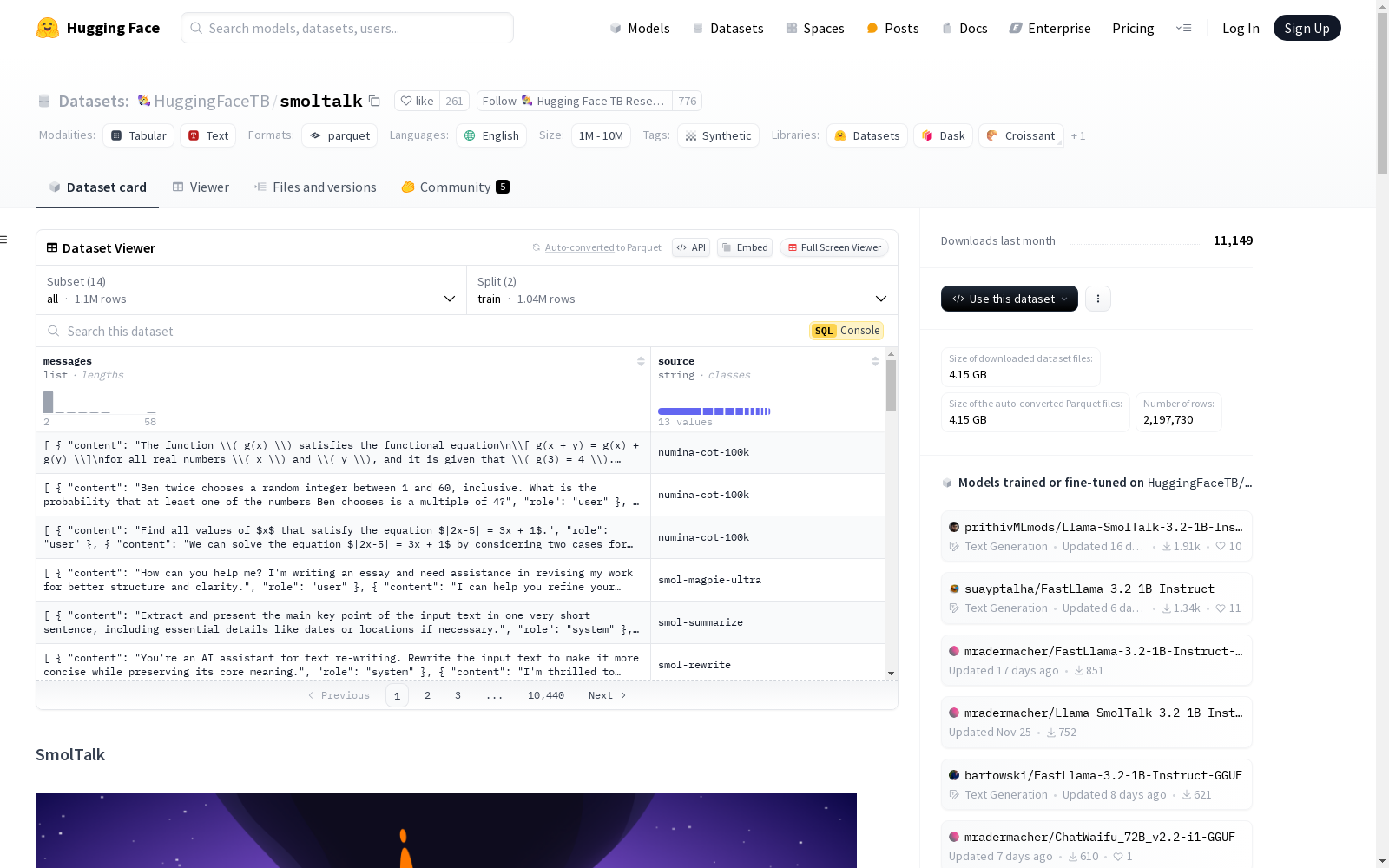
smoltalk
收藏SmolTalk 数据集概述
基本信息
- 许可证: Apache 2.0
- 语言: 英语
- 标签: 合成数据
- 数据集大小: 1M<n<10M
数据集配置
-
配置名称: all
- 数据文件:
- 训练集: data/all/train-*
- 测试集: data/all/test-*
- 数据文件:
-
配置名称: smol-magpie-ultra
- 数据文件:
- 训练集: data/smol-magpie-ultra/train-*
- 测试集: data/smol-magpie-ultra/test-*
- 数据文件:
-
配置名称: smol-constraints
- 数据文件:
- 训练集: data/smol-constraints/train-*
- 测试集: data/smol-constraints/test-*
- 数据文件:
-
配置名称: smol-rewrite
- 数据文件:
- 训练集: data/smol-rewrite/train-*
- 测试集: data/smol-rewrite/test-*
- 数据文件:
-
配置名称: smol-summarize
- 数据文件:
- 训练集: data/smol-summarize/train-*
- 测试集: data/smol-summarize/test-*
- 数据文件:
-
配置名称: apigen-80k
- 数据文件:
- 训练集: data/apigen-80k/train-*
- 测试集: data/apigen-80k/test-*
- 数据文件:
-
配置名称: everyday-conversations
- 数据文件:
- 训练集: data/everyday-conversations/train-*
- 测试集: data/everyday-conversations/test-*
- 数据文件:
-
配置名称: explore-instruct-rewriting
- 数据文件:
- 训练集: data/explore-instruct-rewriting/train-*
- 测试集: data/explore-instruct-rewriting/test-*
- 数据文件:
-
配置名称: longalign
- 数据文件:
- 训练集: data/longalign/train-*
- 测试集: data/longalign/test-*
- 数据文件:
-
配置名称: metamathqa-50k
- 数据文件:
- 训练集: data/metamathqa-50k/train-*
- 测试集: data/metamathqa-50k/test-*
- 数据文件:
-
配置名称: numina-cot-100k
- 数据文件:
- 训练集: data/numina-cot-100k/train-*
- 测试集: data/numina-cot-100k/test-*
- 数据文件:
-
配置名称: openhermes-100k
- 数据文件:
- 训练集: data/openhermes-100k/train-*
- 测试集: data/openhermes-100k/test-*
- 数据文件:
-
配置名称: self-oss-instruct
- 数据文件:
- 训练集: data/self-oss-instruct/train-*
- 测试集: data/self-oss-instruct/test-*
- 数据文件:
-
配置名称: systemchats-30k
- 数据文件:
- 训练集: data/systemchats-30k/train-*
- 测试集: data/systemchats-30k/test-*
- 数据文件:
数据集描述
SmolTalk 是一个用于监督微调(SFT)的大型语言模型(LLM)的合成数据集,包含100万样本。该数据集用于构建 SmolLM2-Instruct 系列模型。
数据集组成
新数据集
- Smol-Magpie-Ultra: 包含40万样本,使用Magpie管道生成,经过严格筛选和过滤。
- Smol-constraints: 包含3.6万样本,训练模型遵循特定约束。
- Smol-rewrite: 包含5万样本,专注于文本重写任务。
- Smol-summarize: 包含10万样本,专注于电子邮件和新闻摘要。
现有公共数据集
- OpenHermes2.5: 包含10万样本,用于提升MMLU、WinoGrande和BBH等基准。
- MetaMathQA: 包含5万样本,用于提升数学和推理能力。
- NuminaMath-CoT: 用于提升数学能力,特别是解决难题。
- Self-Oss-Starcoder2-Instruct: 用于提升编码能力。
- SystemChats2.0: 包含3万样本,用于支持多种系统提示格式。
- LongAlign: 包含1万样本,用于提升长上下文理解能力。
- Everyday-conversations: 包含2千样本,用于日常对话。
- APIGen-Function-Calling: 包含8万样本,用于API函数调用。
- Explore-Instruct-Rewriting: 包含3万样本,用于指令重写。
评估
SmolTalk 数据集在微调 SmolLM2 模型时表现优异,特别是在 IFEval、BBH、GS8Mk 和 MATH 等基准上。
许可证
Apache 2.0
引用
bash @misc{allal2024SmolLM2, title={SmolLM2 - with great data, comes great performance}, author={Loubna Ben Allal and Anton Lozhkov and Elie Bakouch and Gabriel Martín Blázquez and Lewis Tunstall and Agustín Piqueres and Andres Marafioti and Cyril Zakka and Leandro von Werra and Thomas Wolf}, year={2024}, }