encoded_LA_2021
收藏Hugging Face2024-08-20 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/Bisher/encoded_LA_2021
下载链接
链接失效反馈官方服务:
资源简介:
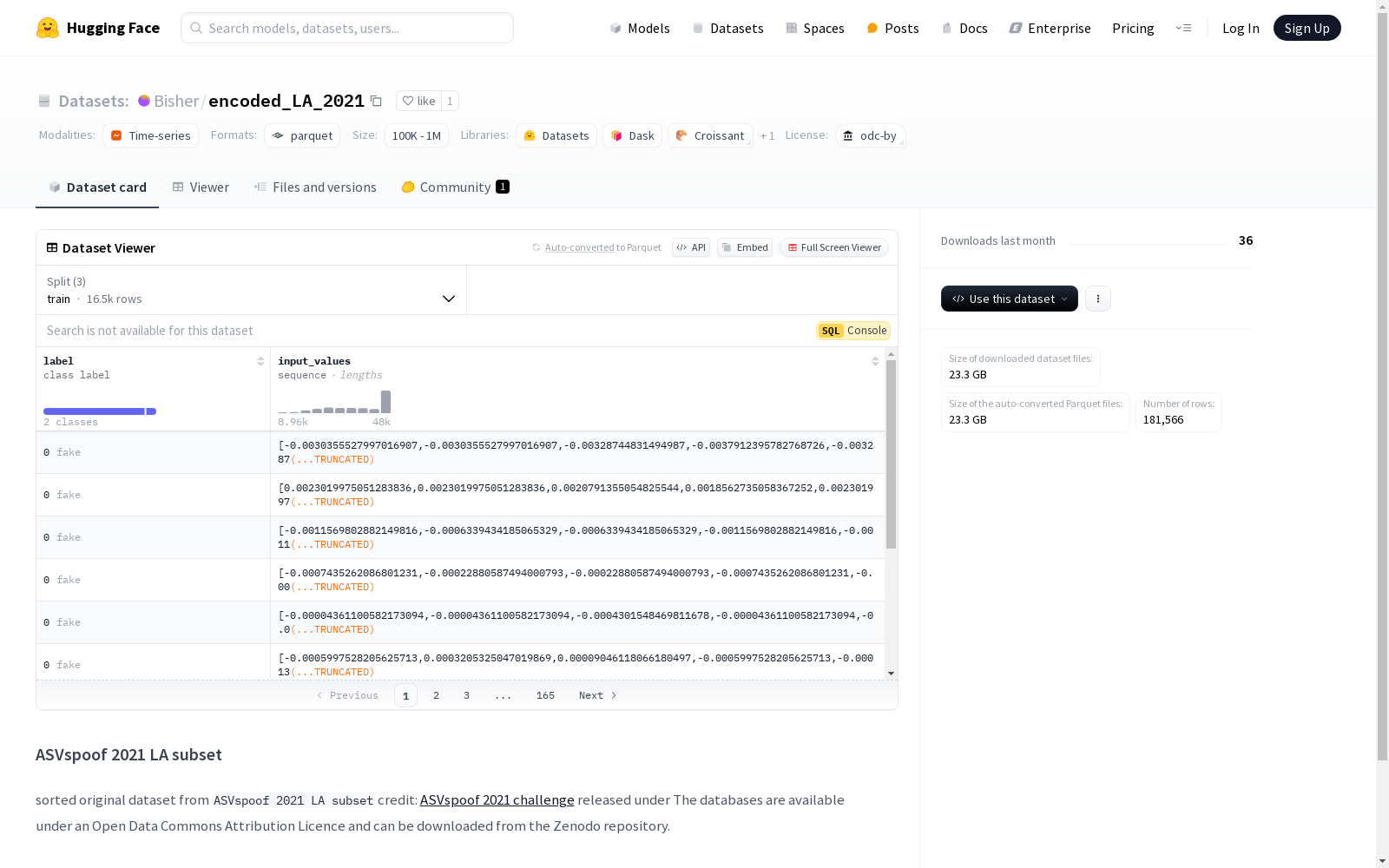
该数据集是 'ASVspoof 2021 LA subset' 的原始数据集,包含两个主要特征:'label' 和 'input_values'。'label' 特征是一个类别标签,包含两个类别:'fake' 和 'real'。'input_values' 特征是一个浮点数序列。数据集分为三个部分:训练集、验证集和测试集,分别包含不同数量的样本和字节数。数据集的下载大小和实际大小也被提供。数据集的配置名为 'default',数据文件路径根据不同的分割进行指定。数据集的许可证是 'odc-by',并且数据集的名称是 'ASVspoof 2021 LA'。
This dataset is the original subset of 'ASVspoof 2021 LA', which includes two core features: 'label' and 'input_values'. The 'label' feature is a categorical label with two classes: 'fake' and 'real'. The 'input_values' feature is a sequence of floating-point numbers. The dataset is divided into three splits: training set, validation set, and test set, each with a distinct number of samples and byte size. Both the download size and the actual storage size of the dataset are provided. The dataset configuration is named 'default', and the data file paths are specified according to different splits. The dataset license is 'odc-by', and the official name of the dataset is 'ASVspoof 2021 LA'.
创建时间:
2024-08-20
原始信息汇总
数据集概述
数据集信息
-
特征信息:
label:标签,数据类型为类别标签,包含两个类别:0:fake(假)1:real(真)
input_values:输入值,数据类型为浮点数序列(float32)
-
数据分割:
train:训练集,包含16464个样本,大小为2461510888字节validation:验证集,包含16926个样本,大小为1849172416字节test:测试集,包含148176个样本,大小为22112409484字节
-
数据集大小:
- 下载大小:23303764736字节
- 数据集大小:26423092788字节
-
配置信息:
config_name:defaultdata_files:train:路径为data/train-*validation:路径为data/validation-*test:路径为data/test-*
-
许可证:odc-by(Open Data Commons Attribution License)
-
数据集名称:ASVspoof 2021 LA
数据集来源
- 数据集来源:ASVspoof 2021 LA subset
- 版权声明:数据集来源于ASVspoof 2021 challenge,遵循Open Data Commons Attribution License,可从Zenodo仓库下载。
搜集汇总
数据集介绍
构建方式
encoded_LA_2021数据集源自ASVspoof 2021 LA子集,该数据集旨在评估自动说话人验证(ASV)系统在对抗欺骗攻击时的鲁棒性。数据集的构建过程涉及从ASVspoof 2021挑战赛中精选的音频样本,这些样本经过编码处理,转换为适合机器学习模型输入的格式。数据集分为训练集、验证集和测试集,每个样本包含音频特征(input_values)和对应的标签(label),标签指示样本为真实或伪造。
特点
encoded_LA_2021数据集的特点在于其专注于语音欺骗检测领域,提供了大量经过编码处理的音频样本。数据集包含16464个训练样本、16926个验证样本和148176个测试样本,覆盖了广泛的语音欺骗场景。每个样本的音频特征以浮点数序列的形式存储,标签则明确区分真实和伪造样本。数据集的规模庞大,适用于训练和评估复杂的深度学习模型。
使用方法
encoded_LA_2021数据集的使用方法较为直观,用户可以通过加载数据集文件直接访问训练、验证和测试集。每个样本的音频特征(input_values)可用于模型输入,而标签(label)则用于监督学习。数据集适用于语音欺骗检测任务,用户可以利用其训练模型并评估模型在对抗欺骗攻击时的性能。数据集的开放许可(ODC-BY)允许广泛的学术和商业用途,但需遵守相应的引用要求。
背景与挑战
背景概述
ASVspoof 2021 LA数据集是ASVspoof 2021挑战赛的一部分,专注于语音合成与转换的欺骗检测。该数据集由国际语音通信协会(ISCA)组织,旨在推动自动说话人验证(ASV)系统的安全性研究。数据集创建于2021年,包含了真实语音与合成语音的对比样本,涵盖了多种语音生成技术。其核心研究问题在于如何有效区分真实语音与合成语音,以提升ASV系统对欺骗攻击的鲁棒性。该数据集对语音安全领域的研究具有重要影响力,为学术界和工业界提供了基准测试平台。
当前挑战
ASVspoof 2021 LA数据集面临的挑战主要体现在两个方面。其一,语音合成与转换技术的快速发展使得欺骗攻击手段日益复杂,如何在高精度下区分真实与合成语音成为核心难题。其二,数据集的构建过程中,需确保样本的多样性与代表性,涵盖多种语言、口音及合成技术,这对数据采集与标注提出了极高要求。此外,数据规模的庞大与计算资源的消耗也是构建与使用该数据集时不可忽视的挑战。
常用场景
经典使用场景
在语音识别和生物特征认证领域,encoded_LA_2021数据集被广泛应用于评估和开发反欺骗技术。该数据集通过提供大量标记为真实或伪造的语音样本,帮助研究人员训练和测试模型,以区分真实的语音输入和潜在的欺骗性攻击。
实际应用
在实际应用中,encoded_LA_2021数据集被用于增强智能助手、银行电话客服系统等依赖语音识别技术的应用的安全性。通过集成基于该数据集训练的模型,这些系统能够更准确地识别用户身份,防止未授权访问和欺诈行为。
衍生相关工作
基于encoded_LA_2021数据集,研究者们已经开发出多种先进的语音反欺骗算法和系统。这些工作不仅推动了语音识别技术的发展,也为相关领域的安全研究提供了新的思路和方法,如深度学习在生物特征认证中的应用等。
以上内容由遇见数据集搜集并总结生成


