SKIML-ICL/hoh_nli
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/SKIML-ICL/hoh_nli
下载链接
链接失效反馈官方服务:
资源简介:
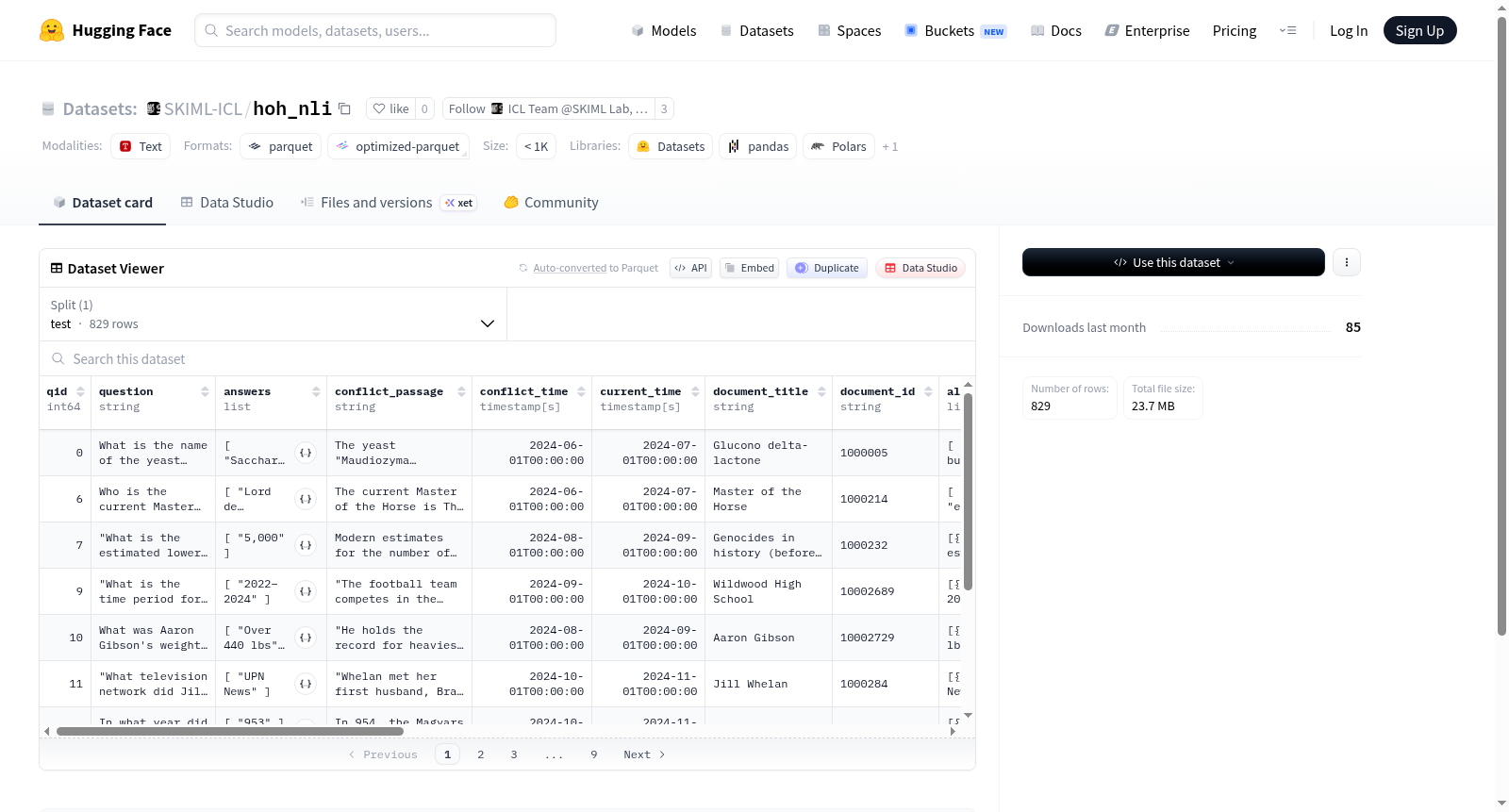
该数据集是一个用于问答和文档检索任务的数据集,专注于处理时间冲突和过时信息。它包含问题、答案列表、冲突段落、时间戳、文档标题和ID等字段,并提供了上下文信息(如排名、分数、文本)以及答案可性分析。数据集可能用于评估模型在动态信息环境中的性能,例如检测和解决信息冲突。数据仅包含测试集,共829个示例。
This dataset is designed for question answering and document retrieval tasks, with a focus on handling temporal conflicts and outdated information. It includes fields such as question, answer lists, conflict passages, timestamps, document titles and IDs, and provides context information (e.g., rank, score, text) along with answerability analysis. The dataset may be used to evaluate model performance in dynamic information environments, such as detecting and resolving information conflicts. It contains only a test split with 829 examples.
提供机构:
SKIML-ICL
搜集汇总
数据集介绍
构建方式
hoh_nli数据集专为时效性问答中的自然语言推理任务而设计,其构建基于多源信息的系统整合。首先,通过收集包含冲突信息的篇章、问题及对应的过时答案,形成初始样本。随后,利用检索器获取相关上下文片段,并标注每段文本与问题及候选答案之间的蕴含、矛盾或中立关系,同时记录时间戳以确保时序一致性。最终,通过筛选有效冲突篇章并生成可回答性前缀,构建出具有明确验证标签的测试集。
特点
该数据集的核心特点在于其聚焦于信息时效性冲突,每个样本均包含一个过时答案、一个冲突篇章以及当前回答的复合信息,能够有效模拟现实世界中知识更新导致的语义矛盾。此外,数据集中每段上下文均经过NLI标签标注,使得模型可同时学习推理与时间感知能力。其结构化的时间字段与多答案列表设计,为探究时间依赖性错误提供了精细的评测基准。
使用方法
使用该数据集时,开发者应首先将问题、冲突篇章及过时信息组合为输入,利用预设的NLI标签训练模型识别矛盾关系。测试阶段可针对`answerable`字段评估模型在时间敏感场景下的回答可判定性,并通过`ctxs`中的上下文片段进行检索增强推理。建议结合`answers`与`conflict_answers`列表对比模型输出,以验证其对时效性变化的适应能力。
背景与挑战
背景概述
在开放域问答与信息检索领域,知识的时效性至关重要。为应对互联网信息持续演化带来的挑战,时序文本蕴含(Temporal NLI)应运而生,成为评估模型能否理解并推理随时间变化知识的关键任务。hoh_nli数据集由相关研究机构于近期构建,旨在探索问答系统中答案因文本数据更新而产生冲突时的逻辑推理机制。该数据集以段落级的时序矛盾样本为核心,融合了检索上下文、时序戳以及蕴含标签,为自然语言理解模型在动态知识环境下的鲁棒性评估提供了稀缺的高质量基准,对推动时序推理与多源证据融合研究具有重要价值。
当前挑战
该数据集所解决的领域核心挑战在于:传统自然语言推理(NLI)任务仅考虑静态文本的语义关系,忽略了知识随时间演化而产生的冲突。如何在跨时间的多版本文本中准确识别并推理出答案的冲突与变迁,成为时序问答系统面临的严峻考验。构建过程中,数据收集需从大规模语料中精准定位新旧版本段落间的矛盾信息,并人工标注其中蕴含关系。同时,还需处理时间戳的精准对齐、冲突段落的有效性判定以及多轮前缀上下文的逻辑连贯性,这些步骤对标注效率与数据质量都构成了极高要求。
常用场景
经典使用场景
在自然语言处理与知识时效性研究的交汇领域,hoh_nli数据集为评估和提升模型在信息过时情境下的推理能力提供了关键基准。其经典使用场景聚焦于识别问答系统中由于时间推移而产生的答案冲突,要求模型能够从包含过时信息的文本片段中,精准判断当前哪个答案依然有效,挑战模型对时间敏感知识的感知与动态更新能力。
衍生相关工作
围绕hoh_nli衍生出一系列开创性工作,包括基于时间感知的阅读理解模型、时序事实对齐框架以及动态知识图谱补全方法。研究者借鉴其冲突时间对设计,提出了“时间条件化推理器”以显式建模信息更迭过程,并催生了诸如TempQuestions、TimeDial等拓展数据集,共同构建起时间意识NLP研究的基石,促进了从学术理论到工业落地的知识流动。
数据集最近研究
最新研究方向
随着信息爆炸时代的到来,知识库与搜索引擎中的信息常因现实世界的动态演变而过时,hoh_nli数据集应运而生,它聚焦于时变信息下的自然语言推理任务。当前前沿研究方向主要围绕时序矛盾检测与基于旧证据的改写推理,例如探索事实类问题随时间推移出现的答案冲突现象,以及如何利用LLM进行时效性感知的答案消歧。该数据集契合了大模型对实时知识更新与幻觉抑制的热点需求,为构建能动态辨识信息陈旧度的检索增强系统提供了标尺,在事实验证、对话系统与知识图谱演化等场景中具有深远影响。
以上内容由遇见数据集搜集并总结生成


