abcde
收藏Hugging Face2025-12-19 更新2025-12-20 收录
下载链接:
https://huggingface.co/datasets/jpwahle/abcde
下载链接
链接失效反馈官方服务:
资源简介:
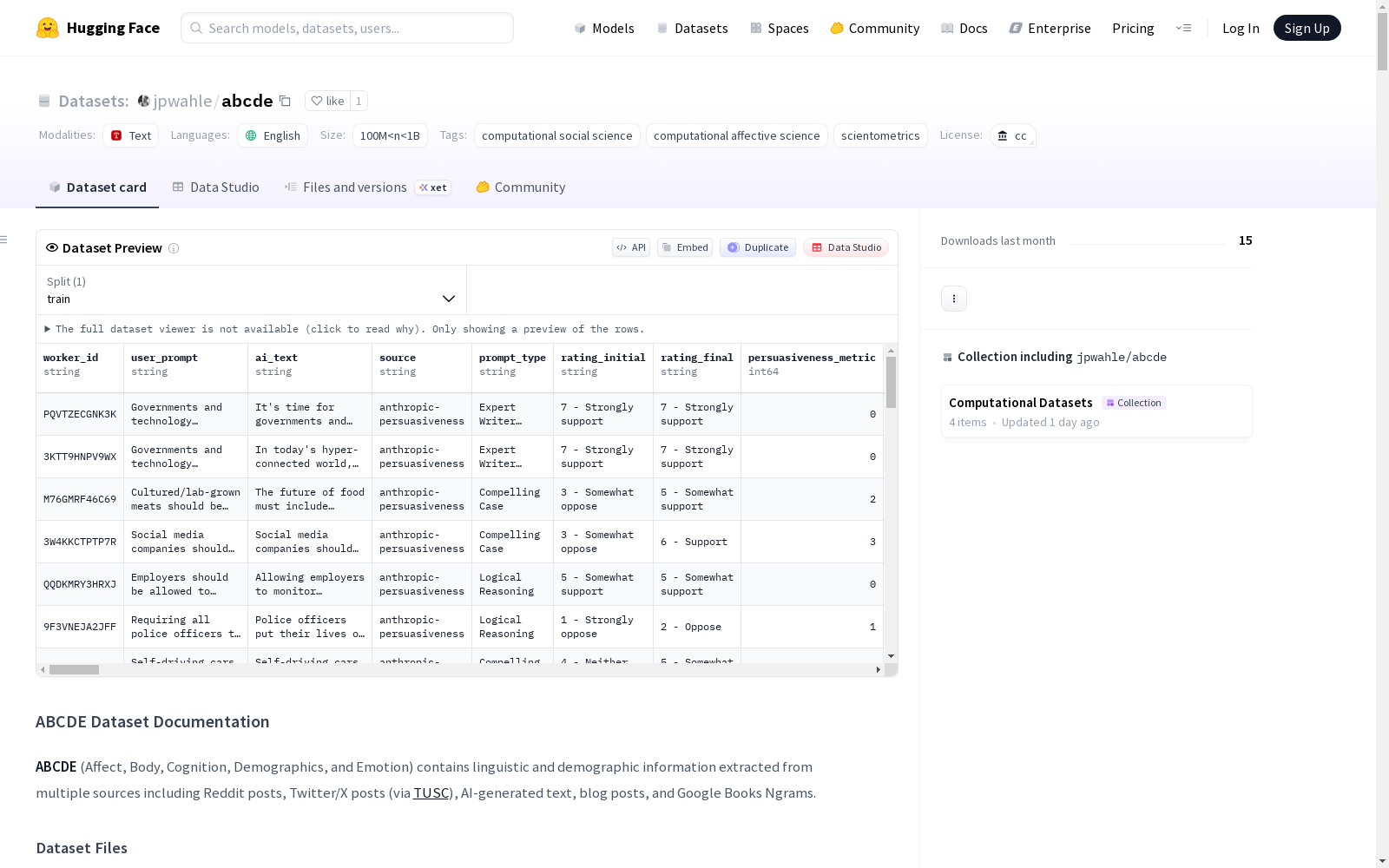
ABCDE(情感、身体、认知、人口统计和情绪)数据集包含从多个来源提取的语言和人口统计信息,包括Reddit帖子、Twitter/X帖子(通过TUSC)、AI生成的文本、博客文章和Google Books Ngrams。数据集文件包括Reddit用户及其帖子、TUSC(Twitter/X)用户及其帖子、AI生成的文本、博客文章和Google Books Ngrams。数据集的构建过程包括自我识别检测和特征提取两个阶段,使用了多种词典和特征来描述文本的语言和情感特征。
创建时间:
2025-12-18
原始信息汇总
ABCDE 数据集概述
数据集基本信息
- 数据集名称:ABCDE (Affect, Body, Cognition, Demographics, and Emotion)
- 许可证:cc
- 主要语言:英语 (en)
- 标签:computational social science, computational affective science, scientometrics
- 规模类别:100M<n<1B
数据集内容与结构
ABCDE 数据集包含从多个来源提取的语言学和人口统计学信息,来源包括 Reddit 帖子、Twitter/X 帖子(通过 TUSC)、AI 生成文本、博客文章和 Google Books Ngrams。
数据集文件
Reddit 数据集 (reddit/)
reddit_users.tsv:包含自我报告年龄的 Reddit 用户及其人口统计学提取信息。reddit_users_posts.tsv:包含所有自我报告用户的帖子及其语言学特征。
TUSC (Twitter/X) 数据集 (tusc/)
city_users.tsv:包含自我报告年龄的 Twitter/X 用户(城市级位置)。city_user_posts.tsv:包含所有自我报告用户的帖子及其语言学特征(城市级)。country_users.tsv:包含自我报告年龄的 Twitter/X 用户(国家级位置)。country_user_posts.tsv:包含所有自我报告用户的帖子及其语言学特征(国家级)。
AI 生成文本数据集 (ai-gen/)
包含来自多个来源的 AI 生成文本及其语言学特征,文件包括:
anthropic_persuasiveness_data_features.tsvapt-paraphrase-dataset-gpt-3_features.tsvgeneral_thoughts_430k_data_features.tsvhh-rlhf_data_features.tsvlmsys_data_features.tsvluar_lwd_data_features.tsvm4_data_features.tsvmage_data_features.tsvpippa_data_features.tsvprism_data_features.tsvraid_data_features.tsvreasoning_shield_data_features.tsvstar1_data_features.tsvtinystories_data_features.tsvwildchat_data_features.tsv
博客文章数据集 (blogs/)
按层级组组织的博客文章,每组包含:
spinner_blog_posts_features.tsv:包含语言学特征的博客文章。- 层级组:2-13(代表不同的作者群体)。
Google Books Ngrams 数据集 (books/)
googlebooks-eng-fiction-top1M-5gram.tsv:来自英语小说的前 100 万个 5-gram 及其语言学特征。
数据来源
- Reddit:来自 Pushshift 的 2010-2022 年 Reddit 帖子 JSON Lines 文件。
- TUSC:来自 TUSC 项目的包含地理位置信息的 Twitter/X 帖子 Parquet 文件。
- Google Books Ngrams (Fiction):来自 Google Books Ngrams 数据集的 5-gram。
- AI 生成文本:包括 RAID、WildChat、LMSYS、PIPPA 等多种数据集。
数据处理流程
1. 自我身份识别检测
- 扫描帖子/推文以通过正则表达式模式检测年龄提及,从而找到自我报告年龄的用户。
- 解析多次年龄提及以确定出生年份。
- 输出包含人口统计学信息的用户文件。
2. 特征提取
- 收集所有自我报告用户的帖子。
- 应用多种词典进行特征提取。
- 根据出生年份计算发帖时的年龄。
- 输出包含所有特征的帖子文件。
3. 过滤标准
- 文本长度:5-1000 个单词。
- 年龄范围:13-100 岁。
- 排除作者:[deleted], AutoModerator, Bot(仅限 Reddit)。
- 有效的自我身份识别:必须匹配其中一个正则表达式模式。
- 移除标记为成人内容的帖子(仅限 Reddit)。
- 移除有标题但无正文的帖子(仅限 Reddit)。
- 移除推广/广告帖子(仅限 Reddit)。
年龄提取
使用的正则表达式模式
系统使用 6 种正则表达式模式来检测年龄自我报告:
- 直接年龄陈述。
- 带有上下文边界的年龄。
- 出生年份(4 位数)。
- 出生年份(带撇号的 2 位数)。
- 出生日期(完整格式)。
- 出生日期(数字格式)。
年龄解析算法
- 从文本中提取所有年龄/出生年份提及。
- 将年龄转换为出生年份(发帖年份 - 年龄)。
- 在转换过程中过滤掉 13 岁以下的年龄。
- 对相似的出生年份(2 年内)进行聚类。
- 为出生年份(权重 1.0)和年龄(权重 0.8)分配权重。
- 选择得分最高的聚类(权重总和 + 计数 × 0.1)。
- 计算加权平均值作为最终出生年份。
- 计算解析后的年龄,如果不在 13-100 之间则过滤。
使用的词典
NRC 词典
- NRC VAD 词典:包含效价、唤醒度和支配度分数(0-1)。
- NRC 情感词典:将单词映射到 8 种情感和 2 种情绪。
- NRC WorryWords 词典:包含焦虑分数(-3 到 +3)。
- NRC MoralTrust 词典:包含道德可信度分数。
- NRC SocialWarmth 词典:包含社会温暖度分数。
- NRC CombinedWarmth 词典:包含综合温暖度分数。
其他词典
- ENG 时态词典:将单词映射到其语法形式。
- 身体部位单词:两个来源的并集。
- 认知/思维单词词典:涵盖不同类型认知过程的 12 个类别。
特征描述
人口统计学特征 (DMG 前缀)
包括作者 ID、解析后的出生年份、原始提取的年龄/年份/性别/城市/国家/宗教/职业、发帖时年龄等。
帖子元数据
- Reddit 特定:帖子 ID、创建时间、子版块、标题、正文、分数、评论数、永久链接等。
- TUSC 特定:推文内容、创建时间、年份、月份、城市、国家、地点等。
- AI 生成文本元数据:数据源、类型、对话 ID、用户提示、模型、生成文本等。
- 博客文章元数据:文件路径、标题、链接、发布日期、类别等。
- Google Books Ngram 元数据:n-gram 文本、年份、匹配次数、书籍数量。
身体部位提及 (BPM 前缀)
布尔标志,用于指示在“my”、“your”、“her”、“his”、“their”之后是否提及身体部位。
代词特征 (PRN 前缀)
指示代词存在的二进制标志,涵盖第一人称单数/复数、第二人称、第三人称阴性/阳性/复数-中性。
时间/时态特征 (TIME 前缀)
基于 UniMorph 英语词典的动词时态分析特征,包括过去时、现在时、将来情态动词的布尔标志和计数。
认知/思维单词特征 (COG 前缀)
指示 12 个认知类别单词是否存在的二进制标志,类别包括分析评估、创造力构思、一般认知、学习理解、决策判断、问题解决、高阶思维、困惑或不确定思维、记忆回忆、感知观察、预测预报、解释阐述。
NRC VAD 特征
来自 NRC VAD 词典的效价-唤醒度-支配度分数,包括平均值、高低词存在布尔标志及计数。
NRC 情感特征
来自 NRC 情感词典的离散情感检测,涵盖八种基本情感(愤怒、期待、厌恶、恐惧、快乐、悲伤、惊讶、信任)和两种情绪(积极、消极)的布尔标志及计数。
NRC WorryWords 特征
来自 NRC WorryWords 词典的焦虑和冷静度检测,包括平均值、高低词存在布尔标志及计数。
NRC 道德/社会/温暖度特征
- 道德信任特征:道德可信度分数相关特征。
- 社会温暖度特征:人际温暖度分数相关特征。
- 综合温暖度特征:整体温暖度分数相关特征。
基本文本统计
WordCount:文本中的总词数。
搜集汇总
数据集介绍
构建方式
在计算社会科学与情感计算领域,构建高质量的多模态数据集是推动相关研究的关键。ABCDE数据集通过一个严谨的两阶段处理流程整合了来自Reddit、Twitter/X、AI生成文本、博客文章及Google Books Ngrams的多样化语料。第一阶段,系统运用六种精心设计的正则表达式模式,从文本中自动检测用户自我报告的年龄信息,并通过聚类与加权算法解析出可靠的出生年份。第二阶段,针对筛选出的用户及其所有发帖,数据集应用了包括NRC情感词汇库、身体部位词表、认知动词分类以及时态分析词典在内的多种语言学资源,系统性地提取了涵盖情感、认知、身体指涉及人口统计学特征的丰富维度。整个流程还设定了严格的过滤标准,如文本长度、年龄范围及内容质量,确保了数据构建的科学性与可靠性。
特点
ABCDE数据集的显著特点在于其宏大的规模与精细的多维度特征体系。数据集囊括了超过一亿条数据条目,覆盖了社交媒体、生成式人工智能、博客与历史书籍文本等多种来源,为研究语言模式在不同语境下的演变提供了坚实基础。其核心特征体系极具深度,不仅包含了基础的人口统计学信息与文本元数据,更通过一系列专业词典构建了复杂的情感计算指标,如效价-唤醒-优势度评分、八种基本情绪检测以及焦虑-平静度分析。同时,数据集还编码了身体部位指涉、代词使用模式、动词时态分布以及十二类认知过程词汇的出现情况,这些特征共同刻画了语言在情感、认知、社会互动及自我表达等多个层面的丰富信息,为跨学科的定量分析提供了前所未有的粒度。
使用方法
对于致力于计算社会科学、情感计算或科学计量学的研究者而言,ABCDE数据集提供了一个功能强大的分析平台。数据集以分门别类的TSV文件形式组织,研究者可根据具体研究问题便捷地选取Reddit用户发帖、地理标注的推文、特定AI模型生成文本或历史语料库等子集进行加载与分析。利用数据集中预计算的特征列,研究者可以直接进行大规模的关联分析、群体比较或时间序列建模,例如探究情感表达与年龄的关系,或比较人类与AI文本在认知词汇使用上的差异。数据集详尽的文档描述了每个特征的计算方法,确保了分析的可复现性。高级用户还可以基于原始文本和提供的词汇资源,进一步扩展或定制特征提取流程,以满足特定研究需求。
背景与挑战
背景概述
ABCDE数据集由计算社会科学与情感计算领域的研究者构建,旨在整合多源语言数据以探究情感、认知、人口统计学等多维特征的关联。该数据集汇集了来自Reddit、Twitter/X、AI生成文本、博客及谷歌图书语料库的海量信息,通过精细的特征提取流程,为理解人类语言表达中的心理与社会属性提供了大规模、多模态的基准资源。其核心研究问题聚焦于语言特征如何反映个体的情感状态、认知模式及社会人口背景,对推动计算心理语言学、社会计算及情感人工智能等交叉领域的发展具有显著影响力。
当前挑战
ABCDE数据集致力于解决从非结构化网络文本中自动推断用户心理与社会属性的挑战,这涉及对语言中隐含的情感、认知及人口统计信息的精准识别与量化。在构建过程中,研究团队面临多重挑战:首先,用户年龄等人口信息的自我报告依赖正则表达式匹配,存在误报与漏报的风险,需设计复杂的解析与验证算法以确保数据可靠性;其次,多源数据的异构性(如社交媒体帖子、AI生成内容、历史图书语料)要求统一的特征提取框架与标准化处理流程;此外,大规模文本的情感与认知特征标注需依赖外部词典(如NRC系列词典),其覆盖度与领域适应性可能限制特征的泛化能力。
常用场景
经典使用场景
在计算社会科学与计算情感科学领域,ABCDE数据集为探究语言、情感与人口统计特征的动态关联提供了关键实证基础。其经典使用场景在于通过整合社交媒体文本、AI生成内容及历史语料,系统分析不同年龄段、地域和文化背景下个体的情感表达模式、认知词汇使用及自我呈现策略。研究者可借助其丰富的语言学特征与人口统计标签,构建跨平台的纵向分析模型,揭示数字时代人类心理与行为的演变轨迹。
实际应用
ABCDE数据集的实际应用广泛涵盖心理健康监测、个性化内容推荐、人机交互优化及社会趋势预测等领域。例如,通过分析不同年龄段用户在社交媒体中的情感表达与认知特征,可辅助开发早期心理风险预警系统;其AI生成文本部分则为检测合成内容、评估语言模型的社会偏见提供了基准数据。此外,该资源还能助力教育科技、数字营销及公共政策制定,实现基于实证的用户洞察。
衍生相关工作
基于ABCDE数据集已衍生出多项经典研究工作,包括跨文化情感表达比较、生命周期语言发展建模、以及AI文本风格检测算法的开发。例如,学者利用其年龄标注数据探究了青年与老年群体在情绪词汇使用上的差异;另有研究结合其认知特征与情感标签,构建了心理健康状态的预测模型。这些工作显著推进了计算社会科学、自然语言处理及数字人文领域的交叉创新。
以上内容由遇见数据集搜集并总结生成


