text-2-image-Rich-Human-Feedback-32k
收藏Hugging Face2025-04-28 更新2025-04-29 收录
下载链接:
https://huggingface.co/datasets/Rapidata/text-2-image-Rich-Human-Feedback-32k
下载链接
链接失效反馈官方服务:
资源简介:
这个数据集包含了图像名称、句子、单词评分、对齐分数、连贯性分数、风格评分以及用于对齐和连贯性的热图等特征。数据集被分为包含32,528个示例的训练集,可以通过Huggingface数据集库访问。README提供了如何使用数据集和复制注释设置的示例。它还包括数据的摘要,包括单词评分、连贯性、对齐和风格部分。此外,README还提到了Rapidata提供的其他数据集和基准。
创建时间:
2025-04-24
原始信息汇总
数据集概述:text-2-image-Rich-Human-Feedback-32k
基本信息
- 数据集名称:text-2-image-Rich-Human-Feedback-32k
- 数据来源:Rapidata通过Python API收集的人类反馈数据
- 数据规模:
- 训练集样本数:32,528
- 下载大小:91.22 GB
- 数据集大小:116.62 GB
数据集特征
- 主要特征:
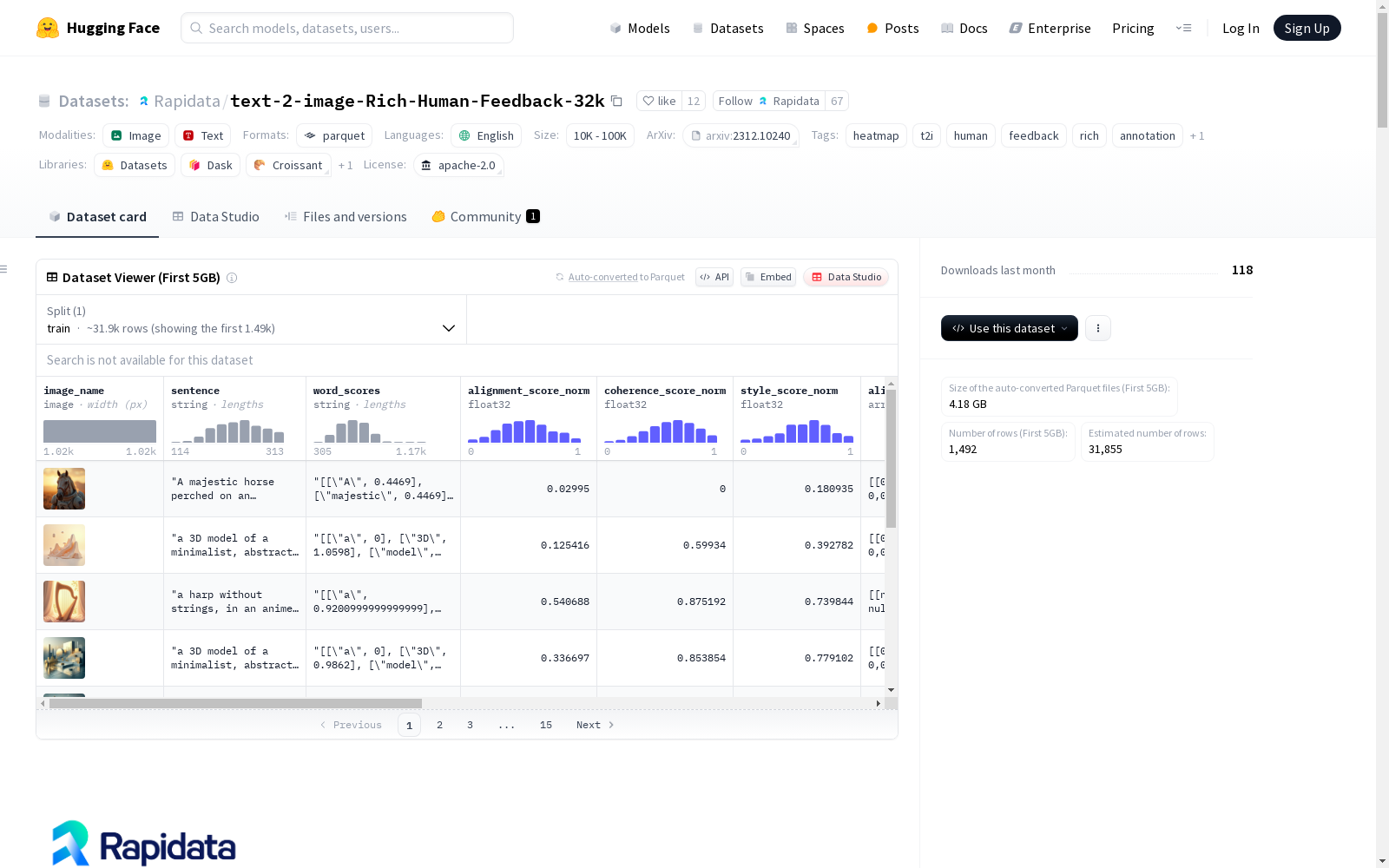
image_name:图像数据sentence:文本描述(字符串)word_scores:未被准确描绘的单词及其得分(字符串)alignment_score_norm:归一化的对齐得分(float32)coherence_score_norm:归一化的连贯性得分(float32)style_score_norm:归一化的风格得分(float32)alignment_heatmap:对齐热图(1024x1024 float32数组)coherence_heatmap:连贯性热图(1024x1024 float32数组)alignment_score:原始对齐得分(float32)coherence_score:原始连贯性得分(float32)style_score:原始风格得分(float32)
数据收集与标注
-
标注内容:
- 单词得分:用户标识未被准确描绘的单词,高分表示表现较差。
- 连贯性评分:评估图像是否逻辑一致且无视觉瑕疵(1-5分,5为最高)。
- 对齐评分:评估图像与文本描述的匹配程度(1-5分,5为最高)。
- 风格评分:评估图像的视觉吸引力(1-5分,5为最高)。
-
标注规模:
- 总响应数:超过370万
- 参与人数:307,415人
- 收集时间:不到2周
使用示例
-
加载数据集: python from datasets import load_dataset ds = load_dataset("Rapidata/text-2-image-Rich-Human-Feedback-32k", split="train", streaming=True)
-
生成单词得分图: python
代码示例见数据集详情页
-
生成热图: python
代码示例见数据集详情页
数据集应用
- 研究领域:文本到图像生成模型的评估与改进
- 适用场景:
- 模型对齐性研究
- 图像生成质量评估
- 人类偏好建模
相关资源
- 博客文章:Beyond Image Preferences
- 其他数据集:
标注流程复现
- 工具:Rapidata Python API
- 步骤:
- 安装Rapidata客户端
- 创建分类任务(Likert量表)
- 创建定位任务(热图生成)
- 创建单词选择任务(标识未对齐单词)
搜集汇总
数据集介绍
构建方式
该数据集的构建基于Google的研究成果《Rich Human Feedback for Text-to-Image Generation》,并通过Rapidata平台收集了来自307,415名个体的370万条反馈数据。数据收集过程在两周内完成,涵盖了图像风格、连贯性及与提示词的匹配度等多个维度的评估。参与者不仅对图像质量进行了评分,还标注了图像中未准确反映提示词的区域,生成了详细的热力图和词级评分。
特点
数据集包含32,528个样本,每个样本均包含图像、提示词、词级评分、标准化评分及热力图等多模态数据。其独特之处在于提供了细粒度的词级标注和热力图,能够精确反映图像与文本的局部对齐情况。此外,所有评分均基于至少21人的独立评估,确保了数据的可靠性和代表性。数据集覆盖156个国家的多样化审美偏好,为跨文化研究提供了宝贵资源。
使用方法
通过HuggingFace的`datasets`库可便捷加载数据,建议使用流式传输模式以提升效率。数据集支持多种分析场景:词级评分可用于文本-图像对齐研究,热力图可辅助定位生成缺陷,标准化评分便于模型性能评估。示例代码展示了如何可视化词级标注和热力图叠加效果,为研究者提供开箱即用的分析工具。
背景与挑战
背景概述
text-2-image-Rich-Human-Feedback-32k数据集由Rapidata团队基于Google的研究成果《Rich Human Feedback for Text-to-Image Generation》构建,旨在深化文本到图像生成领域的人类反馈机制。该数据集扩展了早期版本,收集了来自307,415名参与者的370万条反馈,覆盖156个国家的多样化人群。其核心研究问题聚焦于评估生成图像在风格、连贯性和提示对齐三个维度的表现,通过量化评分和热力图标注,为生成模型的优化提供了细粒度的人类偏好数据。数据集的构建仅耗时两周,展现了高效的大规模标注能力,为文本到图像生成领域设立了新的评估基准。
当前挑战
该数据集面临的挑战主要体现在两个方面:领域问题层面,文本到图像对齐的标注一致性难以保证,例如缺失对象的标注存在歧义;构建过程层面,需平衡大规模数据收集与标注质量的控制,尤其是跨文化审美差异对风格评分的影响。此外,热力图标注要求参与者精准定位图像缺陷,这对标注界面设计和参与者培训提出了较高要求。数据集还需解决长尾分布问题,确保低频率提示词组合的评估覆盖率。
常用场景
经典使用场景
在文本到图像生成领域,text-2-image-Rich-Human-Feedback-32k数据集通过大规模人类反馈为模型评估提供了多维度的量化标准。该数据集最经典的使用场景在于评估生成图像与文本提示的匹配程度,研究人员可利用其丰富的标注信息,包括对齐分数、连贯性分数和风格分数,对生成模型进行细粒度的性能分析。特别是在评估图像与文本语义一致性时,数据集提供的热力图和词级评分能够直观揭示模型在特定词汇或区域的表现缺陷。
实际应用
在实际应用中,该数据集为商业图像生成系统的优化提供了重要参考。AI产品团队可利用数据集中的热力图定位高频错误区域,针对性改进模型架构或训练策略。教育科技领域可基于风格评分开发审美评估模块,辅助艺术创作教学。此外,数据集涵盖156个国家参与者的多样性反馈,为全球化产品设计提供了文化适应性评估依据,避免了单一审美偏好带来的偏差。
衍生相关工作
该数据集推动了多项文本到图像生成领域的创新研究。基于其构建的评估框架被应用于Stable Diffusion、DALL-E等主流模型的迭代优化。Google研究团队在原始论文中提出的多维度评估方法已成为领域基准,启发了后续工作如CLIP-Score等自动评估指标的改进。数据集提供的细粒度反馈还催生了新的研究方向,如基于词级对齐损失的训练策略和热力图引导的图像修复技术。
以上内容由遇见数据集搜集并总结生成


