rocq-doc
收藏Hugging Face2025-11-14 更新2025-11-15 收录
下载链接:
https://huggingface.co/datasets/FrancoisMichelon/rocq-doc
下载链接
链接失效反馈官方服务:
资源简介:
包含从Rocq-Prover文档和多个Coq仓库提取的三个相关数据集:课程材料、仓库中的.v文件以及Rocq HTML文档的分块文本。数据集以JSONL格式存储,适用于语言模型训练和代码搜索等场景。
创建时间:
2025-11-13
原始信息汇总
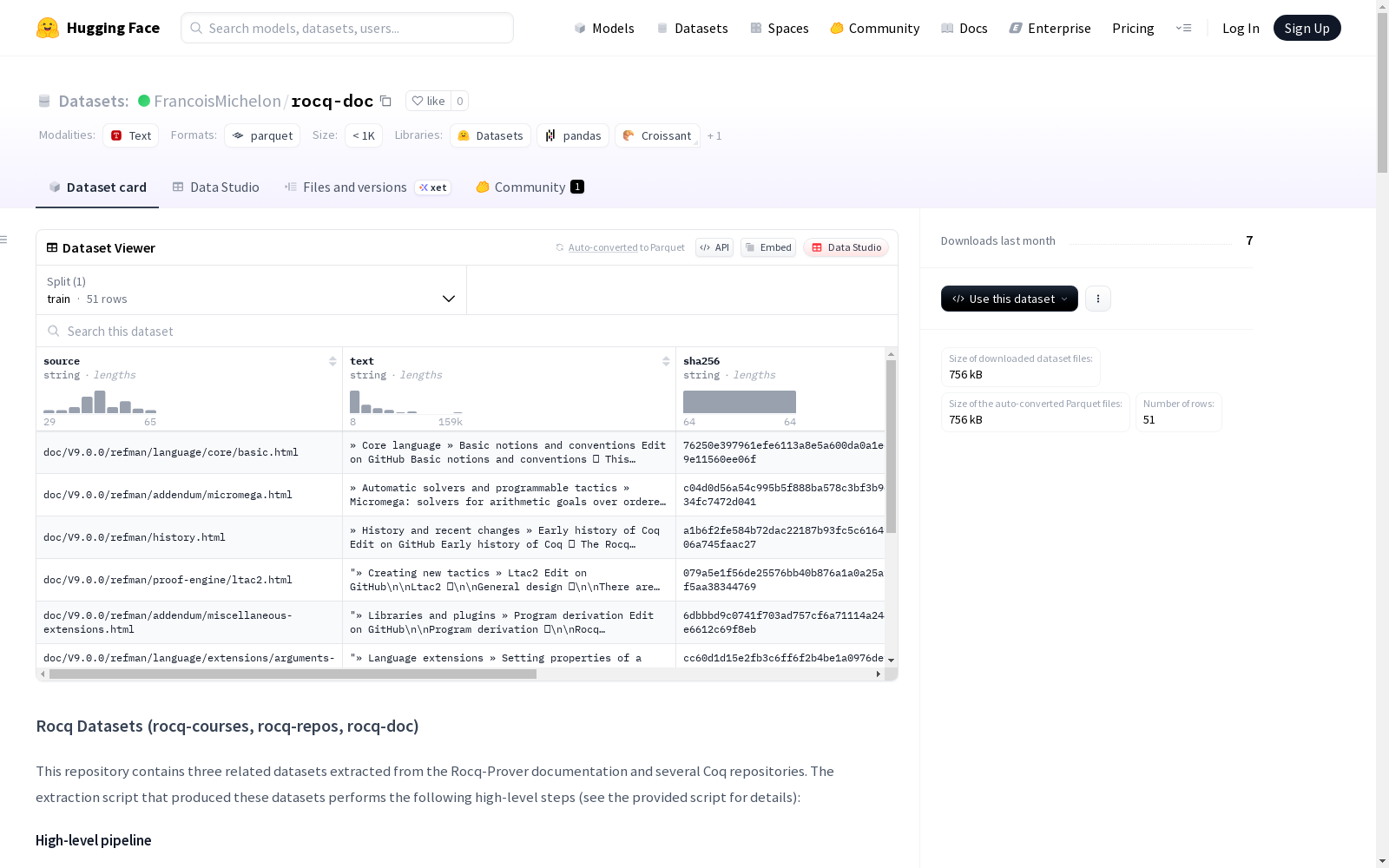
Rocq-Doc 数据集概述
数据集基本信息
- 数据集名称: rocq-doc
- 存储库地址: https://huggingface.co/datasets/FrancoisMichelon/rocq-doc
- 数据格式: JSONL
- 总大小: 1,870,701字节
- 下载大小: 755,867字节
- 样本数量: 51
数据结构
特征字段
source: 字符串类型,数据来源路径text: 字符串类型,分块后的文本内容sha256: 字符串类型,SHA256哈希值num_blocks: 整型,块数量html_preview: 字符串类型,HTML预览
数据划分
- 仅包含训练集划分
数据来源与处理
数据来源
- 从Rocq-Prover HTML文档中提取
- 解析路径为doc/rocq-prover.org下的HTML页面
处理流程
- 使用BeautifulSoup解析HTML页面
- 移除导航栏、页脚和脚本
- 提取结构化内容块(标题、段落、代码块、列表、表格)
- 提取图像元数据(不包含图像二进制数据)
- 将内容块组合并按近似令牌大小分块
分块策略
- 基于字符的近似分块(chunk_size约3000字符)
- 包含重叠区域
- 代码块使用三反引号标记
数据格式示例
json { "source": "path/relative/to/doc/rocq-prover.org", "text": "chunked textual content (may contain markdown-style code fences for code blocks)" }
使用方式
从Hub加载
python from datasets import load_dataset ds = load_dataset("FrancoisMichelon/rocq-doc")
本地JSONL读取
python import json with open("rocq_dataset/rocq_doc.jsonl", "r", encoding="utf-8") as fh: for line in fh: obj = json.loads(line)
相关数据集
FrancoisMichelon/rocq-courses: 合并的课程材料FrancoisMichelon/rocq-repos: 从多个代码库收集的.v文件
限制说明
- HTML解析采用启发式方法,可能包含非预期内容
- 分块基于字符近似,如需严格令牌预算应重新分块
- 不包含二进制资源(图像),仅保留元数据
搜集汇总
数据集介绍
构建方式
在形式化验证领域,rocq-doc数据集通过系统化的文档处理流程构建而成。其构建过程始于对Rocq-Prover官方HTML文档的解析,运用BeautifulSoup工具提取页面核心内容区块,包括标题段落、代码块和表格等结构化元素。文档解析阶段采用启发式方法识别主要内容容器,同时剔除导航栏与脚本等无关信息。随后通过基于字符长度的智能分块算法,将连续内容区块组合成近似令牌长度的文本片段,代码区块在分块过程中使用三重反引号进行标记封装,确保技术文档的原始格式得以保留。
使用方法
针对形式化验证领域的研究需求,该数据集提供了灵活的使用方案。研究人员可通过Hugging Face数据集库直接加载完整数据集,利用标准接口访问经过预处理的文档区块。每个数据样本包含源文档路径和分块后的文本内容,支持对技术文档进行端到端的语义分析。对于需要定制化处理的场景,用户可基于原始JSONL文件进行本地解析,根据具体任务需求调整分块策略或令牌化方法。该数据集特别适合用于构建领域特定的问答系统、文档检索工具,以及训练理解形式化验证术语的专业语言模型。
背景与挑战
背景概述
在形式化验证领域,Coq证明助手作为构建数学定理机器验证体系的核心工具,其生态系统的文档资源整合对推动程序正确性研究具有重要意义。rocq-doc数据集由FrancoisMichelon团队于2024年创建,通过系统化提取Rocq-Prover官方文档的HTML页面内容,构建了结构化文本语料库。该数据集聚焦于解决形式化方法领域中知识检索与语义理解的瓶颈问题,为定理证明辅助系统的自然语言处理任务提供了基础数据支撑,显著提升了验证工具文档的机器学习适配性。
当前挑战
该数据集构建过程中面临文档结构异构性挑战,需通过启发式解析器处理导航元素剥离与主体内容定位,同时需平衡代码块与文本段的语义连贯性。在领域应用层面,其核心挑战在于解决形式化验证文档特有的数学逻辑表达与自然语言混合建模问题,包括定理陈述的精确解析、证明步骤的语义分割,以及跨模态内容(如缺失的二进制资源)的表示学习。字符级分块策略虽提升处理效率,但需后续适配特定标记器的严格令牌约束。
常用场景
经典使用场景
在形式化验证领域,rocq-doc数据集通过解析Rocq-Prover官方文档的HTML结构,将技术文档按语义块分割为近似令牌长度的文本片段。这种处理方式特别适用于训练语言模型理解形式化证明系统的技术文档结构,模型能够学习代码块与说明文本的关联模式,为自动化文档生成和智能代码辅助提供基础支撑。
解决学术问题
该数据集有效解决了形式化方法研究中技术文档与代码语义脱节的核心难题。通过保留文档中代码块的三反引号标记结构,研究者可构建文档-代码对齐模型,推动程序验证知识的结构化表示。这种数据组织形式显著提升了定理证明器文档的机器可读性,为跨模态形式化知识检索系统奠定数据基础。
实际应用
在实际工业场景中,rocq-doc支撑着智能开发工具的构建。工程师利用其 chunk 化的文档数据训练代码推荐模型,能在Coq证明编写过程中实时提供相关定理引用。半导体企业已将其集成至EDA工具链,通过文档语义检索加速硬件形式化验证流程,有效降低芯片设计中的规范理解成本。
数据集最近研究
最新研究方向
在形式化验证领域,rocq-doc数据集凭借其从Rocq-Prover文档中提取的结构化文本块,正推动自然语言处理与定理证明的交叉研究。当前前沿聚焦于利用该数据训练检索增强生成模型,以提升对Coq代码语义的理解能力,同时结合大语言模型探索自动化证明策略生成。这一方向呼应了形式化方法社区对可解释AI系统的需求,通过文档与代码的关联分析,为构建智能证明助手奠定了数据基础,显著加速了复杂数学定理的机器验证进程。
以上内容由遇见数据集搜集并总结生成


