lol-splash
收藏Hugging Face2026-02-15 更新2026-02-16 收录
下载链接:
https://huggingface.co/datasets/rconhf/lol-splash
下载链接
链接失效反馈官方服务:
资源简介:
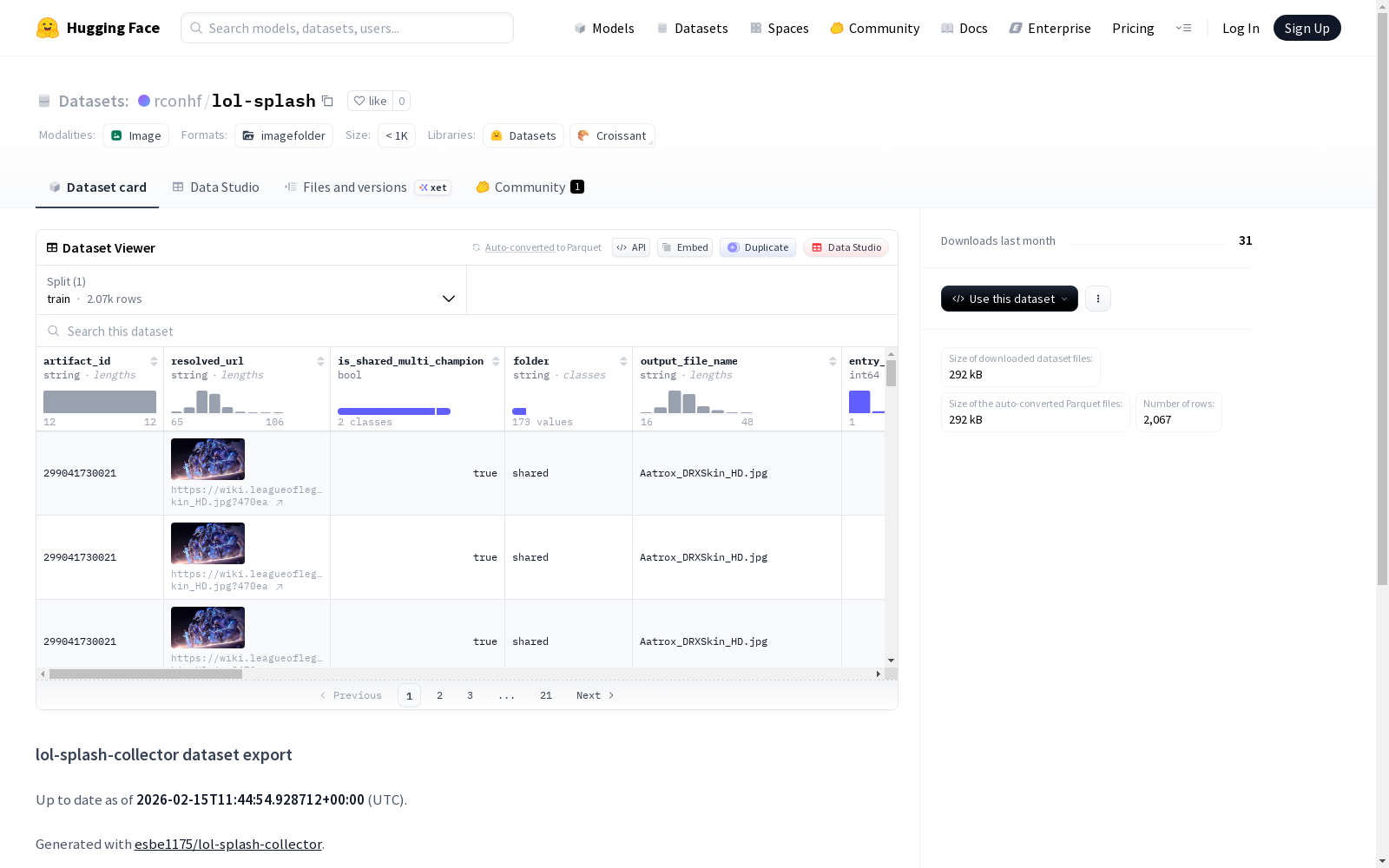
lol-splash-collector数据集导出,截至2026-02-15 UTC时间。该数据集通过esbe1175/lol-splash-collector工具生成,使用了特定版本的Wiki模块数据(Module:SkinData/data和Module:Filename)。数据集包含以英雄皮肤为单位的记录,提供三种格式:JSONL(每行一条记录)、CSV(表格格式)和Parquet(需pyarrow支持)。数据具体字段和用途未明确说明,但推测与英雄联盟游戏皮肤相关。
创建时间:
2026-02-14
原始信息汇总
数据集概述
数据集基本信息
- 数据集名称: lol-splash-collector dataset export
- 最后更新日期: 2026-02-15T11:44:54.928712+00:00 (UTC)
- 数据生成工具: 使用 esbe1175/lol-splash-collector 生成
数据源信息
- 使用的维基模块及版本:
Module:SkinData/data: 版本3990912Module:Filename: 版本3967844
数据文件格式与内容
- 数据文件配置:
- 配置名称:
default - 训练集 (
train) 文件路径:hf/records.parquet
- 配置名称:
- 提供的文件格式:
hf/records.jsonl: 每个英雄-皮肤行的行分隔记录hf/records.csv: 用于电子表格的表格导出hf/records.parquet: Parquet 格式导出(在 pyarrow 可用时写入)
搜集汇总
数据集介绍
构建方式
在电子游戏文化研究领域,数据集的构建往往依赖于对官方资源的系统性采集与整理。lol-splash数据集通过专门的收集工具,从《英雄联盟》维基模块中提取了皮肤数据的特定版本,确保了数据来源的权威性与版本一致性。其构建过程自动化地处理了原始的结构化信息,并生成了多种便于不同技术栈使用的格式,包括JSON行、CSV以及Parquet文件,从而为后续的分析与应用奠定了结构化的数据基础。
特点
该数据集的核心特征在于其高度的时效性与格式的多样性。数据更新至一个明确的未来时间戳,反映了对游戏内容持续迭代的追踪能力。数据集不仅提供了每条英雄皮肤记录的明细,还以多种通用数据格式呈现,兼顾了开发者在数据分析、机器学习以及传统表格处理中的不同需求。这种设计使得数据集能够灵活适应从学术研究到实际工程项目的多种场景。
使用方法
对于研究者与开发者而言,该数据集的使用方法直接而高效。用户可以通过加载Parquet或JSON行等格式的文件,快速访问结构化的英雄皮肤信息。这些数据可直接用于构建游戏内容分析模型、进行视觉文化研究,或作为下游应用(如社区网站、粉丝工具)的数据后端。数据集提供的多种导出格式允许用户根据自身的技术栈和性能要求,选择最合适的接口进行集成与处理。
背景与挑战
背景概述
在电子竞技与数字娱乐领域,英雄联盟(League of Legends)作为全球最具影响力的多人在线战术竞技游戏之一,其角色皮肤设计不仅承载着艺术表达,也反映了玩家社区的文化认同与审美趋势。lol-splash数据集由研究人员esbe1175于2026年创建,通过自动化工具lol-splash-collector从游戏官方维基模块中系统提取英雄皮肤相关数据。该数据集的核心研究问题聚焦于大规模游戏视觉资源的标准化整理与可访问性,旨在为计算机视觉、游戏设计分析以及数字媒体研究提供结构化数据支持,从而推动跨学科领域对虚拟形象美学与用户交互模式的深入探索。
当前挑战
该数据集致力于解决游戏视觉资源管理中的信息整合挑战,即如何从分散且动态更新的维基页面中准确提取并标准化英雄皮肤元数据,以支持图像识别、风格迁移或内容推荐等下游任务。在构建过程中,主要挑战源于维基模块结构的频繁变更与版本差异,这要求数据收集工具具备高度的鲁棒性与适应性,以确保数据的一致性与时效性。此外,跨格式数据导出(如JSONL、CSV与Parquet)的兼容性维护,以及大规模非结构化图像关联信息的结构化转换,均对数据集的完整性与可用性提出了持续的技术要求。
常用场景
经典使用场景
在数字娱乐与多媒体分析领域,lol-splash数据集以其详尽的英雄联盟角色皮肤图像信息,为计算机视觉与游戏内容研究提供了关键资源。该数据集最经典的使用场景在于支持图像生成与风格迁移模型的训练,研究人员可利用其丰富的皮肤艺术图,探索从文本描述到高质量视觉内容的自动生成技术,推动生成式人工智能在创意产业中的应用。
实际应用
在实际应用层面,lol-splash数据集被广泛整合进游戏开发与社区工具中,助力皮肤推荐系统、个性化内容展示及粉丝创作平台的构建。游戏公司可借助该数据集优化美术资源管理流程,而第三方开发者则能基于其开发视觉搜索、皮肤对比或历史档案应用,丰富玩家体验并增强社区互动,体现了数据驱动设计在数字娱乐生态中的实用价值。
衍生相关工作
围绕lol-splash数据集,已衍生出多项经典研究工作,包括基于深度学习的皮肤风格分类模型、跨游戏角色的视觉相似性分析框架,以及结合自然语言处理的皮肤描述生成系统。这些工作不仅拓展了游戏数据挖掘的边界,还为通用图像理解任务提供了新的基准,激励着学术界与工业界在多媒体智能处理领域持续探索。
以上内容由遇见数据集搜集并总结生成


