ScandalousMan/items_prompts_full
收藏Hugging Face2026-04-25 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/ScandalousMan/items_prompts_full
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
features:
- name: prompt
dtype: string
- name: completion
dtype: string
splits:
- name: train
num_bytes: 343250234
num_examples: 800000
- name: val
num_bytes: 4291752
num_examples: 10000
- name: test
num_bytes: 4288537
num_examples: 10000
download_size: 176746432
dataset_size: 351830523
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: val
path: data/val-*
- split: test
path: data/test-*
---
提供机构:
ScandalousMan
搜集汇总
数据集介绍
构建方式
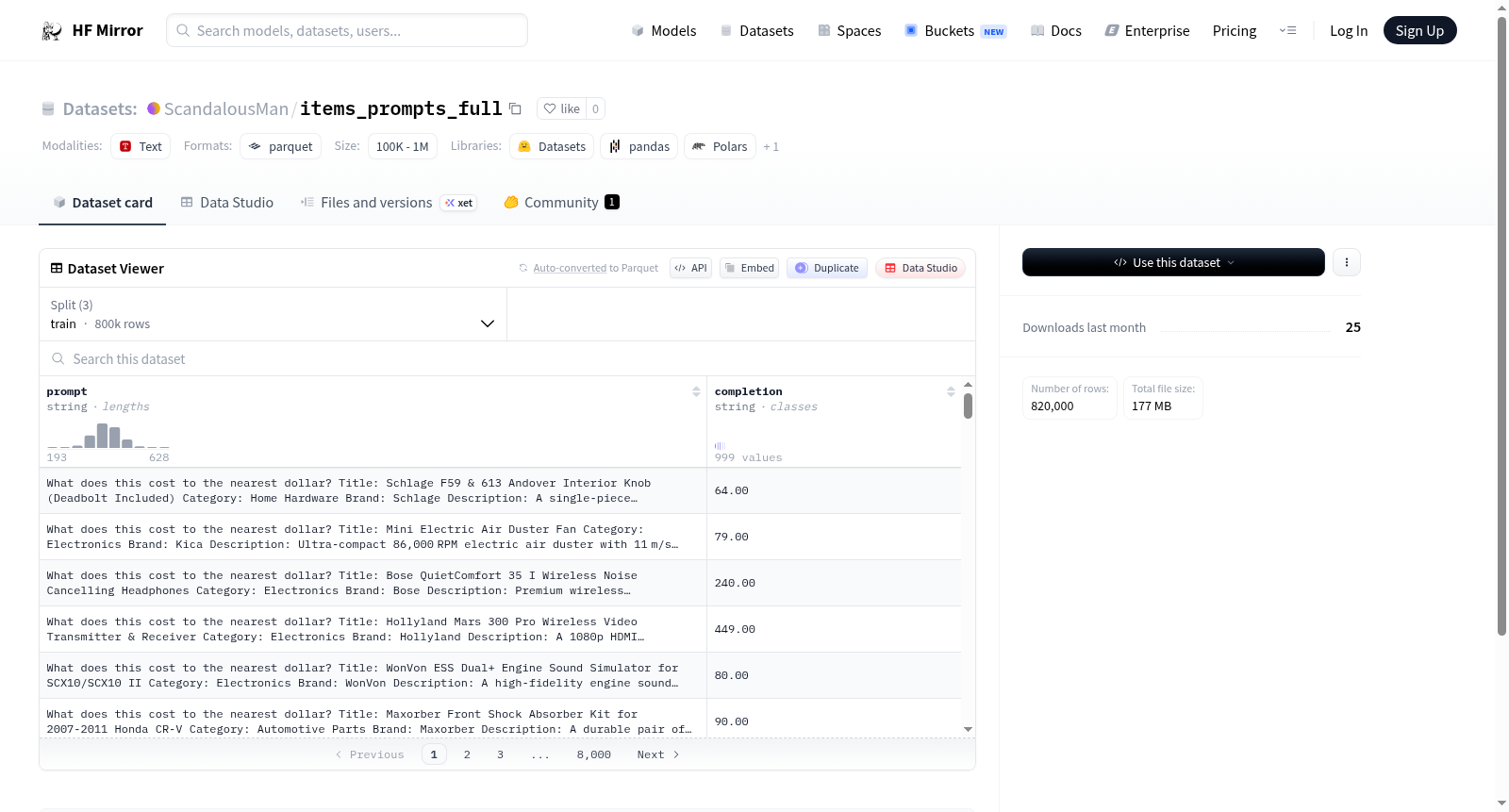
items_prompts_full数据集通过收集和整理海量文本对进行构建,每个样本包含一个“prompt”字段和一个对应的“completion”字段,形成结构化的输入输出对。数据集被划分为训练集、验证集和测试集三个子集,其中训练集包含800,000个样本,验证集和测试集各含10,000个样本。数据以分片形式存储,便于高效加载和处理。
特点
该数据集合共包含820,000个高质量的文本对,总数据量约为351.8兆字节,规模宏大且分布均衡。训练集占据绝大多数样本,为模型训练提供了丰富的语料资源,而验证集和测试集的样本数量一致,便于进行公平的模型性能评估。数据格式简洁统一,仅有提示和补全两个字段,降低了预处理复杂度。
使用方法
用户可通过HuggingFace数据集库的load_dataset方法轻松加载该数据集,指定配置名称为'default'即可获得训练、验证和测试三个分片。在模型微调或评估时,可直接将'prompt'字段作为输入,'completion'字段作为目标输出,适用于文本生成、指令跟随等自然语言处理任务,支持灵活的数据流式读取。
背景与挑战
背景概述
在自然语言处理与生成式模型的研究中,高质量的指令微调数据是提升模型对齐能力与任务泛化性能的关键基石。items_prompts_full 数据集于近年由相关研究机构构建,包含约82万条提示-完成对,划分为训练集、验证集和测试集,专注于为大规模语言模型提供结构化的指令跟随训练素材。该数据集通过系统收集多样化的提示与对应完成文本,旨在解决模型在复杂指令理解与多领域响应生成中的一致性问题。其规模与设计对推动指令微调范式的完善、增强模型在实际应用场景中的可控性与准确性具有重要影响,成为领域内评估模型对齐能力的基础资源之一。
当前挑战
该数据集的核心挑战在于解决领域内指令跟随模型的泛化与对齐难题。一方面,模型需从有限的高质量提示-完成对中学习到对隐式意图的精准理解,避免对模板化指令的过拟合,从而在开放式任务中保持鲁棒性。另一方面,数据集构建过程面临质量控制的困难,包括确保完成文本的多样性、标注一致性以及在覆盖长尾场景时的平衡性,同时需要避免潜在偏见与有害内容的混入,这要求精细的过滤与审核机制。此外,在82万条样本规模下,有效区分有效指令与噪声数据、维持合理的难度分布也是维护数据集实用性的关键障碍。
常用场景
经典使用场景
该数据集包含80万条训练样本、1万条验证样本和1万条测试样本,每条样本由prompt和completion两部分构成,是典型的文本生成任务数据集。其经典使用场景集中在语言模型的指令微调(Instruction Tuning)和提示学习(Prompt Learning)领域,研究人员可借助此数据集训练模型理解并执行多样化的自然语言指令,从而提升模型在零样本或少样本场景下的泛化能力。
衍生相关工作
该数据集衍生的工作包括基于指令微调的模型压缩与蒸馏方法、提示工程的自动化优化算法,以及多任务联合训练框架。经典研究如FLAN、InstructGPT等均采用类似范式,通过大规模指令数据集训练出具备强大泛化能力的语言模型。此外,该数据集也催生了针对少样本学习、对抗性提示攻击防御等方向的后续探索,成为指令驱动型AI发展的重要基石。
数据集最近研究
最新研究方向
在大型语言模型与多模态对齐研究的浪潮中,items_prompts_full数据集凭借其包含80万条高质量指令-完成对的结构化语料,成为当前探索指令微调与零样本泛化能力的前沿阵地。该数据集通过精心设计的提示词与完整回答的配对,为研究模型在未见任务上的涌现能力提供了丰富的训练测试基底。结合近期业界对指令遵循与对齐控制的热点追求,此数据集被广泛用于剖析语言模型在多样化场景下的语义理解与适应性生成,其精心划分的训练、验证与测试集更推动了模型泛化瓶颈的突破性进展,对构建更稳健、更可控的通用人工智能系统具有里程碑式的基石意义。
以上内容由遇见数据集搜集并总结生成


