nehatarey/american_snacks
收藏Hugging Face2023-05-30 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/nehatarey/american_snacks
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
features:
- name: product_name
dtype: string
- name: ingredients
dtype: string
- name: reasons
dtype: string
splits:
- name: train
num_bytes: 13230
num_examples: 49
download_size: 7079
dataset_size: 13230
---
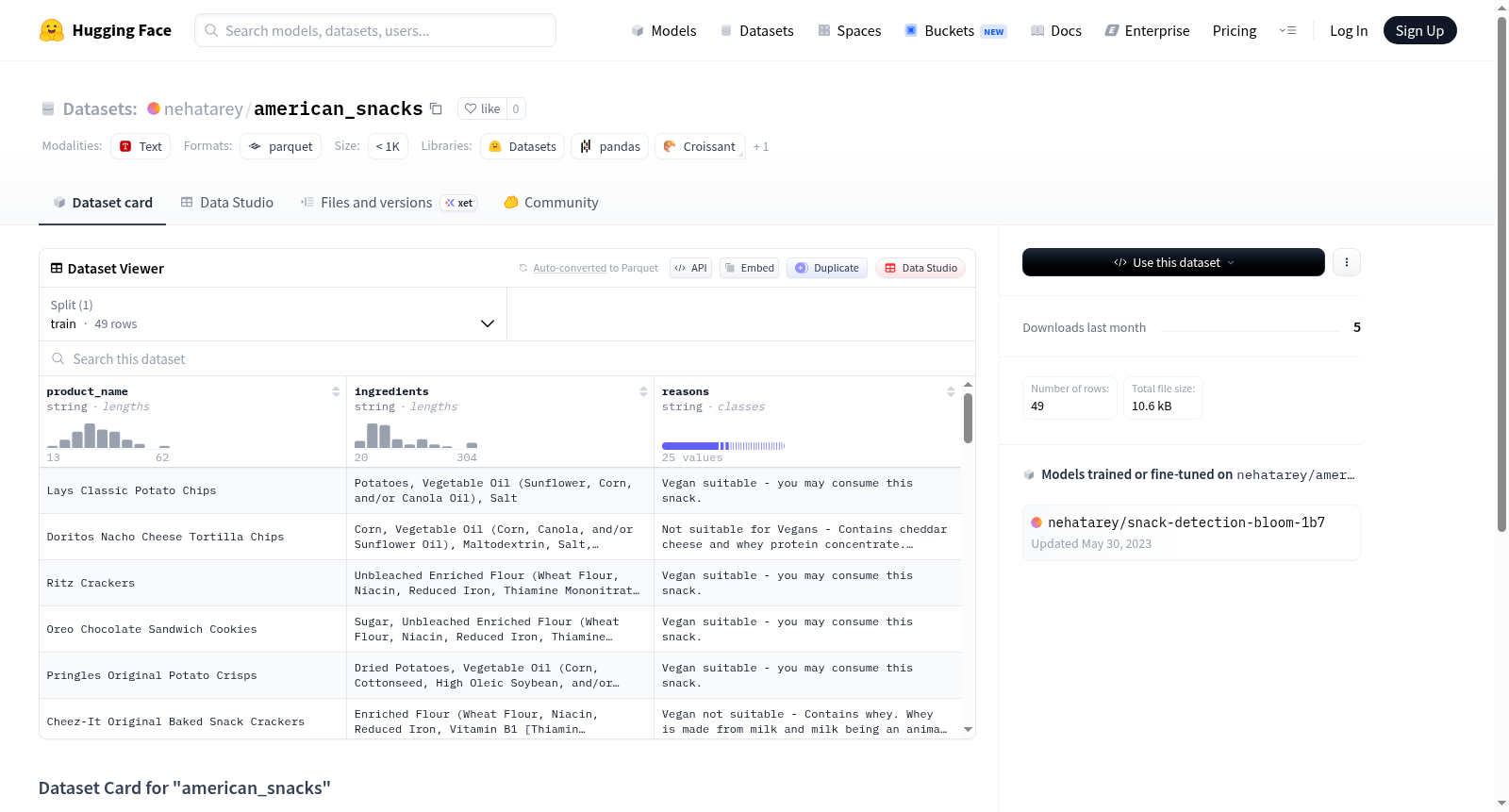
# Dataset Card for "american_snacks"
- This dataset contains a list of popular American snack items along with their ingredient list. Additionally, it also contains a column containing the reason if certain snack item is suitable for vegan/vegtarians based on certain ingredient.
- It has been generated using Open AI `gpt3.5-turbo` with prompt "please create me a dataset in csv format with 20 rows containing columns "product_name", "ingredients", "reasons". The "product_name" columns will contain 20 most common packaged snacks in the US with their full brand name. The "ingredients" column for each row will contain the respective snack's ingredient list. The "reasons" columns for each rows will contain a reason why that snack item is vegan suitable or not."
- The ingredient list may or may not be exhaustive.
- This is a synthetic dataset augmented by human (addtional verbiage in `reasons` column.
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
提供机构:
nehatarey
原始信息汇总
数据集概述
数据集名称
- 名称: american_snacks
数据集特征
- 特征列表:
- product_name: 字符串类型,包含美国最常见的20种包装零食及其完整品牌名称。
- ingredients: 字符串类型,包含各零食的成分列表。
- reasons: 字符串类型,包含各零食适合素食者的原因。
数据集结构
- 分割:
- train: 包含49个样本,数据集大小为13230字节。
数据集大小
- 下载大小: 7079字节
- 数据集大小: 13230字节
数据集生成
- 使用Open AI的
gpt3.5-turbo生成,原始请求为创建一个包含20行数据的CSV格式数据集,包含"product_name", "ingredients", "reasons"三个列。
数据集特点
- 成分列表可能不详尽。
- 数据集中的"reasons"列经过人工增强。
搜集汇总
数据集介绍
构建方式
在食品科学与营养研究领域,数据集构建常依赖于对商品信息的系统化整理。该数据集以美国市场上广受欢迎的包装零食为对象,借助OpenAI的GPT-3.5-turbo模型,通过精心设计的提示词自动生成基础数据,内容涵盖产品名称、配料表以及基于特定成分的素食适宜性理由。生成后的数据集经过人工校验与增强,对‘理由’字段补充了更详尽的语义描述,从而提升了数据的准确性与实用性。最终数据集包含49个训练样本,以CSV格式存储,确保了结构的简洁与易用性。
特点
该数据集的核心特色在于其针对美国流行包装零食的精细化标注,每个样本均包含产品名称、完整配料列表及素食适宜性理由三大字段,为食品选择与饮食偏好分析提供了多维度的信息支撑。值得注意的是,理由字段结合了AI生成与人工增强的双重机制,既保证了初始数据的覆盖广度,又通过人工介入提升了语义表达的准确性与逻辑深度。此外,数据集规模虽小,但聚焦于常见品牌,具有高代表性,适用于小样本学习或快速原型验证场景。
使用方法
在实际应用中,该数据集可直接加载为Pandas DataFrame进行探索性分析,例如统计不同零食的素食适宜性分布或挖掘配料表中的常见成分模式。对于自然语言处理任务,可基于产品名称与理由字段构建文本分类模型,预测新零食的素食标签。此外,配料表字段可用于成分共现分析或过敏原识别研究。建议在使用前对理由字段进行进一步清洗与标准化,以适应下游任务需求;同时,由于数据量较小,可考虑结合迁移学习或数据增强技术以提升模型泛化能力。
背景与挑战
背景概述
在食品科学与营养学领域,针对加工食品的膳食适宜性分析日益受到关注,尤其是素食主义与纯素饮食的普及推动了对食品成分透明度的需求。由研究者nehatarey于近期创建的american_snacks数据集,聚焦于美国市场常见的包装零食,旨在通过结构化数据揭示这些产品的成分构成及其对素食者的适用性。该数据集基于OpenAI的gpt3.5-turbo模型生成,并辅以人工校验,包含49条训练样本,每条记录涵盖产品名称、成分列表及适用性理由。尽管规模较小,但其合成数据生成方法为探索大规模食品成分数据库提供了低成本、可扩展的范式,尤其适用于初步的饮食推荐系统或成分分析研究。
当前挑战
该数据集面临的核心挑战在于其合成性质可能引入的偏差与不完整性。首先,成分列表由语言模型生成,可能遗漏关键添加剂或非标准成分,导致对素食适宜性的判断失准,例如某些隐藏的动物源性成分(如乳清、明胶)未被识别。其次,数据集仅包含49个样本,覆盖的零食品牌与种类有限,难以代表美国市场上数以千计的加工食品,限制了模型泛化能力。构建过程中,依赖单一提示词生成数据可能产生重复或语境不匹配的条目,而人工增补的理由字段虽提升可读性,却缺乏标准化验证,增加了主观误差风险。这些挑战要求后续研究需结合真实食品标签数据与领域专家审核,以提升数据集的可靠性与实用性。
常用场景
经典使用场景
在食品科学与营养学交叉研究领域,american_snacks数据集为探索美国主流包装零食的原料构成与饮食适宜性提供了结构化语料。该数据集精心收录了49种常见零食品牌的产品名称、完整配料表及素食适配性判据,尤其适用于构建基于原料语义分析的饮食分类模型。研究者可借助该数据训练自然语言处理模型,自动识别零食中动物源性成分(如乳制品、明胶等),进而评估其对纯素食或蛋奶素食人群的适配度,为个性化膳食推荐系统奠定数据基础。
实际应用
在实际应用层面,该数据集可赋能智能饮食管理平台与电商推荐系统。例如,素食社群App可集成基于此数据训练的模型,用户扫描零食包装条形码后即时获得素食适配性反馈;食品零售商则能通过分析配料模式,优化产品标签分类策略,提升对特殊饮食需求消费者的服务精准度。此外,该数据集还可辅助餐饮企业进行菜单合规性审核,确保供应的包装零食符合特定饮食伦理标准,在健康消费趋势下具有显著商业与社会价值。
衍生相关工作
该数据集衍生了一系列具有启发性的研究工作。其中,基于bert的微调模型被用于预测零食的素食标签,验证了预训练语言模型在食品配料语义理解上的迁移能力;另有学者将其与USDA标准食品数据库对齐,构建跨模态的零食营养-原料联合嵌入空间。此外,研究者还利用该数据开发了可解释性框架,通过注意力机制可视化关键致敏原料对分类决策的影响,不仅提升了模型透明度,也为食品标签监管的AI辅助审查提供了方法论参考。
以上内容由遇见数据集搜集并总结生成


