Brote-pretrain
收藏Hugging Face2024-12-20 更新2024-12-21 收录
下载链接:
https://huggingface.co/datasets/wangphoebe/Brote-pretrain
下载链接
链接失效反馈官方服务:
资源简介:
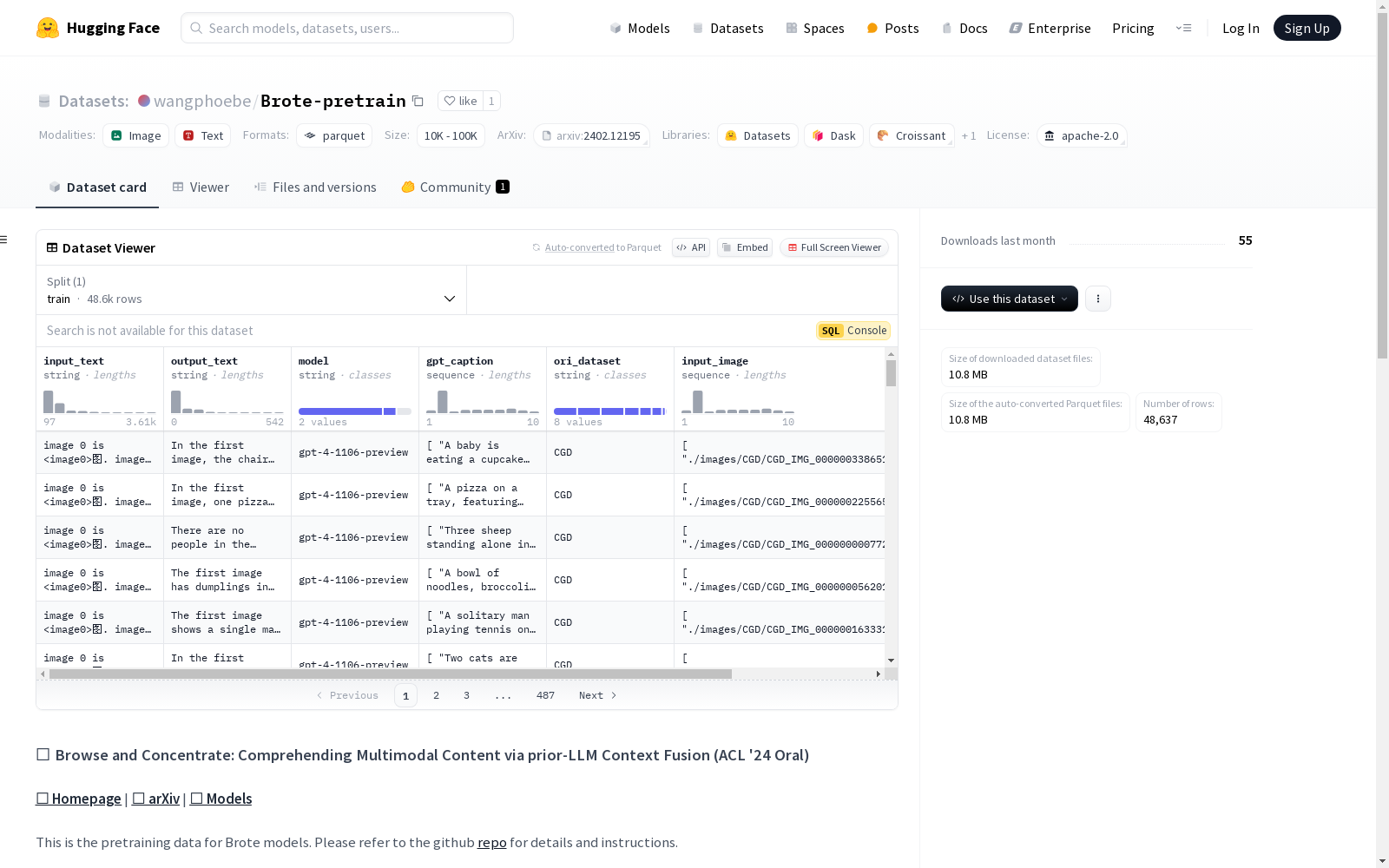
这是一个用于Brote模型预训练的数据集,包含8个使用gzip压缩的parquet文件。每个文件包含7个键,分别是'input_text'(输入文本)、'input_image'(输入图像路径列表)、'output_text'(输出文本或目标答案,用于微调)、'ori_dataset'(原始数据集)、'model'(用于生成上下文增强描述的模型)、'gpt_caption'(上下文增强描述,用于预训练)和'blip2_caption'(由blip2生成的描述,用于mix_blip2训练)。数据集还包含一个名为'images'的目录,其中包含8个压缩的图像目录。
创建时间:
2024-12-09
原始信息汇总
Brote Pretrain 数据集
数据集概述
- 数据集名称: Brote Pretrain
- 数据集用途: 用于Brote模型的预训练。
- 数据集版本: 最新版本更新于2024年12月20日,之前的版本已弃用。
数据文件
- 文件格式: 8个使用gzip压缩的parquet文件。
- 文件列表:
stage1_gpt_v0_vqa_imgpath.parquet.gzipstage1_gpt_v0_vcr_imgpath.parquet.gzipstage1_gpt_v0_nlvr2_imgpath.parquet.gzipstage1_gpt_v02_stvqa_imgpath_resample.parquet.gzipstage1_gpt_v02_iconqa_imgpath_resample.parquet.gzipstage1_gpt_v02_vsr_imgpath_resample.parquet.gzipstage1_gpt_v02_ivqa_imgpath.parquet.gzipstage1_gpt_v02_CGD_imgpath.parquet.gzip
数据字段
- 字段列表:
input_text: 输入文本input_image: 输入图像路径列表output_text: 输出文本(或目标答案,用于微调)ori_dataset: 原始数据集model: 用于生成上下文增强描述的模型gpt_caption: 上下文增强描述(用于预训练)blip2_caption: 由blip2生成的描述,用于mix_blip2训练
图像数据
- 图像目录: 与数据文件一起放置的
images目录,包含8个压缩的图像目录。
引用
-
引用信息:
@inproceedings{ wang2024browse, title={Browse and Concentrate: Comprehending Multimodal Content via Prior-{LLM} Context Fusion}, author={Wang, Ziyue and Chen, Chi and Zhu, Yiqi and Luo, Fuwen and Li, Peng and Yan, Ming and Zhang, Ji and Huang, Fei and Sun, Maosong and Liu, Yang}, booktitle={The 62nd Annual Meeting of the Association for Computational Linguistics}, year={2024}, }
搜集汇总
数据集介绍
构建方式
Brote-pretrain数据集的构建基于多模态内容的深度理解,通过融合先验大语言模型(LLM)的上下文信息,精心设计了数据集的结构。该数据集包含8个使用gzip压缩的parquet文件,涵盖了多种任务类型,如视觉问答(VQA)、自然语言视觉推理(NLVR2)等。每个parquet文件内含7个关键字段,包括输入文本、输入图像路径、输出文本等,确保了数据的多模态性和任务导向性。此外,数据集还包含一个名为'images'的目录,内含8个压缩的图像目录,为数据集提供了丰富的视觉内容支持。
特点
Brote-pretrain数据集的显著特点在于其多模态内容的深度融合与任务导向性。数据集不仅包含了丰富的文本和图像数据,还通过'gpt_caption'和'blip2_caption'等字段,提供了上下文增强的描述信息,这对于预训练和微调任务尤为重要。此外,数据集的结构设计考虑了多种任务需求,如视觉问答、图像字幕生成等,使其在多模态学习领域具有广泛的应用潜力。
使用方法
使用Brote-pretrain数据集时,用户需首先解压并加载相应的parquet文件,利用其中的'input_text'和'input_image'字段进行多模态输入的准备。对于预训练任务,'gpt_caption'字段提供了目标生成的上下文增强描述;而对于微调任务,'output_text'字段则提供了目标答案。此外,数据集还提供了详细的训练和数据准备脚本,用户可根据具体需求进行定制化处理,确保数据集的高效利用。
背景与挑战
背景概述
Brote-pretrain数据集是由清华大学自然语言处理与社会人文计算实验室(THUNLP-MT)于2024年发布的预训练数据集,旨在支持多模态内容理解与融合的研究。该数据集的核心研究问题是通过融合大语言模型(LLM)的上下文信息,提升对多模态内容的理解能力。主要研究人员包括Wang, Ziyue等,研究成果已在ACL 2024会议上以口头报告形式发表。Brote-pretrain数据集的发布对多模态学习领域具有重要意义,为后续研究提供了丰富的预训练资源,推动了多模态内容理解技术的发展。
当前挑战
Brote-pretrain数据集在构建过程中面临多重挑战。首先,多模态数据的融合与处理需要解决不同模态数据之间的异构性问题,确保数据的一致性和有效性。其次,数据集的构建涉及大规模图像和文本数据的采集与标注,如何高效且准确地完成这一过程是一个技术难点。此外,数据集的更新与维护也面临挑战,特别是在技术快速发展的背景下,确保数据集的时效性和前瞻性至关重要。这些挑战不仅影响了数据集的质量,也对后续研究提出了更高的要求。
常用场景
经典使用场景
Brote-pretrain数据集的经典使用场景主要集中在多模态内容的理解和生成任务中。该数据集通过融合先验语言模型(LLM)的上下文信息,能够有效提升多模态内容(如图像和文本)的语义理解和生成能力。具体应用包括视觉问答(VQA)、图像字幕生成(Image Captioning)以及多模态对话系统等,这些任务均依赖于对图像和文本的深度融合与理解。
实际应用
在实际应用中,Brote-pretrain数据集广泛应用于智能客服、教育辅助、医疗诊断等领域。例如,在智能客服系统中,该数据集能够帮助系统更好地理解用户上传的图片和文字描述,从而提供更精准的回答;在教育辅助工具中,它可以帮助学生通过图像和文本的结合更好地理解复杂概念;在医疗诊断中,它能够辅助医生通过多模态信息进行更准确的病情判断。
衍生相关工作
Brote-pretrain数据集的发布催生了一系列相关的经典工作,特别是在多模态学习和生成模型领域。例如,基于该数据集的研究者们开发了多种多模态生成模型,如Brote-IM-XXL模型,这些模型在多个多模态任务上取得了显著的性能提升。此外,该数据集还启发了许多关于多模态内容理解和生成的理论研究,推动了多模态学习领域的整体发展。
以上内容由遇见数据集搜集并总结生成


