有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
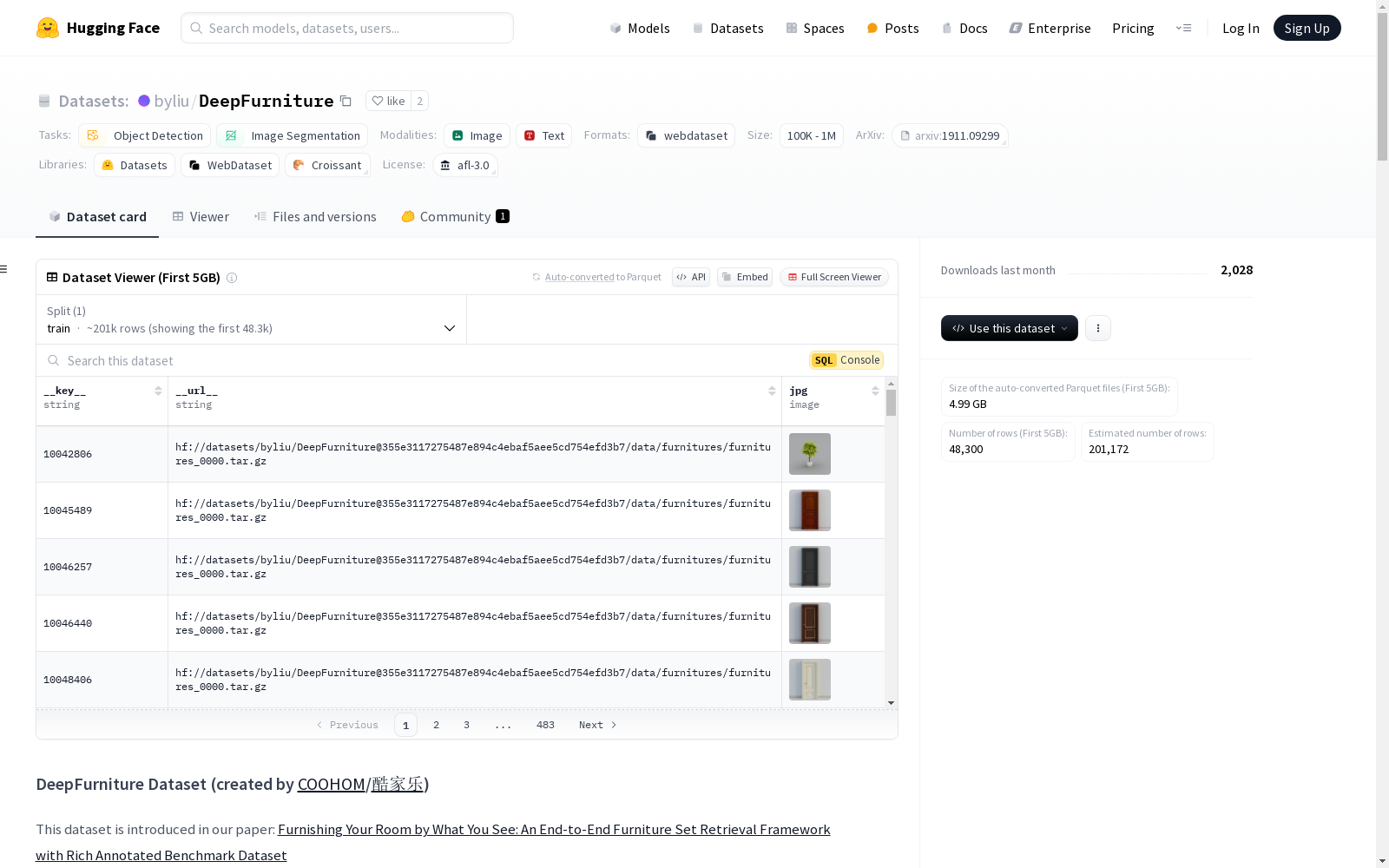
DeepFurniture 数据集是一个大规模的家具理解数据集,包含约 24,000 张室内图像、170,000 个家具实例和 20,000 个独特的家具身份。所有图像均由 COOHOM 的专业渲染引擎生成,具有高真实感的渲染效果和高品质的 3D 家具模型。
DeepFurniture 提供三个级别的分层注释:
该数据集支持三个主要基准测试:
数据集按块组织,以便于高效分发:
data/ ├── scenes/ # 照片级真实感渲染的室内场景 ├── furnitures/ # 高质量 3D 模型预览渲染 ├── queries/ # 从场景中裁剪的家具实例图像 └── metadata/ # 数据集信息和索引 ├── categories.json # 家具类别定义 ├── styles.json # 风格标签定义 ├── dataset_info.json # 数据集统计信息 ├── furnitures.jsonl # 家具元数据 └── *_index.json # 块索引文件
bash
git lfs install # 确保安装了 Git LFS git clone https://huggingface.co/datasets/byliu/DeepFurniture
[furnitureID]_[instanceIndex]_[sceneID].jpgpython from deepfurniture import DeepFurnitureDataset
dataset = DeepFurnitureDataset("path/to/uncompressed_data")
scene = dataset[0] print(f"Scene ID: {scene[scene_id]}") print(f"Number of instances: {len(scene[instances])}")
for instance in scene[instances]: print(f"Category: {instance[category_name]}") print(f"Style(s): {instance[style_names]}")
python visualize_html.py --dataset ./uncompressed_data --scene_idx 101 --output scene_101.html
CE-CSL
CE-CSL数据集是由哈尔滨工程大学智能科学与工程学院创建的中文连续手语数据集,旨在解决现有数据集在复杂环境下的局限性。该数据集包含5,988个从日常生活场景中收集的连续手语视频片段,涵盖超过70种不同的复杂背景,确保了数据集的代表性和泛化能力。数据集的创建过程严格遵循实际应用导向,通过收集大量真实场景下的手语视频材料,覆盖了广泛的情境变化和环境复杂性。CE-CSL数据集主要应用于连续手语识别领域,旨在提高手语识别技术在复杂环境中的准确性和效率,促进聋人与听人社区之间的无障碍沟通。
arXiv 收录
Coffee_Shop_Sales
该数据集包含了咖啡店的详细交易信息,包括交易ID、日期、时间、店铺编号、位置、产品类别、类型、名称、价格、月份、日期、星期和小时等属性。数据集用于分析咖啡店的销售情况,如收入和交易量的变化趋势。
github 收录
中国行政区划数据
本项目为中国行政区划数据,包括省级、地级、县级、乡级和村级五级行政区划数据。数据来源于国家统计局,存储格式为sqlite3 db文件,支持直接使用数据库连接工具打开。
github 收录
农业农作物生长全周期数据集
农业农作物生长全周期数据集通过整合农作物、农场面积、刺激类型、肥料用量、杀虫剂使用量、产量、土壤类型、季节和用水量等多维度数据,实现农业生产的精准化管理和可持续发展。
浙江大数据交易服务平台 收录
TCIA
TCIA(The Cancer Imaging Archive)是一个公开的癌症影像数据集,包含多种癌症类型的医学影像数据,如CT、MRI、PET等。这些数据通常与临床和病理信息相结合,用于癌症研究和临床试验。
www.cancerimagingarchive.net 收录