空白。通过机制化地分解音高感知为原子识别、上下文感知、同步和序列处理、失真鲁棒性等子维度,PitchBench使得研究者能够诊断模型究竟是缺乏底层听觉编码能力,还是无法在复杂上下文中运用提取到的音高信息。其意义在于,为比较不同架构(如基于Transformer的ALM与传统卷积模型)在音高这一基础听觉属性上的真实表现提供了公平、可重复的测试标准,从而引导更有效的模型改进方向。
衍生相关工作
PitchBench的发布直接推动了音频理解领域中多方面的后续研究。一方面,它可以被用作标准的诊断工具,催生了大量针对特定子任务(如鲁棒音高识别或音乐结构解析)的模块化改进工作。另一方面,该数据集的高质量标注和细粒度评估框架,为开发能够同时处理时间定位与音高分类的联合模型提供了基准,推动了如音高与音符持续时间的联合预测任务的发展。此外,它也启发了一系列关于如何将频域特征(如分频带幅度谱)以更有效的方式注入Transformer模型的研究,从而直接提升模型在最困难的音高枚举和旋律线分离任务上的表现。
以上内容由遇见数据集搜集并总结生成


