EduViQA
收藏Hugging Face2025-01-24 更新2025-01-25 收录
下载链接:
https://huggingface.co/datasets/UIAIC/EduViQA
下载链接
链接失效反馈官方服务:
资源简介:
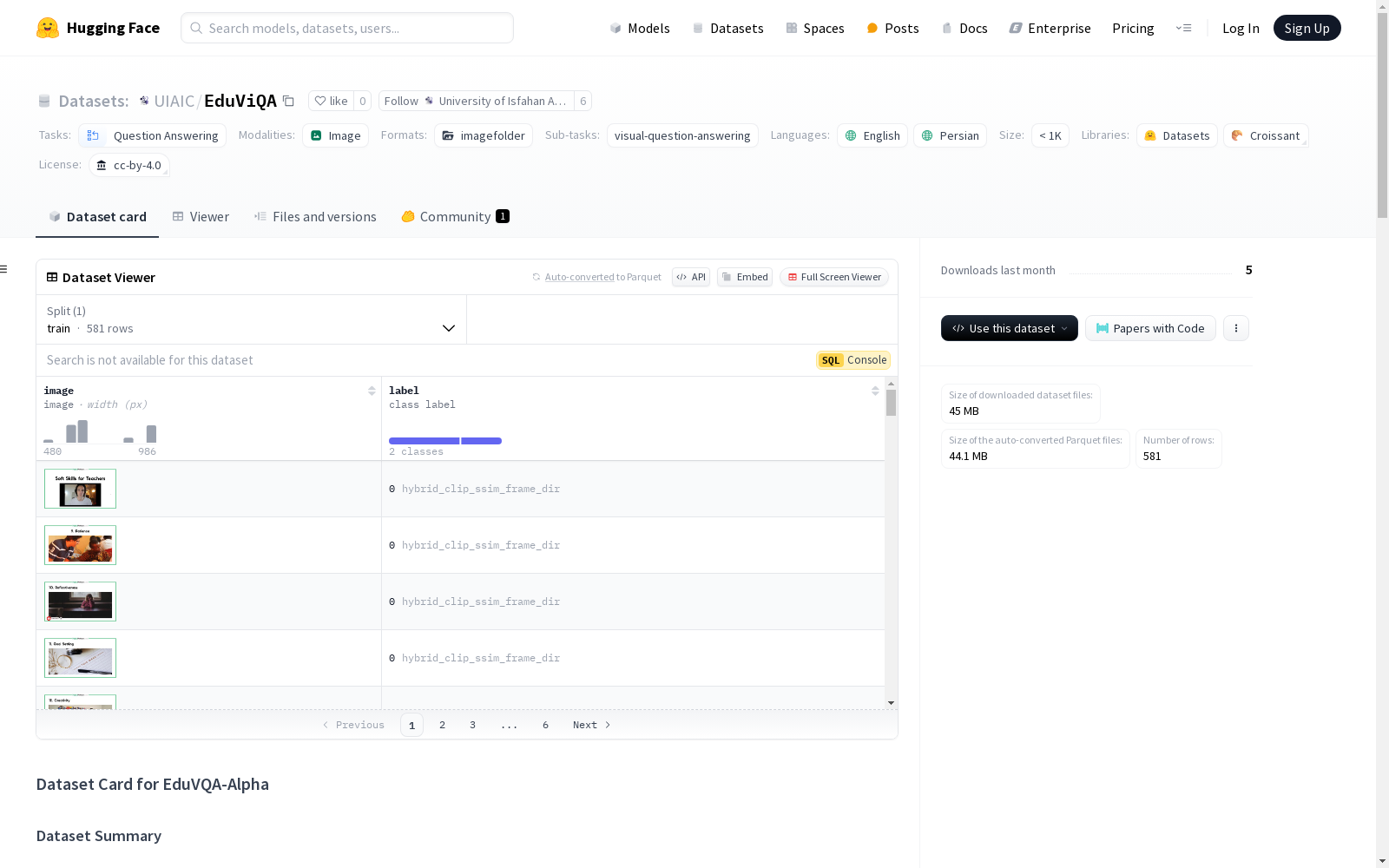
EduVQA-Alpha是一个多语言教育视频问答(VideoQA)数据集,包含学术视频和合成的问答对,支持英语和波斯语。数据集采用CLIP-SSIM自适应分块技术进行视频分割,确保高质量的多模态AI系统语义对齐。数据集结构包括视频分块、视频转录文件和问答对,涵盖了多种学术主题和教学风格。数据集的创建过程包括视频来源、分块和注释,确保伦理合规性。数据集适用于多模态视频问答、RAG管道训练和视觉语言模型基准测试。
EduVQA-Alpha is a multilingual educational video question answering (VideoQA) dataset that consists of academic videos and synthesized question-answer pairs, supporting both English and Persian. This dataset adopts the CLIP-SSIM adaptive chunking technique for video segmentation, ensuring high-quality semantic alignment for multimodal AI systems. The dataset structure includes video chunks, video transcript files, and question-answer pairs, covering a wide range of academic topics and teaching styles. The dataset's creation process covers video sourcing, chunking, and annotation, ensuring ethical compliance. This dataset is applicable to multimodal video question answering, RAG pipeline training, and vision-language model benchmark testing.
创建时间:
2025-01-24
搜集汇总
数据集介绍
构建方式
EduVQA-Alpha数据集的构建采用了多语言教育视频问答(VideoQA)的设计理念,涵盖了英语和波斯语两种语言的学术视频。视频内容经过精心筛选,反映了多样化的学术主题和教学风格。数据集的视频分割采用了CLIP-SSIM自适应分块技术,确保了高质量的多模态语义对齐。通过GPT-4生成的合成问答对,数据集为每个视频片段提供了丰富的标注信息,进一步增强了其在多模态AI系统中的实用性。
特点
EduVQA-Alpha数据集的特点在于其多语言支持和多样化的学术内容。数据集包含20个视频,其中10个为英语,10个为波斯语,每个视频最多包含50个问答对。视频时长分布广泛,涵盖了短讲座、中等时长讲座和长讲座,主题涉及计算机架构、数据结构、系统动力学等多个领域。通过CLIP-SSIM技术进行视频分块,确保了语义的连贯性,同时高熵帧的提取为关键视觉信息提供了支持。
使用方法
EduVQA-Alpha数据集的使用方法简单直观,用户可以通过Hugging Face的`datasets`库加载数据集。数据集的主要应用场景包括多模态视频问答、检索增强生成(RAG)管道训练以及视觉-语言模型的基准测试。数据字段包括视频分块目录、视频转录文本以及问答对的JSON文件,用户可以根据需要灵活调用这些资源进行研究和开发。
背景与挑战
背景概述
EduVQA-Alpha数据集是一个多语言教育视频问答(VideoQA)数据集,由UIAIC团队开发,旨在支持多语言检索增强生成(RAG)任务。该数据集包含学术视频,并附有合成的问答对,涵盖英语和波斯语。视频内容涉及计算机架构、数据结构、系统动力学等多个学术主题,反映了多样化的教学风格。数据集采用CLIP-SSIM自适应分块技术进行视频分割,确保高质量的多模态语义对齐,为学术界和工业界的VideoQA管道提供了坚实的基础。
当前挑战
EduVQA-Alpha数据集在构建和应用中面临多重挑战。首先,视频问答任务本身要求模型具备跨模态理解能力,能够同时处理视觉和语言信息,这对模型的复杂性和计算资源提出了较高要求。其次,数据集的构建过程中,视频分块和问答对的生成需要高度精确的语义对齐,以确保问答对与视频内容的关联性。此外,多语言支持增加了数据处理的复杂性,尤其是在波斯语和英语之间的语义转换和文化差异方面。最后,数据集的伦理合规性也是一个重要挑战,包括视频版权、数据隐私以及贡献者的明确许可等问题,这些都需要在数据集的构建和使用中得到妥善处理。
常用场景
经典使用场景
EduVQA-Alpha数据集在视频问答(VideoQA)领域具有广泛的应用,尤其是在教育场景中。该数据集通过多语言支持(英语和波斯语)和多样化的学术主题视频,为研究者提供了一个理想的平台,用于开发和测试基于视频内容的理解与问答系统。其独特的CLIP-SSIM自适应分块技术确保了视频片段的语义连贯性,使得模型能够更好地理解视频内容并生成准确的答案。
解决学术问题
EduVQA-Alpha数据集解决了多模态学习中的关键问题,特别是在视频与文本的联合理解方面。通过提供高质量的合成问答对,该数据集为研究者提供了一个标准化的基准,用于评估和提升视觉-语言模型的性能。此外,其多语言特性为跨语言视频问答系统的开发提供了重要支持,推动了多模态人工智能在教育领域的应用。
衍生相关工作
EduVQA-Alpha数据集催生了一系列相关研究工作,特别是在多模态学习和视频问答领域。基于该数据集的研究成果包括改进的视觉-语言模型架构、跨语言问答系统的开发,以及基于检索增强生成(RAG)技术的教育应用。这些工作不仅推动了学术界对多模态理解的研究,也为工业界提供了实用的技术解决方案。
以上内容由遇见数据集搜集并总结生成


