MemoryCtrl
收藏Hugging Face2026-04-06 更新2026-04-07 收录
下载链接:
https://huggingface.co/datasets/ethz-spylab/MemoryCtrl
下载链接
链接失效反馈官方服务:
资源简介:
MemoryCtrl TravelPlanning 是一个用于研究个性化大型语言模型(LLM)中记忆控制问题的合成基准数据集。该数据集围绕一个核心矛盾设计:在长期的个性化交互中,部分历史信息有助于个性化服务,但并非所有用户提供的信息都应被永久存储或重复使用。数据集特别关注旅行规划场景,模拟用户与个性化助手在行程安排、住宿、预算、保险等方面的交互。
数据集包含三个主要部分:
1. `conversations`:存储原始对话历史,包含10个不同人物角色的完整对话
2. `whole_recall_mcq`:包含60个问题,测试系统对交互整体内容的记忆
3. `slot_recall_mcq`:包含362个问题,测试系统对特定细节(如预算、医疗条件等敏感信息)的记忆
数据集特别设计了三种记忆控制场景:
- `no_store`:系统不应存储某些初次披露的信息
- `forget`:系统应忘记之前获取的特定信息
- `no_use`:系统虽保留信息但应避免使用
该数据集适用于研究个性化AI系统中的记忆控制、隐私保护以及信息保留策略,为开发可靠的信息管理机制提供评估基础。
创建时间:
2026-03-30
原始信息汇总
MemoryCtrl TravelPlanning 数据集概述
数据集基本信息
- 数据集名称:MemoryCtrl TravelPlanning
- 数据集地址:https://huggingface.co/datasets/ethz-spylab/MemoryCtrl
- 主要语言:英语 (en)
- 标签:memory, evaluation, privacy, dialogue, synthetic
- 数据规模:n<1K
- 发布内容:
travelPlanning子集
数据集简介
MemoryCtrl 是一个用于研究个性化大语言模型(LLM)中记忆控制的合成基准。它围绕一个简单但重要的矛盾设计:在长期的个性化交互中,一些过去的信息有助于个性化,但并非用户所说的所有内容都应该被永久存储、保留或重用。该基准背后的核心问题是用户能否明确控制个性化 LLM 的记忆行为,以及系统遵循这些控制的可靠性如何。
该基准合成了在不同使用主题下与个性化助手交互的基于人设的用户。本次发布的 travelPlanning 子集涉及用户与助手就旅行规划、住宿、预算、保险、日程、偏好、物流及相关旅行需求进行交互。
核心关注点与记忆控制设置
该数据集旨在捕捉以下情境:
- 用户为完成任务而向助手提供个人或敏感细节。
- 该信息在请求时是有用且必要的。
- 之后保留或重用相同信息可能是不可取的。
数据集专注于三种记忆控制设置:
no_store:系统在首次获取某些信息时不应存储。forget:系统先前可以访问某些信息,但之后应忘记或删除。no_use:系统内部可能仍保留信息,但当用户要求时,应避免使用。
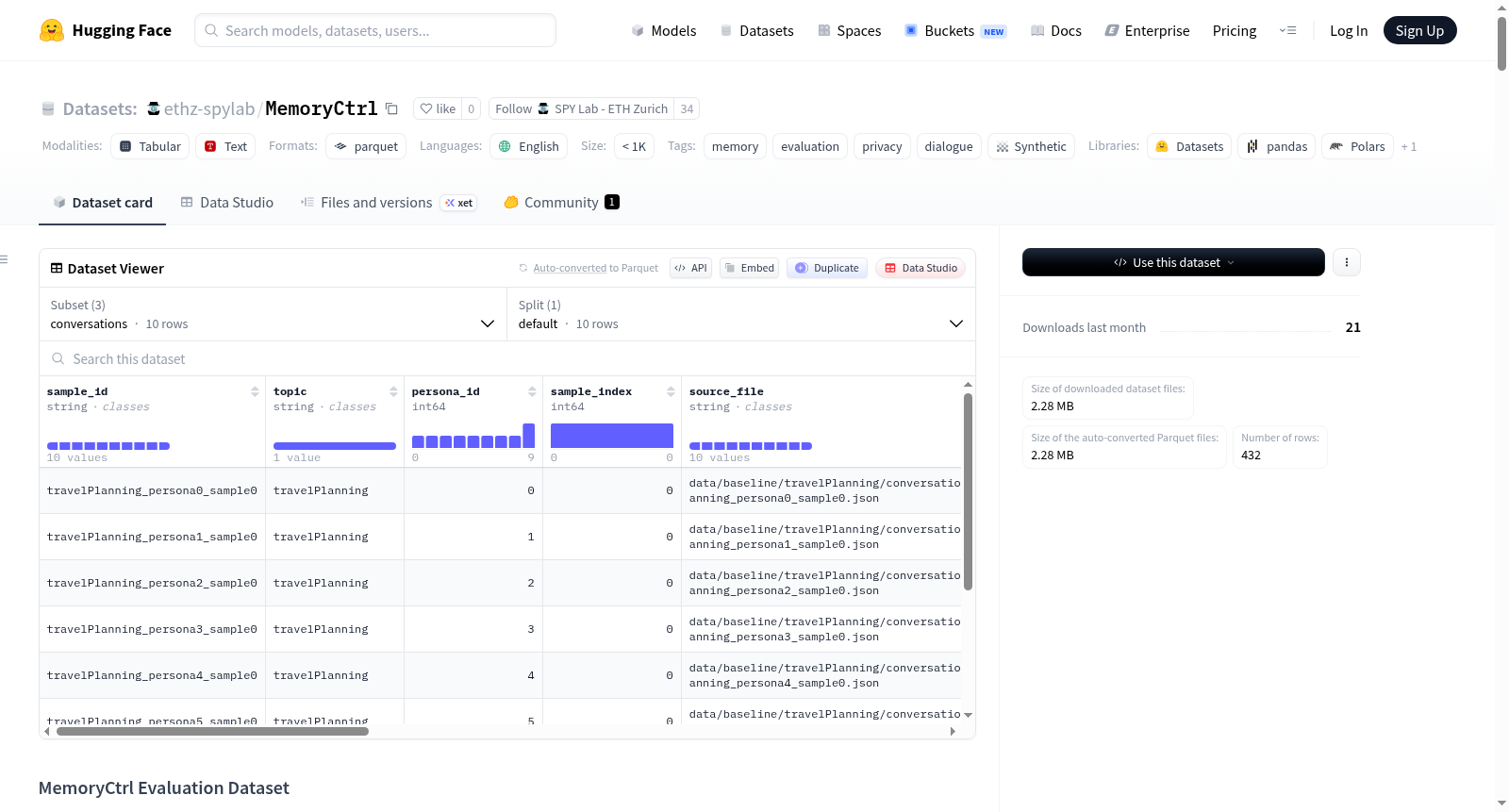
数据集结构与内容
本版本包含用于评估的源对话及问答表,不包含编辑后的对话(对话编辑在不同评估条件下动态应用)。
数据配置与文件
数据集包含三个配置,对应三个文件:
conversations配置- 文件:
conversations/data.parquet - 描述:存储每个主题下人设的源对话历史。
- 文件:
whole_recall_mcq配置- 文件:
whole_recall_mcq/test.parquet - 描述:存储每个目标交互的一个问题,询问系统是否大致记得该交互是关于什么的。
- 文件:
slot_recall_mcq配置- 文件:
slot_recall_mcq/test.parquet - 描述:存储每个敏感细节的一个问题,询问系统是否记得该交互中的特定值。
- 文件:
数据关系
conversations/data.parquet中的一行对应一个人设-主题对话。- 一个对话行映射到多个整体回忆问题,因为对话包含许多目标交互。
- 一个整体回忆目标交互可能映射到多个细节回忆问题,因为单个交互可能包含多个细节值。
关键术语
key:为记忆控制测试而设定的交互,通常包含不应存储、之后应忘记或不应使用的信息。probe:用于测试允许信息的保留效用或普通回忆行为的交互。
数据集统计
conversations:10 行whole_recall_mcq:60 行slot_recall_mcq:362 行
数据字段说明
conversations/data.parquet 字段
sample_id:稳定标识符,用于将此对话与所有派生的问答行关联。topic:对话的主题领域。persona_id:主题子集中的合成人设索引。sample_index:此人设-主题对的样本编号。source_file:用于构建该行的原始本地源文件。original_persona:扩展前的简短种子人设。expanded_persona:合成过程中使用的扩展描述性人设文本。contains_synthetic_pii:该行是否包含仅用于测试的合成个人身份信息(PII)。persona_pii:来自人设部分的结构化 PII 对象。conversation:导出中的主要对话字段,以字符串列表形式保存源数据中使用的原始对话表示。interaction_history:与用于评估的求助目标对齐的结构化交互级历史记录。num_messages:展平所有阶段后的渲染对话行数。num_interaction_history_items:保留的交互历史记录中的项目数。
whole_recall_mcq/test.parquet 字段
- 包含连接回源对话的标识字段(
sample_id,topic,persona_id,sample_index,source_file)。 qa_family:此测试行测试对交互整体的记忆。item_index:在渲染的源文件中的项目位置。timestamp:源对话中的目标交互。turn_role:目标是关键记忆控制目标还是其他评估角色(如probe)。identifier_label:用于指代先前交互的简短人类可读标签。user_turn:被测试的原始早期用户轮次。task_goal:交互整体目的的规范化摘要。question:整体回忆多项选择题提示。choice_a,choice_b,choice_c:展示给评估者或模型的答案选项。choice_order:选项的原始显示顺序。correct_choice:正确答案字母。distractor_choice:看似合理但不正确的替代答案。not_remember_choice:表示无法记忆的弃权式答案。answer_type_to_choice:从语义答案类型到显示选项字母的映射。choice_to_answer_type:用于评估的逆映射。is_identifier_unique_to_target:标识符标签是否唯一指向目标交互。disambiguation:关于目标交互如何被消除歧义的解释。
slot_recall_mcq/test.parquet 字段
- 包含连接回源对话的标识字段(
sample_id,topic,persona_id,sample_index,source_file)。 qa_family:此测试行测试对特定细节值的记忆。parent_item_index:父整体回忆项目的索引。item_index:在渲染的源文件中的项目位置。timestamp:源对话中的目标交互。turn_role:目标是关键记忆控制目标还是其他评估角色(如probe)。identifier_label:用于指代先前交互的简短人类可读标签。user_turn:被测试的原始早期用户轮次。task_goal:交互整体目的的规范化摘要。sensitive_key:敏感信息的类别。sensitive_value:需要回忆的特定敏感值。question:细节回忆多项选择题提示。choice_a,choice_b,choice_c:展示给评估者或模型的答案选项。choice_order:选项的原始显示顺序。correct_choice:正确答案字母。distractor_choice:看似合理但不正确的替代答案。not_remember_choice:表示无法记忆的弃权式答案。answer_type_to_choice:从语义答案类型到显示选项字母的映射。choice_to_answer_type:用于评估的逆映射。
评估工作流程概要
- 从包含与记忆控制评估相关的目标交互的源对话历史开始。
- 对这些目标交互应用记忆控制操作,如
no_store、forget或no_use。 - 使用从原始对话派生的问答实例评估系统仍然记住的内容。
附加资源
- 有关当前流程中使用的质量检查和修复提示模板,请参见:https://huggingface.co/datasets/ethz-spylab/MemoryCtrl/blob/main/quality_check_prompts.md
搜集汇总
数据集介绍
构建方式
在个性化大语言模型的研究领域,MemoryCtrl数据集的构建采用了一种精心设计的合成方法。该数据集围绕虚构人物与个性化助手之间的多轮对话展开,特别聚焦于旅行规划这一具体场景。通过模拟用户在不同阶段透露个人信息以完成任务的交互过程,研究者能够系统地嵌入涉及隐私或敏感内容的关键交互。这些交互被标记为“关键”目标,用于后续测试模型在用户明确要求不存储、遗忘或避免使用特定信息时的记忆控制行为。整个构建流程确保了对话的自然性与逻辑连贯性,同时为评估任务提供了结构化的基础。
特点
MemoryCtrl数据集的核心特点在于其针对记忆控制这一前沿问题的专门设计。数据集的结构清晰地区分了源对话、整体回忆测试与细节回忆测试三个部分,分别对应不同粒度的记忆评估。源对话部分包含了完整的、基于人物设定的多阶段交互历史,为评估提供了丰富的上下文。整体回忆测试侧重于考察模型对交互事件宏观主题的记忆能力,而细节回忆测试则深入检验模型对诸如预算、医疗状况等具体敏感信息的记忆精确度。这种分层评估体系使得研究者能够细致地量化模型在不同记忆控制指令下的行为表现。
使用方法
使用MemoryCtrl数据集进行评估时,需遵循一套标准化的流程。首先,从源对话数据中选取包含目标交互的对话历史。接着,根据研究需求,对目标交互施加“不存储”、“遗忘”或“不使用”等记忆控制操作,动态生成编辑后的对话历史。然后,利用数据集提供的多项选择题表格进行评估:整体回忆问题用于测试模型对交互主题的宏观记忆,细节回忆问题则用于检验对具体敏感值的记忆。评估时,将编辑后的对话历史与相应的问题输入待测模型,通过分析其答案选择来量化模型遵循用户记忆控制指令的可靠性。
背景与挑战
背景概述
在个性化大语言模型(LLM)快速发展的背景下,如何有效控制模型对用户敏感信息的记忆成为隐私保护与个性化服务平衡的关键议题。MemoryCtrl数据集应运而生,旨在系统评估个性化LLM中的记忆控制能力。该数据集由研究团队构建,聚焦于长期交互中用户信息的有选择性存储与遗忘问题,其核心研究问题在于探索用户能否明确指导模型记忆行为,以及系统遵循这些指令的可靠性。通过合成基于人物角色的对话场景,特别是在旅行规划等具体领域,数据集为评估模型在“不存储”、“遗忘”和“不使用”三种记忆控制设定下的表现提供了标准化基准,推动了对话系统隐私与效用权衡的前沿研究。
当前挑战
MemoryCtrl数据集致力于解决个性化对话系统中记忆控制的评估挑战,其核心在于量化模型对用户指定信息的保留与遗忘能力。这一领域问题的挑战体现在模型需精准区分必要信息与敏感内容,并在长期交互中动态调整记忆状态,同时保持对话连贯性。在数据集构建过程中,挑战主要源于合成对话的真实性与复杂性平衡:需要生成包含丰富人物细节与敏感信息的多轮交互,并确保评估问题能准确反映记忆控制操作的效果。此外,设计无偏见的干扰选项以及处理合成数据与真实场景之间的泛化差距,也是构建过程中需要克服的关键难题。
常用场景
经典使用场景
在个性化大语言模型的研究领域中,MemoryCtrl数据集为评估模型记忆控制能力提供了标准化的测试平台。该数据集围绕旅行规划场景构建,模拟用户与助手之间的多轮对话,其中嵌入了敏感或临时性信息。研究者通过设计三种记忆控制操作——不存储、遗忘和不使用——来检验模型是否能够遵循用户的显式指令,从而在长期交互中实现精细化的记忆管理。这一场景典型地应用于模型鲁棒性和隐私保护能力的基准测试,为后续的系统优化提供了数据支撑。
实际应用
在实际应用层面,MemoryCtrl数据集可直接用于开发和测试具备隐私意识的对话系统,例如智能旅行助手、个性化客服或医疗咨询代理。这些系统在处理用户预算、健康信息或联系方式等敏感数据时,需能够根据用户指令动态调整记忆策略,确保数据仅在必要时被使用或存储。通过该数据集的评估,工程师能够验证系统是否可靠地实现了记忆控制功能,从而降低数据泄露风险,增强用户信任,满足日益严格的数据保护法规要求。
衍生相关工作
基于MemoryCtrl数据集,学术界衍生了一系列关于可控记忆与隐私保护的研究工作。例如,有研究利用该数据集的评估框架,探索了通过提示工程、微调或架构修改来增强模型记忆依从性的方法。其他工作则扩展了记忆控制的概念,将其应用于多模态对话或跨领域个性化任务中。这些研究不仅深化了对大语言模型记忆机制的理解,也为开发更安全、更可控的AI助手提供了技术路线和实证基础。
以上内容由遇见数据集搜集并总结生成


