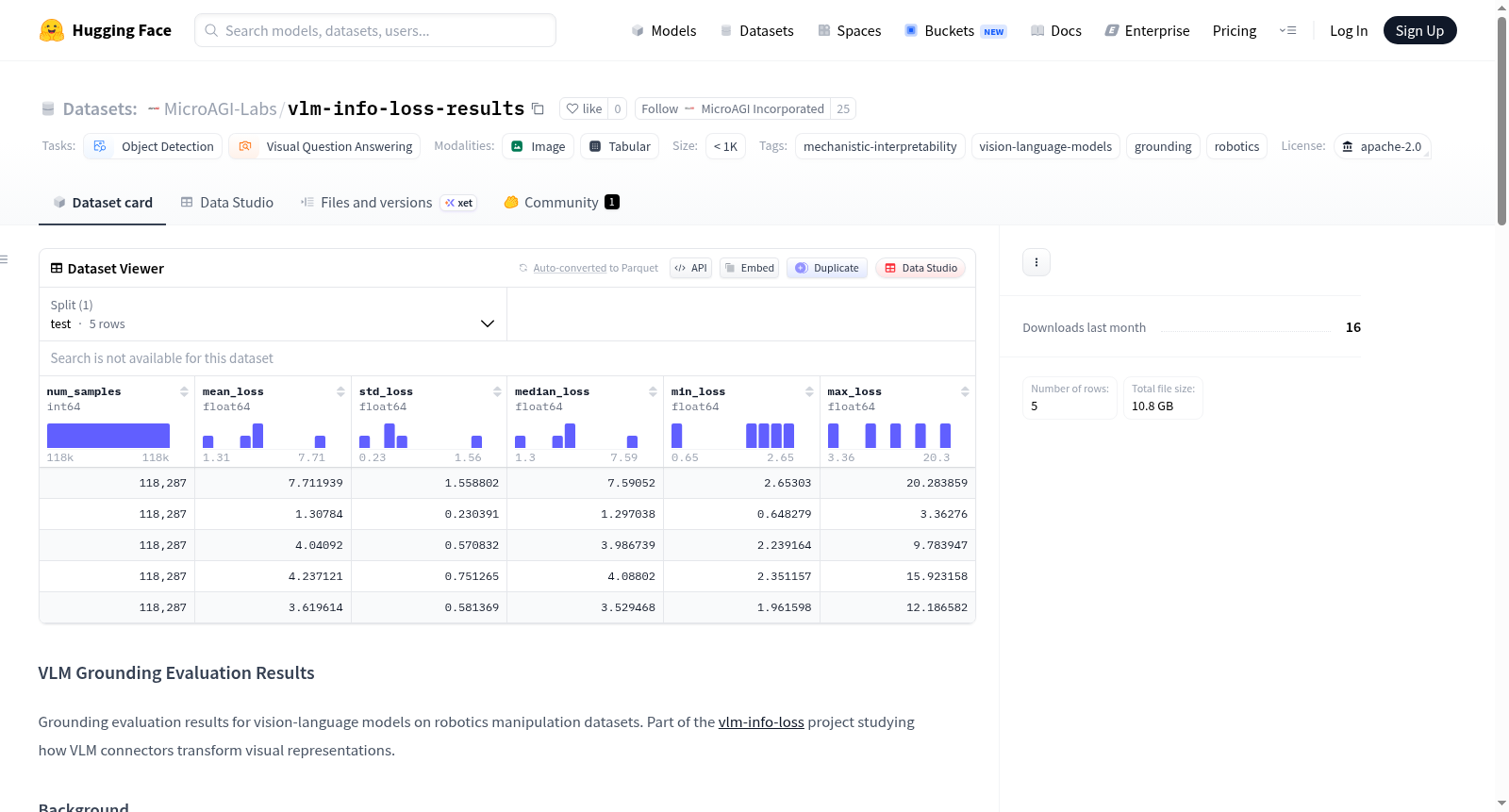
vlm-info-loss-results
收藏数据集概述
基本信息
- 数据集名称: VLM Info Loss - Grounding Results
- 许可证: Apache-2.0
- 任务类别: 目标检测、视觉问答
- 标签: 机械可解释性、视觉语言模型、基础定位、机器人学
- 描述: 视觉语言模型在机器人操作数据集上的基础定位评估结果。
背景与目的
该数据集是 vlm-info-loss 项目的一部分,旨在研究视觉语言模型连接器如何转换视觉表征。嵌入级分析表明,连接器执行“压缩-扩展”转换:强化主导对象表征,同时压缩次要对象的类别身份。基础定位评估旨在测试端到端流程:在连接器中幸存的空间信息是否也能在完整的LLM解码成结构化边界框输出的过程中幸存。
评估协议
在8个机器人操作数据集(DROID, LIBERO, TACO-Play, JACO-Play, Berkeley Autolab UR5, MolmoAct, NYU Door Opening, UT Austin MUTEX)上,使用3个摄像机视角(2个外部,1个腕戴式)进行两轮基础定位:
- 场景清单 — “列出此图像中所有可见对象及其边界框坐标”。
- 任务基础定位 — “给定任务‘{task}’,识别相关对象及其边界框”。
- 任务规划 — “描述完成此任务的逐步计划”。
- 评判 — 离线启发式评分(边界框有效性、去重、重叠分析)。
评估模型
| 系列 | 模型 | 参数量 | 连接器 | 样本数 | 变体 |
|---|---|---|---|---|---|
| Gemma4 | gemma-4-E2B-it | 2B | 线性投影(9倍合并) | 798 | v2b, v2b-attn |
| Gemma4 | gemma-4-E4B-it | 4B | 线性投影(9倍合并) | 798 | v2b |
| Qwen3.5 | Qwen3.5-4B | 4B | 补丁合并MLP(4倍) | 798 | v2b, v2b-attn(进行中) |
| Qwen3.5 | Qwen3.5-9B | 9B | 补丁合并MLP(4倍) | 798 | v2b |
| Qwen3.5 | Qwen3.5-27B | 27B | 补丁合并MLP(4倍) | — | v2b(进行中) |
结果变体
v2b/— 标准基础定位评估(每个数据集50个片段)。v2b-attn/— 包含ViT注意力图捕获的基础定位,用于SFT锁定前后的分析。v2b-nothink/— 禁用思维模式的基线(进行中)。
目录结构
grounding/ ├── v2b/ │ ├── qwen35-4b/ │ │ ├── scene_inventory/ # 场景轮次的原始模型输出 │ │ ├── task_grounding/ # 任务轮次的原始模型输出 │ │ ├── task_plan/ # 逐步计划 │ │ └── judge/ # 评分结果(scores.json) │ └── qwen35-9b/ ├── v2b-attn/ │ ├── gemma4-e2b/ │ │ ├── scene_inventory/ │ │ ├── task_grounding/ │ │ ├── task_plan/ │ │ ├── judge/ │ │ └── attention/ # 每层ViT注意力图(.npy) │ └── qwen35-4b/ └── v2b-nothink/ # 进行中
关键发现
- Gemma4产生有效边界框的比例为96%(E2B),而Qwen3.5为42-55%,主要因为Gemma4使用原生
box_2d输出格式进行训练。 - 腕戴式摄像机会降低所有模型的基础定位性能 — 检测到的对象更少,边界框有效性更低,这与连接器的主导对象窄化效应一致。
- E4B比E2B检测到更多对象(平均4.1 vs 3.7),但精度略低(91% vs 96%)。
- 任务-场景标签重叠率较低(22-27%),即使对于Gemma4也是如此,反映了场景清单和任务特定基础定位之间真实的标签粒度不匹配。
相关分析
完整的连接器分析请参见 notebooks/analysis.ipynb,包括:KNOR几何、CKA结构相似性、有效秩、线性探测(主导类别 + 多标签mAP)、对象计数消融,以及在118k COCO规模上对4个Qwen模型的logit lens分析。