---
language:
- en
license: other
size_categories:
- 1K<n<10K
task_categories:
- text-classification
- text-generation
- reinforcement-learning
pretty_name: 10k_prompts_ranked
dataset_info:
features:
- name: prompt
dtype: string
id: field
- name: quality
list:
- name: user_id
dtype: string
id: question
- name: value
dtype: string
id: suggestion
- name: status
dtype: string
id: question
- name: metadata
dtype: string
id: metadata
- name: avg_rating
dtype: float64
- name: num_responses
dtype: int64
- name: agreement_ratio
dtype: float64
- name: raw_responses
sequence: int64
- name: kind
dtype: string
- name: cluster_description
dtype: string
- name: topic
dtype: string
splits:
- name: train
num_bytes: 8705892
num_examples: 10331
download_size: 3579688
dataset_size: 8705892
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
tags:
- preference
- prompts
- argilla
- synthetic
---
# Dataset Card for 10k_prompts_ranked
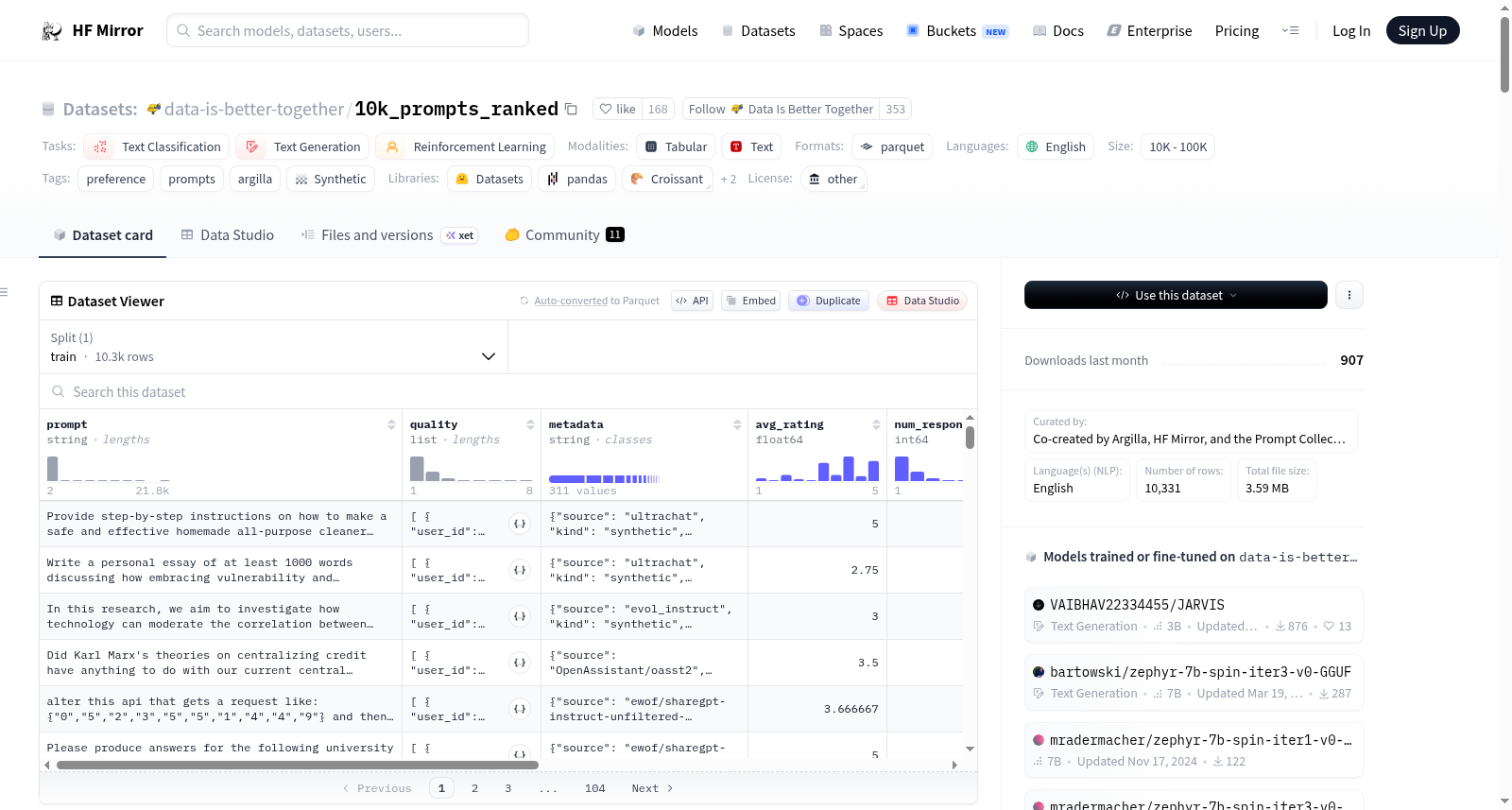
`10k_prompts_ranked` is a dataset of prompts with quality rankings created by 314 members of the open-source ML community using Argilla, an open-source tool to label data. The prompts in this dataset include both synthetic and human-generated prompts sourced from a variety of heavily used datasets that include prompts.
The dataset contains 10,331 examples and can be used for training and evaluating language models on prompt ranking tasks. The dataset is the output of a novel crowdsourcing effort and can thus also be used to study the behavior of annotators contributing rankings as part of a community effort to rank prompts.
<center>
<div>
<img src="https://cdn-uploads.huggingface.co/production/uploads/60107b385ac3e86b3ea4fc34/mj1JOorVwP-LT9POfyJiN.png" width="50%">
</div>
<em>Data is Better Together</em>
</center>
**Want to contribute to the V2 release of this dataset?** You can start rating prompts in a few seconds [here](https://huggingface.co/spaces/DIBT/prompt-collective)
## Dataset Details
This dataset is the first release out of the `Data-is-Better-Together` collective, a project created by [Argilla](https://huggingface.co/argilla) and Hugging Face to explore how Argilla and [Hugging Face Spaces](https://huggingface.co/docs/hub/spaces) could be used to collectively create impactful datasets within the community.
The dataset was created by collecting prompts from various existing sources and ranking them using an instance of [Argilla](https://argilla.io/) hosted on a Hugging Face Space with Hugging Face authentication enabled. This allowed anyone with an existing Hugging Face account to very quickly begin contributing to the dataset.
<center>
<a href="https://huggingface.co/spaces/DIBT/prompt-collective">
<img src="https://cdn-uploads.huggingface.co/production/uploads/60107b385ac3e86b3ea4fc34/SCykTMYyc29kYgv7Frg_-.png", alt="Sign in page for Argilla on Spaces" width="75%"/></a>
</center>
### Dataset Description
- **Curated by:** Co-created by Argilla, Hugging Face, and the Prompt Collective community.
- **Language(s) (NLP):** English
- **License:** [More Information Needed]
#### Data Visualization
Click the [Nomic Atlas](https://atlas.nomic.ai/map/475c26d7-b142-4795-9887-02b6eeb18dc0/0d312be6-a3bb-4586-b6b7-53dcd0cbefa5) map below to visualize the distribution of the prompts in the dataset and explore the topics identified in the prompts by Nomic Atlas.
<center>
<a href="https://atlas.nomic.ai/data/hivemind/dibt-10k-prompt-collective/map">
<img src="https://cdn-uploads.huggingface.co/production/uploads/60107b385ac3e86b3ea4fc34/SGP-N-zjyJwfRJDKpIJe0.png" alt="Nomic-Atlas 10K_prompts_ranked Map" width="75%"/>
</a>
</center>
## Uses
There are many potential uses for this dataset. Key uses include:
- Training and evaluating language models on prompt ranking tasks.
- As a dataset that can be filtered only to include high-quality prompts. These can serve as seed data for generating synthetic prompts and generations.
Beyond this direct use, the dataset is also the output of a novel crowdsourcing effort and can be used to study the behaviour of annotators contributing to datasets as part of a community effort to rank prompts. This includes exploring:
- The distribution of prompt rankings based on the source of the prompt.
- The distribution of prompt rankings based on the prompt's type, length, or other features.
- The agreement of annotators on prompt rankings and the factors that influence agreement, i.e. prompt source, prompt type, prompt length, etc.
### Direct Use
To load the data using the `datasets` library, you can use the following code:
```python
from datasets import load_dataset
ds = load_dataset("10k_prompts_ranked")
```
### Out-of-Scope Use
This dataset only contains rankings for prompts, not prompt/response pairs so it is not suitable for direct use for supervised fine-tuning of language models.
## Dataset Structure
A single instance of the dataset looks as follows:
```python
{'prompt': 'Provide step-by-step instructions on how to make a safe and effective homemade all-purpose cleaner from common household ingredients. The guide should include measurements, tips for storing the cleaner, and additional variations or scents that can be added. Additionally, the guide should be written in clear and concise language, with helpful visuals or photographs to aid in the process.',
'quality': [{'user_id': 'd23b12c2-b601-490e-b5b3-2040eb393a00',
'value': '4',
'status': 'submitted'},
{'user_id': 'e2bdd868-f28e-46fc-9254-a6ec1e291889',
'value': '4',
'status': 'submitted'}],
'metadata': {'evolved_from': None,
'kind': 'synthetic',
'source': 'ultrachat'},
'avg_rating': 5.0,
'num_responses': 2,
'agreement_ratio': 1.0,
'raw_responses': [5, 5],
'kind': 'synthetic'}
```
The dataset contains the following fields:
- prompt: The prompt to be ranked.
- quality: A list of user rankings for the prompt. Each ranking includes the user_id, the value of the ranking, and the status of the ranking (we only include rankings that have been submitted).
- metadata: Additional information about the prompt including the source of the prompt, whether it was synthetic or human-generated, and whether it was evolved from another prompt.
- avg_rating: The average rating of the prompt.
- num_responses: The number of responses for the prompt.
- agreement_ratio: The agreement ratio for the prompt.
- raw_responses: The raw responses for the prompt by annotators. This can be used to calculate the agreement ratio differently.
- kind: The kind of prompt (synthetic or human-generated).
## Dataset Creation
Version one of the dataset was created in about 3 weeks. The first week involved some prep work and the creation of the Argilla instance. The actual generation of 10,000 prompt rankings was done in two weeks.
### Curation Rationale
The dataset was created to explore how Argilla and Hugging Face Spaces could be used to create impactful datasets within the community collectively. The dataset was also created to provide a high-quality dataset for prompt ranking tasks and to study the behavior of annotators contributing rankings as part of a community effort to rank prompts.
### Source Data
As discussed above, the prompts in this dataset are derived from a variety of heavily used datasets that include prompts. The following table shows the sources of the prompts in the dataset and the number of examples from each source. Datasets with a `#` in the dataset indicate the subset of the dataset that was used.
| Dataset | # Examples |
| ----------------------------------------- | ---------- |
| ewof/sharegpt-instruct-unfiltered-deduped | 4,479 |
| evol_instruct | 1,381 |
| ultrachat | 1,307 |
| OpenAssistant/oasst2 | 734 |
| argilla/DistiCoder-dpo-binarized | 705 |
| flan_v2_cot | 360 |
| argilla/distilabel-reasoning-prompts | 328 |
| argilla/distilabel-evol-prompt-collective | 282 |
| LDJnr/Capybara#Dove | 253 |
| ProlificAI/social-reasoning-rlhf | 145 |
| LDJnr/Capybara#GOAT | 123 |
| LDJnr/Capybara#TaskSource | 117 |
| LDJnr/Capybara#TheoremQA | 88 |
| LDJnr/Capybara#Verified-Camel | 19 |
| fka/awesome-chatgpt-prompts | 8 |
| LDJnr/Capybara#Tigerbot | 2 |
#### Synthetic vs Human-Generated Prompts
The breakdown of the prompts in the dataset by kind is as follows:
<center>
<img src="https://cdn-uploads.huggingface.co/production/uploads/60107b385ac3e86b3ea4fc34/mIWyxv1y5-3A54hGv-Re-.png", alt="Sign in page for Argilla on Spaces" width="75%"/><
</center>
The "unknown" kind is a result of the fact that the source of the prompt was not known for some of the prompts in the dataset.
#### Who are the source data producers?
The source datasets used to generate the prompts in this dataset were created by academics, industry researchers, and open-source contributors.
### Annotations
This dataset contains human-generated annotations of prompt quality. Prompts are ranked on a scale of 1-5, with 1 being the lowest quality and 5 being the highest quality. The dataset contains 10,331 examples.
| Number of rankings | Frequency |
| -----------------: | --------: |
| 1 | 6,730 |
| 2 | 2,600 |
| 3 | 748 |
| 4 | 192 |
| 5 | 52 |
| 6 | 5 |
| 7 | 3 |
| 8 | 1 |
#### Distribution of ratings across dataset type
<center>
<img src="https://cdn-uploads.huggingface.co/production/uploads/60107b385ac3e86b3ea4fc34/ttqT8izhSMI-SZ9OS3Rig.png", alt="Sign in page for Argilla on Spaces" width="75%"/><
</center>
#### Annotation process
The dataset was created by collecting prompts from various sources and then ranking them using an instance of Argilla hosted on a Hugging Face Space with Hugging Face authentication enabled. This allowed anyone with an existing Hugging Face account to rank the prompts.
#### Who are the annotators?
The annotators are 314 Hugging Face community members. We do not have demographic information about the annotators.
#### Personal and Sensitive Information
We are not aware of any personal or sensitive information in the dataset.
## Citation
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
## Glossary
<!-- If relevant, include terms and calculations in this section that can help readers understand the dataset or dataset card. -->
- **Argilla**: An open source annotation tool focused on methods for efficiently building high-quality datasets for LLMs and other NLP models.
- **Hugging Face Spaces**: A platform for hosting machine learning applications and demos.
- **Synthetic data**: Data that is generated using some computational method (primarily and Large Language Model)