qiaojin/PubMedQA
收藏Hugging Face2024-03-06 更新2024-04-19 收录
下载链接:
https://hf-mirror.com/datasets/qiaojin/PubMedQA
下载链接
链接失效反馈官方服务:
资源简介:
---
annotations_creators:
- expert-generated
- machine-generated
language_creators:
- expert-generated
language:
- en
license:
- mit
multilinguality:
- monolingual
size_categories:
- 100K<n<1M
- 10K<n<100K
- 1K<n<10K
source_datasets:
- original
task_categories:
- question-answering
task_ids:
- multiple-choice-qa
paperswithcode_id: pubmedqa
pretty_name: PubMedQA
config_names:
- pqa_artificial
- pqa_labeled
- pqa_unlabeled
dataset_info:
- config_name: pqa_artificial
features:
- name: pubid
dtype: int32
- name: question
dtype: string
- name: context
sequence:
- name: contexts
dtype: string
- name: labels
dtype: string
- name: meshes
dtype: string
- name: long_answer
dtype: string
- name: final_decision
dtype: string
splits:
- name: train
num_bytes: 443501057
num_examples: 211269
download_size: 233411194
dataset_size: 443501057
- config_name: pqa_labeled
features:
- name: pubid
dtype: int32
- name: question
dtype: string
- name: context
sequence:
- name: contexts
dtype: string
- name: labels
dtype: string
- name: meshes
dtype: string
- name: reasoning_required_pred
dtype: string
- name: reasoning_free_pred
dtype: string
- name: long_answer
dtype: string
- name: final_decision
dtype: string
splits:
- name: train
num_bytes: 2088898
num_examples: 1000
download_size: 1075513
dataset_size: 2088898
- config_name: pqa_unlabeled
features:
- name: pubid
dtype: int32
- name: question
dtype: string
- name: context
sequence:
- name: contexts
dtype: string
- name: labels
dtype: string
- name: meshes
dtype: string
- name: long_answer
dtype: string
splits:
- name: train
num_bytes: 125922964
num_examples: 61249
download_size: 66010017
dataset_size: 125922964
configs:
- config_name: pqa_artificial
data_files:
- split: train
path: pqa_artificial/train-*
- config_name: pqa_labeled
data_files:
- split: train
path: pqa_labeled/train-*
- config_name: pqa_unlabeled
data_files:
- split: train
path: pqa_unlabeled/train-*
---
# Dataset Card for [Dataset Name]
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [PubMedQA homepage](https://pubmedqa.github.io/ )
- **Repository:** [PubMedQA repository](https://github.com/pubmedqa/pubmedqa)
- **Paper:** [PubMedQA: A Dataset for Biomedical Research Question Answering](https://arxiv.org/abs/1909.06146)
- **Leaderboard:** [PubMedQA: Leaderboard](https://pubmedqa.github.io/)
### Dataset Summary
The task of PubMedQA is to answer research questions with yes/no/maybe (e.g.: Do preoperative statins reduce atrial fibrillation after coronary artery bypass grafting?) using the corresponding abstracts.
### Supported Tasks and Leaderboards
The official leaderboard is available at: https://pubmedqa.github.io/.
500 questions in the `pqa_labeled` are used as the test set. They can be found at https://github.com/pubmedqa/pubmedqa.
### Languages
English
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
Thanks to [@tuner007](https://github.com/tuner007) for adding this dataset.
annotations_creators:
- 专家生成
- 机器生成
language_creators:
- 专家生成
language:
- 英语
license:
- MIT许可证
multilinguality:
- 单语言
size_categories:
- 10万 < 样本数 < 100万
- 1万 < 样本数 < 10万
- 1千 < 样本数 < 1万
source_datasets:
- 原生数据集
task_categories:
- 问答任务
task_ids:
- 多选问答
paperswithcode_id: pubmedqa
pretty_name: PubMedQA
config_names:
- pqa_artificial
- pqa_labeled
- pqa_unlabeled
dataset_info:
- config_name: pqa_artificial
features:
- name: pubid
dtype: 32位整型
- name: question
dtype: 字符串
- name: context
sequence:
- name: contexts
dtype: 字符串
- name: labels
dtype: 字符串
- name: 医学主题词(MeSH)
dtype: 字符串
- name: long_answer
dtype: 字符串
- name: final_decision
dtype: 字符串
splits:
- name: train
num_bytes: 443501057
num_examples: 211269
download_size: 233411194
dataset_size: 443501057
- config_name: pqa_labeled
features:
- name: pubid
dtype: 32位整型
- name: question
dtype: 字符串
- name: context
sequence:
- name: contexts
dtype: 字符串
- name: labels
dtype: 字符串
- name: 医学主题词(MeSH)
dtype: 字符串
- name: 需推理预测标签
dtype: 字符串
- name: 无推理预测标签
dtype: 字符串
- name: long_answer
dtype: 字符串
- name: final_decision
dtype: 字符串
splits:
- name: train
num_bytes: 2088898
num_examples: 1000
download_size: 1075513
dataset_size: 2088898
- config_name: pqa_unlabeled
features:
- name: pubid
dtype: 32位整型
- name: question
dtype: 字符串
- name: context
sequence:
- name: contexts
dtype: 字符串
- name: labels
dtype: 字符串
- name: 医学主题词(MeSH)
dtype: 字符串
- name: long_answer
dtype: 字符串
splits:
- name: train
num_bytes: 125922964
num_examples: 61249
download_size: 66010017
dataset_size: 125922964
configs:
- config_name: pqa_artificial
data_files:
- split: train
path: pqa_artificial/train-*
- config_name: pqa_labeled
data_files:
- split: train
path: pqa_labeled/train-*
- config_name: pqa_unlabeled
data_files:
- split: train
path: pqa_unlabeled/train-*
# PubMedQA 数据集卡片
## 目录
- [数据集描述](#数据集描述)
- [数据集概述](#数据集概述)
- [支持任务与排行榜](#支持任务与排行榜)
- [语言](#语言)
- [数据集结构](#数据集结构)
- [数据实例](#数据实例)
- [数据字段](#数据字段)
- [数据划分](#数据划分)
- [数据集构建](#数据集构建)
- [数据集遴选依据](#数据集遴选依据)
- [源数据](#源数据)
- [注释](#注释)
- [个人与敏感信息](#个人与敏感信息)
- [数据集使用注意事项](#数据集使用注意事项)
- [数据集的社会影响](#数据集的社会影响)
- [偏差讨论](#偏差讨论)
- [其他已知局限性](#其他已知局限性)
- [附加信息](#附加信息)
- [数据集维护者](#数据集维护者)
- [许可证信息](#许可证信息)
- [引用信息](#引用信息)
- [贡献](#贡献)
## 数据集描述
- **主页:** [PubMedQA 主页](https://pubmedqa.github.io/ )
- **代码仓库:** [PubMedQA 仓库](https://github.com/pubmedqa/pubmedqa)
- **相关论文:** [PubMedQA: 生物医学研究问答数据集](https://arxiv.org/abs/1909.06146)
- **排行榜:** [PubMedQA 排行榜](https://pubmedqa.github.io/)
### 数据集概述
PubMedQA的任务为基于对应学术摘要,以「是/否/不确定」三种形式回答生物医学研究问题(例如:术前他汀类药物是否会降低冠状动脉搭桥术后的心房颤动发生率?)。
### 支持任务与排行榜
官方排行榜可访问:https://pubmedqa.github.io/。`pqa_labeled` 配置中的500条问题被用作测试集,可在https://github.com/pubmedqa/pubmedqa获取。
### 语言
英语
## 数据集结构
### 数据实例
[More Information Needed]
### 数据字段
[More Information Needed]
### 数据划分
[More Information Needed]
## 数据集构建
### 数据集遴选依据
[More Information Needed]
### 源数据
#### 初始数据收集与标准化
[More Information Needed]
#### 源语言生成者是谁?
[More Information Needed]
### 注释
#### 注释流程
[More Information Needed]
#### 注释者是谁?
[More Information Needed]
### 个人与敏感信息
[More Information Needed]
## 数据集使用注意事项
### 数据集的社会影响
[More Information Needed]
### 偏差讨论
[More Information Needed]
### 其他已知局限性
[More Information Needed]
## 附加信息
### 数据集维护者
[More Information Needed]
### 许可证信息
[More Information Needed]
### 引用信息
[More Information Needed]
### 贡献
感谢 [@tuner007](https://github.com/tuner007) 添加本数据集。
提供机构:
qiaojin
原始信息汇总
数据集概述
- 名称: PubMedQA
- 任务类别: 问答(Question-Answering)
- 任务ID: 多选题问答(Multiple-Choice QA)
- 语言: 英语(English)
- 许可证: MIT
- 多语言性: 单语(Monolingual)
- 数据集大小:
- 1K<n<10K
- 10K<n<100K
- 100K<n<1M
数据集结构
数据配置
- pqa_artificial
- 特征:
- pubid: int32
- question: string
- context:
- contexts: string
- labels: string
- meshes: string
- long_answer: string
- final_decision: string
- 数据分割:
- train:
- 字节数: 443501057
- 示例数: 211269
- 下载大小: 233411194
- 数据集大小: 443501057
- train:
- 特征:
- pqa_labeled
- 特征:
- pubid: int32
- question: string
- context:
- contexts: string
- labels: string
- meshes: string
- reasoning_required_pred: string
- reasoning_free_pred: string
- long_answer: string
- final_decision: string
- 数据分割:
- train:
- 字节数: 2088898
- 示例数: 1000
- 下载大小: 1075513
- 数据集大小: 2088898
- train:
- 特征:
- pqa_unlabeled
- 特征:
- pubid: int32
- question: string
- context:
- contexts: string
- labels: string
- meshes: string
- long_answer: string
- 数据分割:
- train:
- 字节数: 125922964
- 示例数: 61249
- 下载大小: 66010017
- 数据集大小: 125922964
- train:
- 特征:
数据集创建
- 注释创建者:
- 专家生成
- 机器生成
- 语言创建者: 专家生成
- 源数据集: 原始(Original)
搜集汇总
数据集介绍
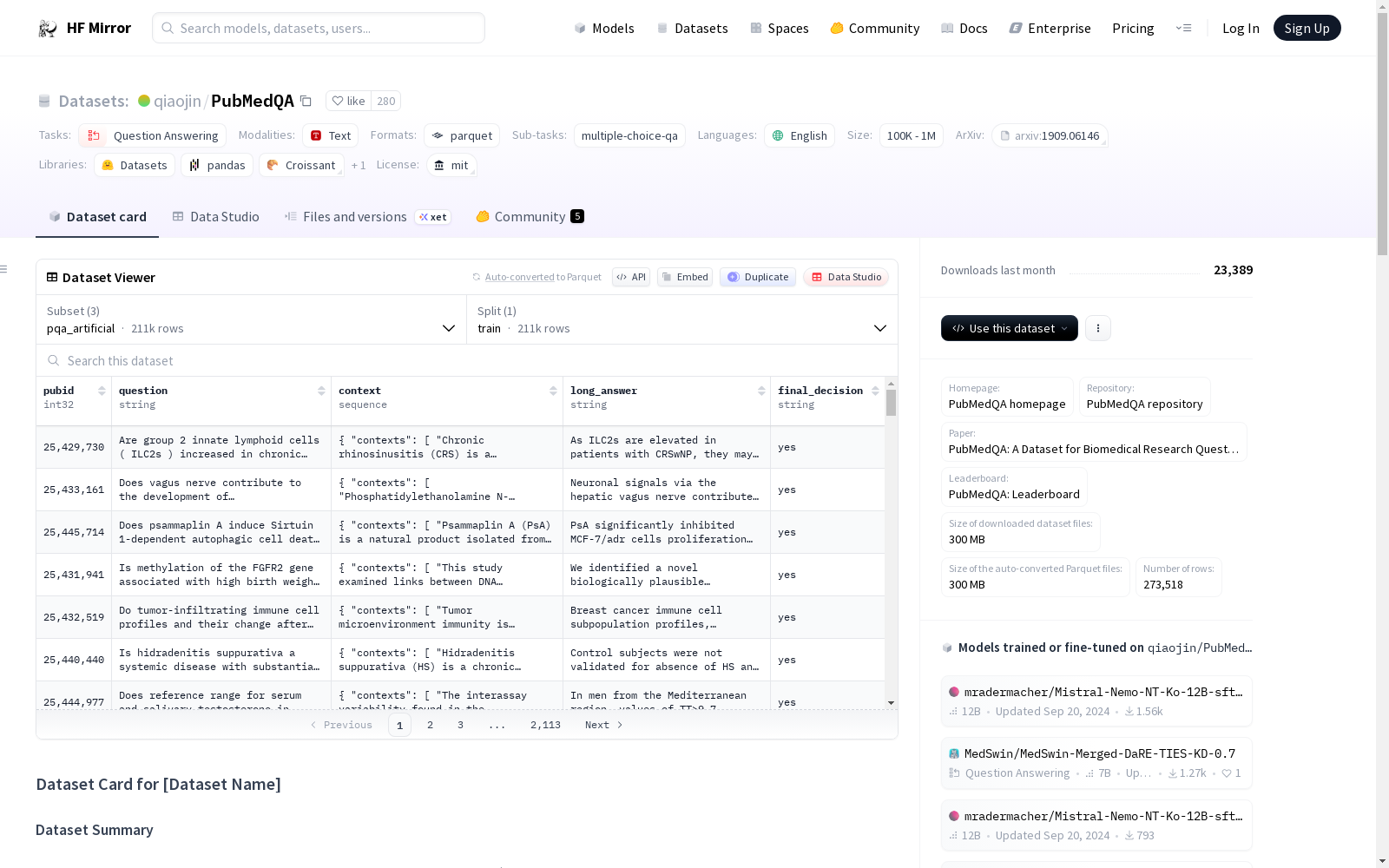
构建方式
在生物医学信息学领域,PubMedQA数据集的构建体现了对研究问题回答任务的深度探索。该数据集通过从PubMed文献中提取研究问题及其对应摘要,构建了三个核心子集:人工标注的pqa_labeled包含1000个实例,由专家生成答案;pqa_artificial则利用自动化方法生成了超过21万个实例,模拟真实问答场景;pqa_unlabeled提供了6万余个未标注实例,为半监督学习提供资源。整个构建过程融合了专家知识与机器生成技术,确保了数据在规模与质量上的平衡。
使用方法
使用PubMedQA时,研究者可通过HuggingFace平台直接加载三个配置子集。对于监督学习任务,推荐使用pqa_labeled进行模型训练与验证,其中500个问题已预留为测试集。pqa_artificial适用于需要大量训练数据的场景,如预训练语言模型;而pqa_unlabeled则可用于自监督学习或数据增强。数据集支持问答任务的直接建模,用户可依据问题、上下文和最终决策字段构建分类模型,同时利用长答案字段进行可解释性分析。
背景与挑战
背景概述
PubMedQA数据集诞生于2019年,由生物医学信息学领域的研究团队精心构建,旨在应对医学文献中复杂问答任务的挑战。该数据集的核心研究问题聚焦于如何让机器理解并回答基于生物医学研究摘要的是非判断型问题,例如评估特定术前药物对术后并发症的影响。通过整合专家标注与机器生成的数据,PubMedQA不仅推动了生物医学自然语言处理技术的发展,也为临床决策支持系统提供了重要的数据基础,显著提升了自动化文献综述与证据提取的可行性。
当前挑战
PubMedQA数据集所针对的领域挑战在于生物医学问答任务的高复杂性,要求模型具备深度的领域知识推理能力,以准确解析专业术语与因果逻辑。在构建过程中,挑战主要体现在数据标注的严谨性上,需要医学专家对大量研究摘要进行精细的是非判断,确保答案的可靠性与一致性。此外,处理未标注数据时,如何有效利用这些信息增强模型泛化能力,同时避免引入噪声,构成了另一重技术难题。
常用场景
经典使用场景
在生物医学信息检索领域,PubMedQA数据集为研究者提供了一个基于PubMed摘要的问答基准。该数据集通过人工标注和机器生成相结合的方式,构建了包含问题、上下文和最终决策(是/否/可能)的结构化样本。其经典使用场景在于评估和训练模型在生物医学文献中的阅读理解能力,特别是针对需要推理的复杂研究问题,例如评估术前他汀类药物是否减少冠状动脉搭桥术后心房颤动的发生。这种设置模拟了真实科研环境中从海量文献中提取关键结论的过程,为自然语言处理技术在专业领域的应用奠定了实证基础。
解决学术问题
PubMedQA数据集主要解决了生物医学自然语言处理中的若干核心学术问题。它针对传统问答系统在专业领域泛化能力不足的局限,提供了大规模、高质量的标注数据,促进了模型对生物医学术语和复杂逻辑关系的理解。该数据集的意义在于填补了生物医学问答评估的空白,使得研究者能够量化模型在真实科研问题上的性能,推动了可解释人工智能在医疗文本分析中的发展。其影响延伸至跨学科研究,为临床决策支持系统的开发提供了关键的数据支撑和技术验证途径。
实际应用
在实际应用层面,PubMedQA数据集被广泛应用于医疗健康领域的智能系统开发。例如,在临床辅助决策工具中,模型可以利用该数据集学习从最新研究摘要中快速提取证据,帮助医生回答特定的治疗或诊断问题。制药公司的研发部门也可借助此类技术扫描文献,加速药物效果或副作用的评估。这些应用不仅提升了信息检索的效率,还通过提供基于实证的答案,增强了医疗决策的科学性和时效性,展现了人工智能在专业化服务中的实用价值。
数据集最近研究
最新研究方向
在生物医学信息抽取领域,PubMedQA数据集凭借其基于PubMed摘要构建的问答结构,已成为评估模型在专业医学推理能力上的重要基准。当前研究聚焦于结合大型语言模型与领域知识增强技术,探索如何利用该数据集的标注与未标注子集,提升模型对复杂医学问题的因果推断和证据整合能力。相关热点事件包括多模态医学问答系统的兴起,推动该数据集在临床决策支持中的应用拓展,其影响体现在促进可解释人工智能在医疗健康领域的发展,为自动化文献综述和精准医疗提供关键技术支持。
以上内容由遇见数据集搜集并总结生成


