microvqa
收藏Hugging Face2024-11-15 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/microvqa/microvqa
下载链接
链接失效反馈官方服务:
资源简介:
MicroVQA:一个用于显微镜科学研究的多模态推理基准。该数据集旨在评估三种关键推理能力:专家图像理解、假设生成和实验建议。它包含1,061个由生物学专家在多种显微镜模式下策划的多项选择题。
创建时间:
2024-11-14
原始信息汇总
MicroVQA 数据集概述
数据集描述
数据集摘要
MicroVQA 是一个用于显微镜基础科学研究的多模态推理基准。该数据集包含 1,061 个由生物学专家精心策划的多项选择题(MCQs),涵盖多种显微镜模式,确保 VQA 样本代表真实的科学实践。
支持的任务和排行榜
- 视觉问答(Visual-Question-Answering)
语言
- 英语(en)
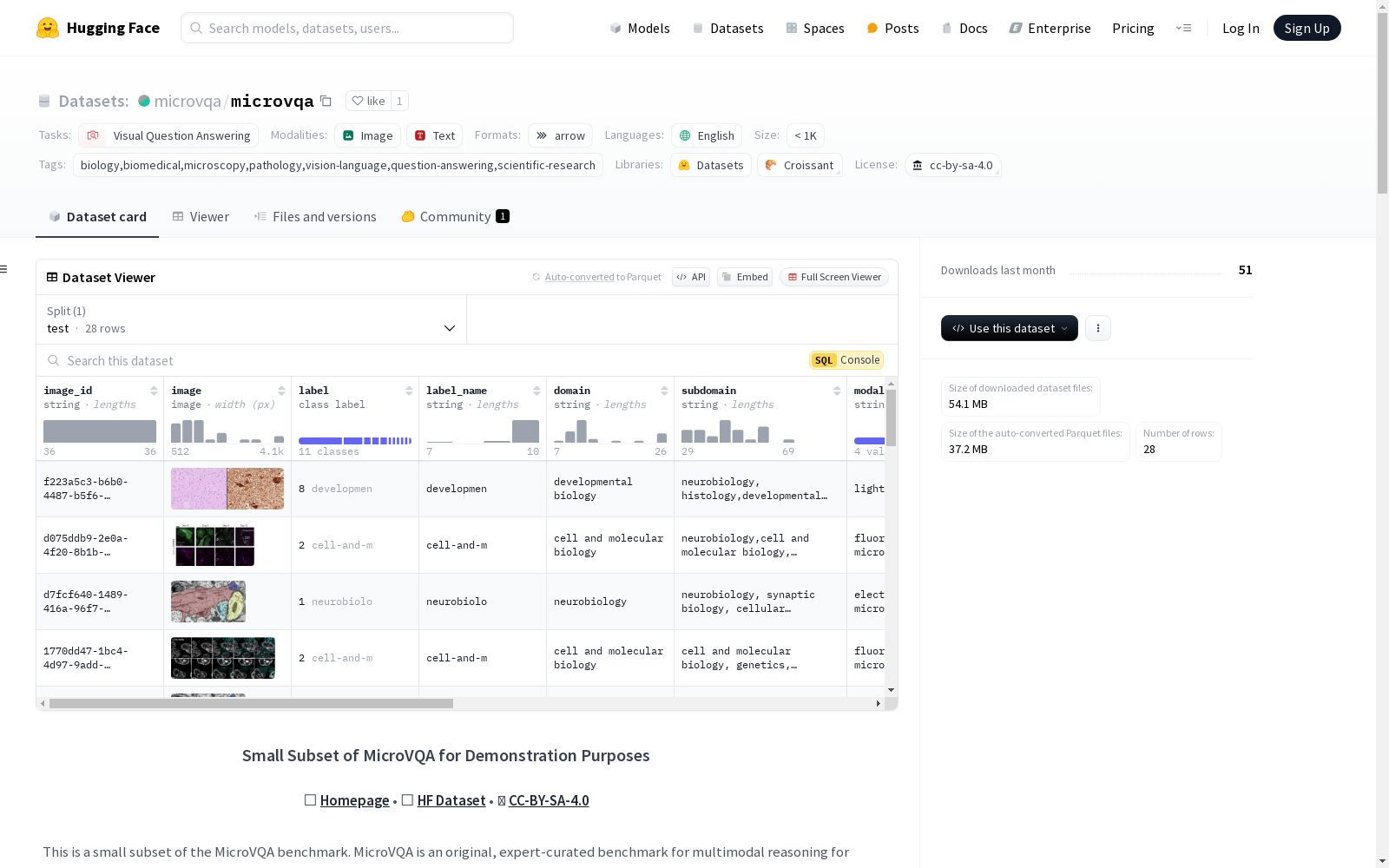
数据集结构
数据实例
每个数据实例包含以下字段:
image_id: 图像的唯一标识符image: 图像数据label: 标签label_name: 标签名称domain: 领域subdomain: 子领域modality: 显微镜模式submodality: 子模式stain: 染色类型microns_per_pixel: 每像素微米数questions: 格式化的多项选择题及其答案
数据字段
image_id: 字符串类型image: 图像数据label: 分类标签label_name: 字符串类型domain: 字符串类型subdomain: 字符串类型modality: 字符串类型submodality: 字符串类型stain: 字符串类型questions: 字符串类型(格式化的多项选择题及其答案)
数据分割
| 分割 | 实例数量 |
|---|---|
| Demo | 28 |
| Total | 1061 |
许可信息
该数据集的演示子集将根据 CC-BY-SA-4.0 许可证发布。
搜集汇总
数据集介绍
构建方式
MicroVQA数据集的构建旨在填补科学研究中复杂多模态推理的空白。该数据集由生物学专家精心策划,涵盖了多种显微镜模态下的1,061个多项选择题(MCQs)。为确保问题能够真实反映科学实践,研究者采用了一种新颖的两阶段流程:首先,通过优化的LLM提示将问题-答案对结构化为MCQs;随后,基于代理的`RefineBot`生成更具挑战性的干扰项。这一方法不仅提升了问题的难度,还确保了数据集的科学性和实用性。
特点
MicroVQA数据集的特点在于其专注于显微镜图像的多模态推理,涵盖了专家图像理解、假设生成和实验提案等关键能力。数据集中的问题设计精妙,能够有效测试模型在复杂科学场景下的推理能力。此外,数据集还提供了丰富的元数据,包括图像ID、标签、领域、子领域、模态、子模态、染色方法等,为研究者提供了全面的背景信息。这些特点使得MicroVQA成为推动AI驱动的生物医学研究的重要资源。
使用方法
MicroVQA数据集的使用方法主要围绕视觉问答(VQA)任务展开。研究者可以通过加载数据集中的图像和对应的问题,训练和评估多模态大语言模型(MLLMs)在显微镜图像上的推理能力。数据集提供了详细的元数据和问题格式,便于研究者进行数据预处理和模型训练。此外,数据集还支持链式推理分析,帮助研究者深入理解模型在多模态推理中的错误类型,从而优化模型性能。通过这种方式,MicroVQA为生物医学领域的AI研究提供了强有力的支持。
背景与挑战
背景概述
MicroVQA数据集由生物医学领域的专家团队于2024年创建,旨在填补科学研究中多模态推理领域的空白。该数据集专注于显微镜图像与文本问题的结合,评估研究流程中的关键推理能力,包括专家图像理解、假设生成和实验提案。MicroVQA包含1061个由生物专家精心策划的多项选择题,涵盖了多种显微镜模态,确保问题样本能够真实反映科学实践。该数据集的推出为AI驱动的生物医学研究提供了宝贵的资源,推动了多模态大语言模型在科学发现中的应用。
常用场景
经典使用场景
MicroVQA数据集在生物医学研究领域中,主要用于评估多模态推理能力,特别是在显微镜图像的理解、假设生成和实验设计方面。通过提供多样化的显微镜图像和相关的多选问题,该数据集为研究人员提供了一个标准化的测试平台,用于验证和改进多模态大语言模型(MLLMs)在科学发现中的表现。
衍生相关工作
MicroVQA数据集的推出,催生了一系列相关研究工作,特别是在多模态推理和AI辅助生物医学研究领域。基于该数据集的研究不仅改进了多模态大语言模型的性能,还推动了科学文献在模型训练中的应用,进一步提升了模型在复杂科学推理任务中的表现。
数据集最近研究
最新研究方向
在生物医学领域,显微镜图像与自然语言处理的结合正成为研究热点。MicroVQA数据集作为一项多模态推理基准,专注于显微镜图像的科学问题解答,旨在评估专家图像理解、假设生成和实验提案等关键推理能力。该数据集由生物专家精心策划,涵盖多种显微镜模态,确保了问题的科学性和实践性。最新研究表明,尽管多模态大语言模型(MLLMs)在AI辅助研究中取得了显著进展,但在复杂科学推理任务中的表现仍存在局限。MicroVQA通过引入两阶段生成流程,优化了多选题的创建方法,并利用基于代理的`RefineBot`生成更具挑战性的干扰项,显著提升了推理难度。专家对模型推理失败的分析表明,多模态推理错误频发,知识错误和过度泛化也是常见问题。这些发现不仅揭示了多模态科学推理的挑战,也为AI驱动的生物医学研究提供了宝贵的资源。
以上内容由遇见数据集搜集并总结生成


