Logo-2K+
收藏github2024-05-14 更新2024-05-31 收录
下载链接:
https://github.com/msn199959/Logo-2k-plus-Dataset
下载链接
链接失效反馈官方服务:
资源简介:
在本工作中,我们构建了一个大规模的标志数据集Logo-2K+,该数据集涵盖了来自真实世界标志图像的多样化标志类别。我们的标志数据集包含167,140张图像,分为10个根类别和2,341个子类别。
In this work, we have constructed a large-scale logo dataset, Logo-2K+, which encompasses a diverse range of logo categories derived from real-world logo images. Our logo dataset comprises 167,140 images, categorized into 10 root categories and 2,341 subcategories.
创建时间:
2019-09-07
原始信息汇总
Logo-2K+ Dataset Overview
Dataset Description
- Type: Large-scale logo dataset
- Contents: 167,140 images categorized into 10 root categories and 2,341 subcategories.
- Categories:
- Food
- Clothes
- Institution
- Accessories
- Transportation
- Electronic
- Necessities
- Cosmetic
- Leisure
- Medical
Dataset Statistics
| Root Category | Logos | Images |
|---|---|---|
| Food | 769 | 54,507 |
| Clothes | 286 | 20,413 |
| Institution | 238 | 17,103 |
| Accessories | 210 | 14,569 |
| Transportation | 203 | 14,719 |
| Electronic | 191 | 13,972 |
| Necessities | 182 | 13,205 |
| Cosmetic | 115 | 7,929 |
| Leisure | 99 | 7,338 |
| Medical | 48 | 3,385 |
| Total | 2,341 | 167,140 |
Download Links
- Baidu Drive: https://pan.baidu.com/s/1L_9JROsWSQEAznNiy-wTBQ (password: 945w)
- Google Drive: https://drive.google.com/open?id=1PTA24UTZcsnzXPN1gmV0_lRg3lMHqwp6
搜集汇总
数据集介绍
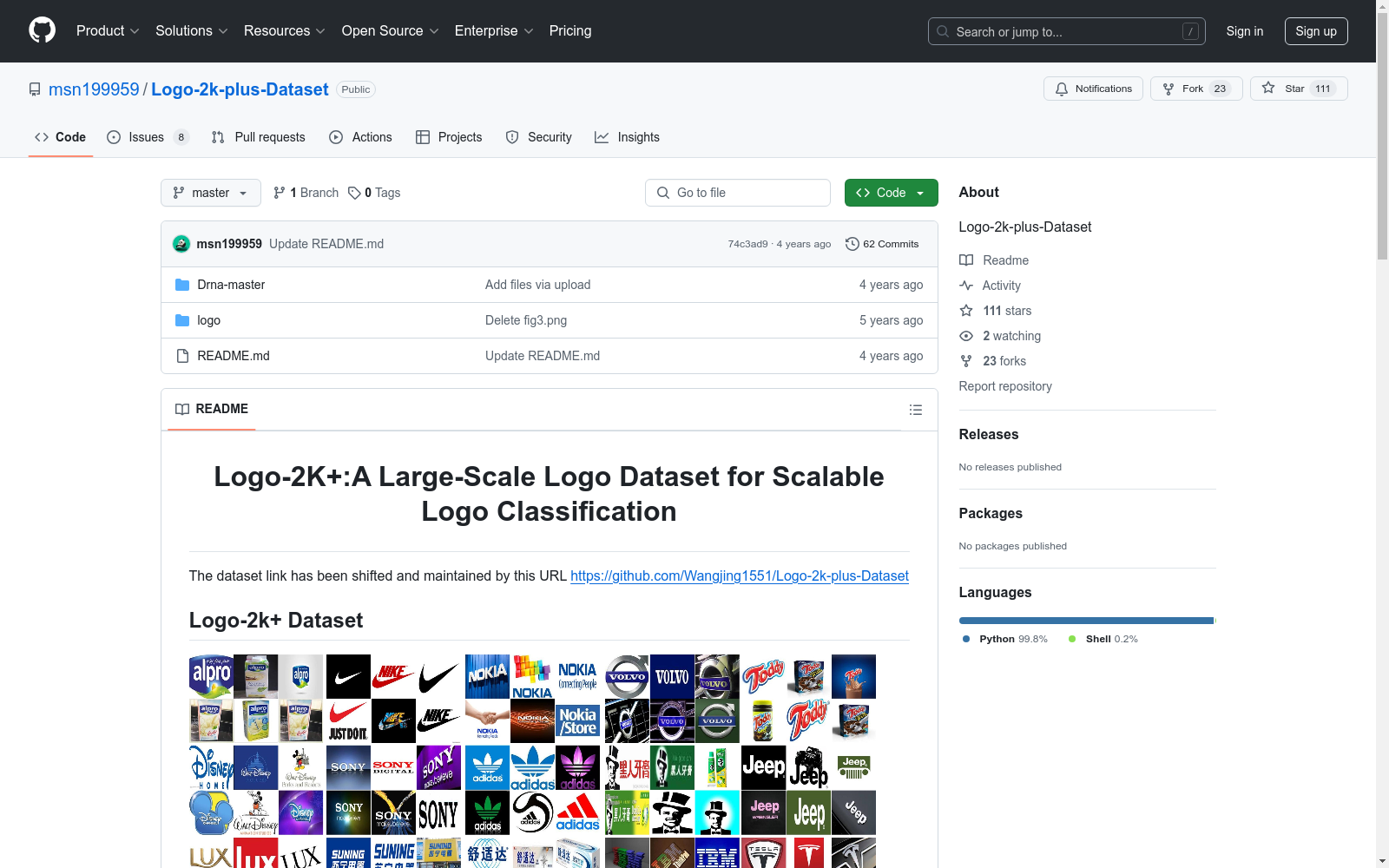
构建方式
在构建Logo-2K+数据集的过程中,研究团队精心收集了来自现实世界的大量标志图像,涵盖了广泛的类别。该数据集包含167,140张图像,分为10个根类别和2,341个子类别。每个根类别下又细分为多个子类别,如食品、服装、机构等,确保了数据集的多样性和广泛性。通过这种方式,Logo-2K+数据集为标志分类研究提供了丰富的资源。
特点
Logo-2K+数据集的主要特点在于其规模庞大且类别多样。数据集包含了2,341个不同的标志类别,涵盖了从食品到医疗等多个领域,确保了数据集的广泛应用性。此外,数据集的图像数量高达167,140张,为深度学习模型提供了充足的训练数据。这种多样性和规模使得Logo-2K+成为标志分类任务中的重要基准数据集。
使用方法
使用Logo-2K+数据集进行模型训练和测试时,用户需首先下载数据集并将其放置在指定目录下。随后,可以通过设置超参数文件来调整训练和测试的配置。训练过程中,用户可以运行`python train.py`进行模型训练,训练结果将保存在指定目录中。测试时,运行`python test.py`并指定测试模型即可完成测试。整个过程简单直观,适合各类研究人员和开发者使用。
背景与挑战
背景概述
在计算机视觉领域,标志(Logo)识别是一个具有重要应用价值的研究方向,尤其在品牌识别、广告监测和知识产权保护等方面。为了推动这一领域的发展,Wang等人于2020年构建了Logo-2K+数据集,这是一个大规模的标志图像数据集,涵盖了从现实世界中收集的2,341个类别的167,140张图像。该数据集不仅包含了多样化的标志类别,还细分为10个根类别,如食品、服装、电子产品等,为标志分类研究提供了丰富的资源。Logo-2K+的发布不仅填补了标志识别领域数据集的空白,还为相关算法的设计与评估提供了坚实的基础。
当前挑战
尽管Logo-2K+数据集为标志分类研究提供了丰富的资源,但其构建与应用仍面临诸多挑战。首先,标志图像的多样性带来了分类的复杂性,不同品牌和类别的标志在形状、颜色和风格上存在显著差异,这对算法的泛化能力提出了高要求。其次,数据集的构建过程中,如何确保标志图像的多样性和代表性,以及如何处理低质量或模糊的图像,都是亟待解决的问题。此外,标志识别在实际应用中还需应对光照、角度和背景干扰等现实场景中的挑战,这些都为标志分类算法的鲁棒性提出了更高的要求。
常用场景
经典使用场景
Logo-2K+数据集因其广泛的类别覆盖和大规模的图像数量,成为标志分类任务中的经典基准。研究者们常利用该数据集训练深度学习模型,以实现高效且准确的标志识别。通过分析不同类别标志的特征分布,模型能够学习到丰富的视觉模式,从而提升在实际应用中的分类性能。
实际应用
Logo-2K+数据集在实际应用中展现了广泛的应用潜力,尤其在品牌识别、广告监测和知识产权保护等领域。例如,在零售行业中,该数据集可用于自动识别货架上的品牌标志,提升库存管理的效率;在广告行业中,它可用于检测广告中的品牌露出,确保广告内容的合规性;在法律领域,它可用于快速识别侵权标志,保护品牌权益。
衍生相关工作
基于Logo-2K+数据集,研究者们开发了多种标志分类模型,如DRNA-Net等,这些模型在标志识别任务中表现出色。此外,该数据集还激发了关于标志检测、标志生成和标志风格迁移等方向的研究。这些衍生工作不仅丰富了标志识别领域的研究内容,还为实际应用提供了更多可能性。
以上内容由遇见数据集搜集并总结生成


