sherum/mystery-chapters-canon
收藏Hugging Face2026-04-24 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/sherum/mystery-chapters-canon
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
features:
- name: text
dtype: string
- name: summary
dtype: string
- name: title
dtype: string
- name: keywords
dtype: string
- name: themes
dtype: string
- name: setting
dtype: string
- name: tone
dtype: string
- name: characters
dtype: string
- name: roles
list:
- name: Dialect
dtype: string
- name: actions
list:
- name: Explore
dtype: string
splits:
- name: train
num_bytes: 1400221
num_examples: 146
download_size: 886128
dataset_size: 1400221
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
提供机构:
sherum
搜集汇总
数据集介绍
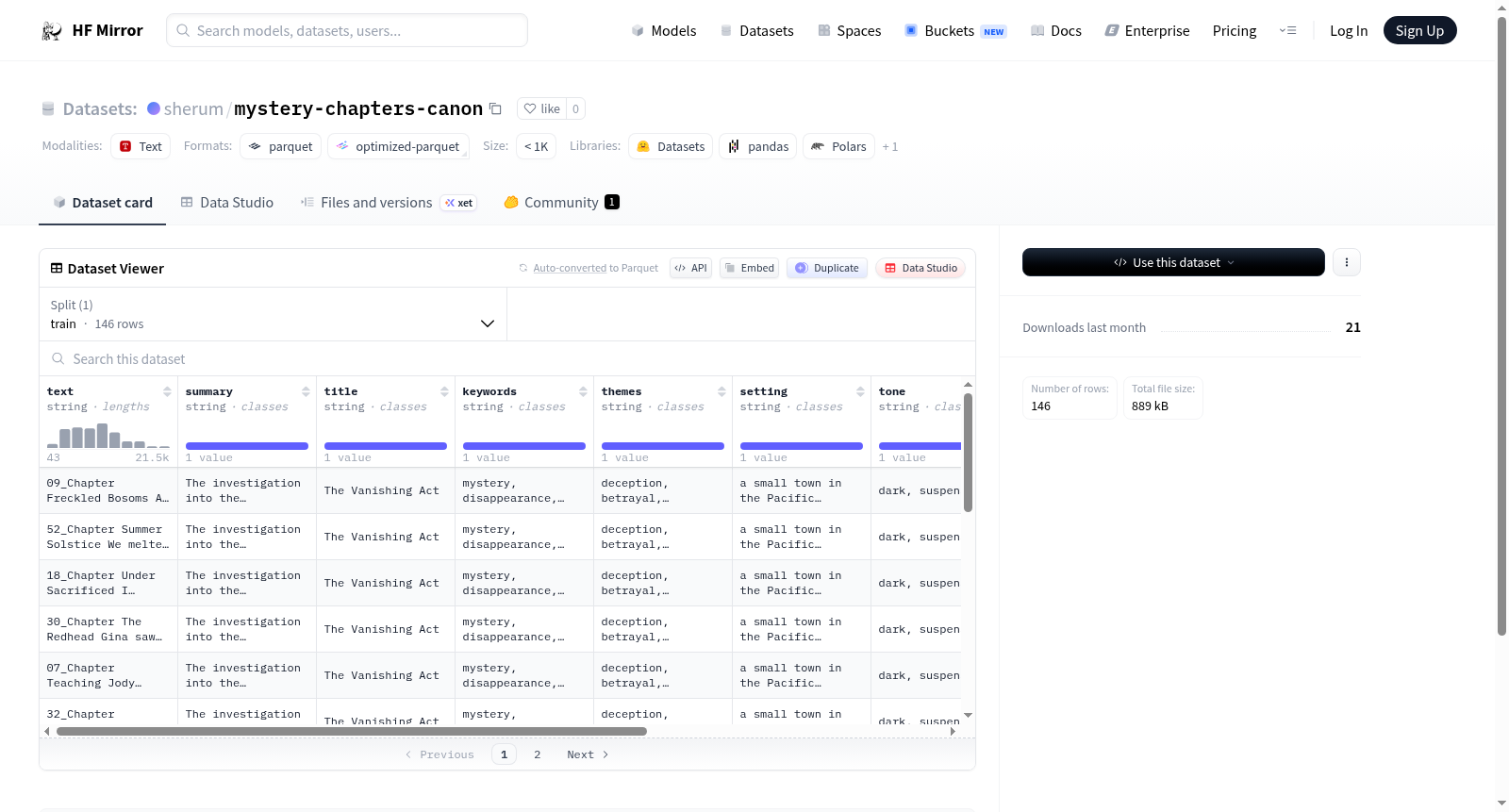
构建方式
该数据集名为mystery-chapters-canon,收录了146个训练样本,以纯文本形式存储。每条样本包含九个字段:text(正文)、summary(摘要)、title(标题)、keywords(关键词)、themes(主题)、setting(背景设定)、tone(语调)、characters(角色)以及roles(方言)和actions(探索行为)这两个嵌套列表。通过将文本与结构化元数据结合,构建了一个服务于文学创作与分析的优质语料库。
特点
数据集的核心特点在于其多维度的注释体系。除基础文本外,每条数据均配有标题、关键词、主题、背景设定和语调等标签,并特别标注了角色语言风格与动作类型。这种精细化的标注方式便于研究者深入分析叙事结构、角色互动与情感氛围,尤其适合悬疑或推理类章节的生成与评估任务。
使用方法
使用方法上,数据集以HuggingFace Datasets库加载,默认配置为train分割。用户可通过加载data/train-*路径下的parquet文件,直接获取字典形式的样本。每条记录均包含完整字段,适用于文本生成模型的训练、风格迁移实验或多标签分类任务,也可用于叙事元素的统计分析。
背景与挑战
背景概述
在自然语言处理与文学分析交叉领域,结构化叙事数据的稀缺长期制约着文本理解与生成模型的进步。mystery-chapters-canon数据集由匿名研究团队于近期创建,旨在为悬疑类文学作品的章节级结构提供精细化标注资源。该数据集包含146个训练样本,每个样本涵盖文本、摘要、标题、关键词、主题、场景设定、语气、角色及对白、动作等九类元数据,为探索悬疑叙事中伏笔、悬念与解谜逻辑的自动化建模奠定了数据基础。其多维度标注体系不仅服务于风格迁移与情节生成任务,更推动了叙事学理论在计算框架下的量化实证研究。
当前挑战
当前该数据集面临的主要挑战涵盖两个层面。在领域问题层面,悬疑叙事特有的非线性结构与环境交织性使得模型难以捕捉伏笔与线索间的长程依赖,同时角色行动与心理状态的隐含关联增加了情节推演的复杂度。在构建层面,数据规模仅146例,远不足以支撑深度模型的鲁棒训练,且标注信息中角色对白与探索动作的细粒度划分可能引入主观歧义,影响跨研究者的一致性。此外,场景设定与紧张氛围等抽象元数据的标准化定义缺失,进一步限制了数据集在跨语种与跨文化场景下的迁移应用效能。
常用场景
经典使用场景
《神秘篇章·经典》(mystery-chapters-canon)数据集专为侦探推理与悬疑文学研究而构建,其核心价值在于为自然语言处理领域中的叙事理解与情节生成任务提供精细标注的文学语料。该数据集包含146个训练样本,每条数据均以篇章文本、摘要、标题、关键词、主题、背景设定、语气、角色及方言角色等多种元信息为特征,尤其适合用于训练和评估模型对悬疑叙事中伏笔、反转与真相揭露等复杂结构的解析能力。研究者可借助这一资源,深入探索长文本中隐式线索的识别、多角色对话中的心理刻画建模,以及基于主题与语气约束的悬念情节自动生成,从而推动计算叙事学在犯罪与推理文学子领域的发展。
实际应用
在实际应用层面,mystery-chapters-canon为互动小说引擎、剧本辅助写作工具及虚拟现实推理游戏的情节设计提供了核心训练数据。例如,游戏开发公司可基于该数据集微调大型语言模型,使其自动生成符合特定主题与背景设定的悬疑章节,并确保故事在角色方言和语气上保持连贯性。电子书平台亦能利用其摘要与关键词标注,构建面向推理爱好者的个性化推荐系统,精准匹配用户对‘密室谋杀’或‘哥特式氛围’等子类型偏好的作品。此外,智能教育辅导软件可借助数据中的角色与动作标签,设计沉浸式侦探推理课程,指导学生通过分析文本中的线索与情感走向来锻炼逻辑思维能力。
衍生相关工作
围绕mystery-chapters-canon数据集,已催生出多个具有影响力的衍生研究方向。经典工作之一是基于其多粒度标注微调的悬疑叙事生成模型,通过将主题与语气的联合控制融入transformer架构,实现了风格一致且转折巧妙的段落续写。另一代表性工作则聚焦于多角色方言识别与普适化迁移,研究人员利用该数据中方言角色字段训练出能够模拟不同地区侦探角色语言特征的对话代理。此外,数据集中的关键词与摘要信息被用于开发情节注意力机制,有效提升了长篇小说自动摘要对隐晦谜题线索的提取能力。这些衍生贡献不仅验证了数据集在自然语言生成、对话系统及文本摘要等任务上的通用性,也为构建更复杂的跨章节长线推理叙事系统奠定了实证基础。
以上内容由遇见数据集搜集并总结生成


