pavlov-erg/mmstar-icam-retinex-msrcr-15-80-250-test
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/pavlov-erg/mmstar-icam-retinex-msrcr-15-80-250-test
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
features:
- name: idx
dtype: int64
- name: id
dtype: int64
- name: type
dtype: string
- name: task
dtype: string
- name: filename
dtype: string
- name: image
dtype: image
- name: prompt
dtype: string
- name: question
dtype: string
- name: choices
list: string
- name: answer
dtype: string
- name: image_url
dtype: string
- name: image_type
dtype: string
- name: stratify_key
dtype: string
- name: icam_image
dtype: image
- name: icam_image_lum_100
dtype: image
- name: retinex_image
dtype: image
splits:
- name: train
num_bytes: 14278053867
num_examples: 5296
- name: validation
num_bytes: 1456803341
num_examples: 589
download_size: 15734319933
dataset_size: 15734857208
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
---
提供机构:
pavlov-erg
搜集汇总
数据集介绍
构建方式
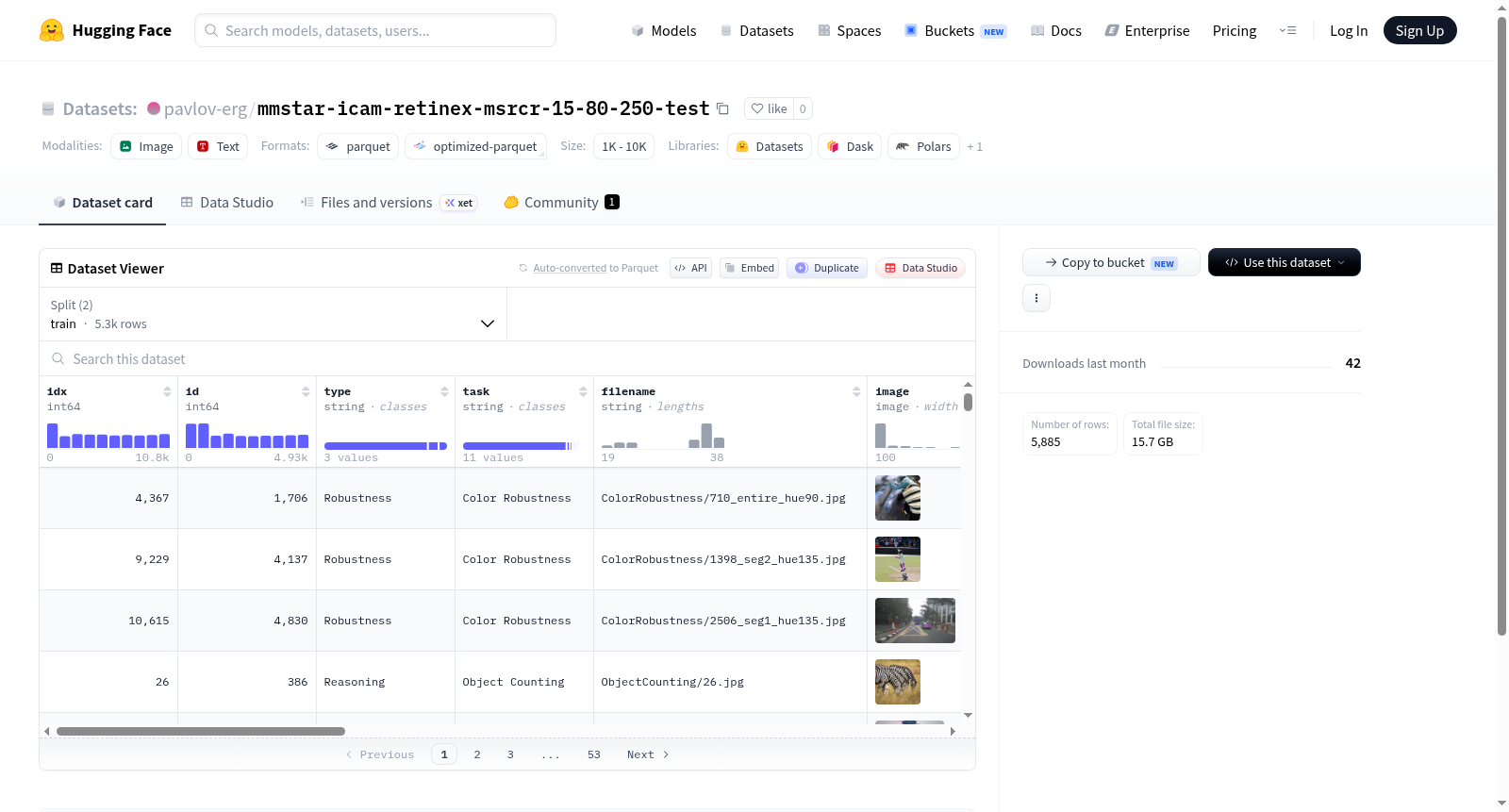
该数据集基于MMStar基准测试集构建,针对多模态大语言模型在复杂视觉推理任务中的表现进行评估。原始图像经过多种图像增强算法的处理,包括ICAM(图像对比度增强与自适应映射)、Retinex(基于视网膜理论的色彩恒常性增强)以及MSRCR(多尺度视网膜皮层恢复)等,生成了增强后的图像版本。这些增强图像与原始图像共同构成数据集的图像模态,每张图像均附带对应的问题(prompt与question)、多选项选择(choices)、正确答案(answer)及任务类型(type)、分层键(stratify_key)等元数据。数据集中每个样本包含14个特征字段,涵盖从原始图像索引到增强图像路径的完整信息链,确保模型在不同光照与成像条件下的推理能力可被系统评估。
使用方法
该数据集加载便捷,通过HuggingFace的datasets库即可直接使用,无需额外预处理。用户可在Python环境中执行`load_dataset('mmstar-icam-retinex-msrcr-15-80-250-test')`,并按需选择训练集(train)或验证集(validation)分割。每个样本的字段可被轻松索引,例如通过sample['image']访问原始图像,通过sample['icam_image']获取增强图像。针对多选问答任务,研究人员可构建模型输入:将sample['prompt']与sample['question']拼接为提示,结合sample['choices']构建候选答案,并使用sample['answer']进行预测结果验证。该结构化的特征设计显著降低了数据解析与模型集成的工作量。
背景与挑战
背景概述
该数据集名为mmstar-icam-retinex-msrcr-15-80-250-test,由相关研究团队创建,旨在探索多模态视觉语言理解任务中图像增强技术的应用。基于MMStar基准测试,该数据集集成了iCAM、Retinex和MSRCR等先进图像增强算法,聚焦于低光照、高动态范围等复杂场景下的视觉问答挑战。研究核心在于评估增强图像对多模态大模型推理能力的影响,为计算机视觉与自然语言处理交叉领域提供标准化测试平台。该数据集的发布推动了视觉语言模型在真实环境噪声下的鲁棒性研究,对提升智能系统在安防、自动驾驶等领域的可靠性具有重要参考价值。
当前挑战
该数据集面临的主要挑战包括领域问题的挑战:多模态模型在低光照、过曝或雾霾等退化场景中,视觉特征提取与语义对齐严重受损,现有模型难以从模糊或失真的图像中准确提取关键信息进行推理。构建过程中的挑战:需要确保增强算法(如iCAM、Retinex)生成的图像与原始图像保持语义一致性,同时避免过度增强引入伪影;高质量标注需跨多光照条件、多场景类型,工作量巨大;数据集的划分需平衡不同增强方式的样本分布,防止模型对特定增强策略产生过拟合。
常用场景
经典使用场景
该数据集是mmstar-icam-retinex-msrcr-15-80-250-test,作为多模态视觉理解与推理领域的典型评测基准,其经典使用场景聚焦于评估和提升大语言模型在复杂视觉任务中的表现。通过整合原始图像、经ICAM算法增强的亮度分量以及Retinex-MSrcr算法处理后的图像,数据集为模型提供了多维度视觉输入,旨在检验模型在低照度、高动态范围等恶劣光照条件下对图像内容的准确理解与逻辑推理能力。研究者常利用该数据集的训练与验证拆分,开展如视觉问答、多选推理等任务,从而推动模型从粗粒度图像识别向精炼视觉语义解析的跨越。
解决学术问题
在学术研究层面,该数据集着力解决当前多模态大模型在非理想成像环境下的鲁棒性不足问题。传统基准大多假设输入图像光照均匀、噪声可控,而忽略了实际场景中因光线不足或强光干扰导致的视觉信息退化。mmstar-icam-retinex-msrcr-15-80-250-test通过引入物理启发的中等光照自适应映射和Retinex-MSrcr增强技术,构建了光照变化与颜色恒常性双重挑战下的测试平台,系统性地揭示了模型对光照不变性特征的依赖局限。其意义在于为低层次图像增强与高层次视觉理解之间的鸿沟搭建了桥梁,促使学术界重新审视视觉特征提取的前置处理对下游推理任务的影响,并催生了针对模型光照鲁棒性提升的优化策略。
实际应用
实际应用场景中,该数据集精准对应安防监控、自动驾驶和移动摄影等高度依赖全天候视觉系统的领域。例如,在夜间监控视频分析中,摄像头采集的图像常伴有阴影、背光或光源反射等退化现象,基于该数据集训练的模型能够更可靠地提取行人、车辆等关键目标,并准确回答如目标数量、行为意图和场景语义等衍生问题。在自动驾驶场景下,模型可借助多模态输入在隧道进出口或雨雾黄昏时刻维持感知稳定性,增强对交通标志、行人姿态和障碍物距离的推理可信度。
数据集最近研究
最新研究方向
该数据集mmstar-icam-retinex-msrcr-15-80-250-test聚焦于多模态视觉语言理解的前沿,通过融合ICAM注意力机制与Retinex-MSRCR图像增强技术,探索在低光照、高动态范围等复杂视觉环境下模型对图像内容的精准解析能力。当前研究热点在于利用此类增强后的图像数据,训练多模态大模型以突破传统视觉感知的瓶颈,尤其在自动驾驶、安防监控及医疗影像等下游任务中,旨在提升模型对细节纹理与色彩信息的鲁棒性。数据集通过引入多种图像预处理变体,为评估和推动视觉语言模型在真实世界噪声与光照不均场景下的泛化表现提供了关键基准,其研究意义在于揭示图像质量与语义理解之间的深层关联,进而引领多模态智能系统向更可靠、更贴近人类视觉感知的方向演进。
以上内容由遇见数据集搜集并总结生成


