wikipos
收藏Hugging Face2025-09-12 更新2025-09-13 收录
下载链接:
https://huggingface.co/datasets/whatphiliptrains/wikipos
下载链接
链接失效反馈官方服务:
资源简介:
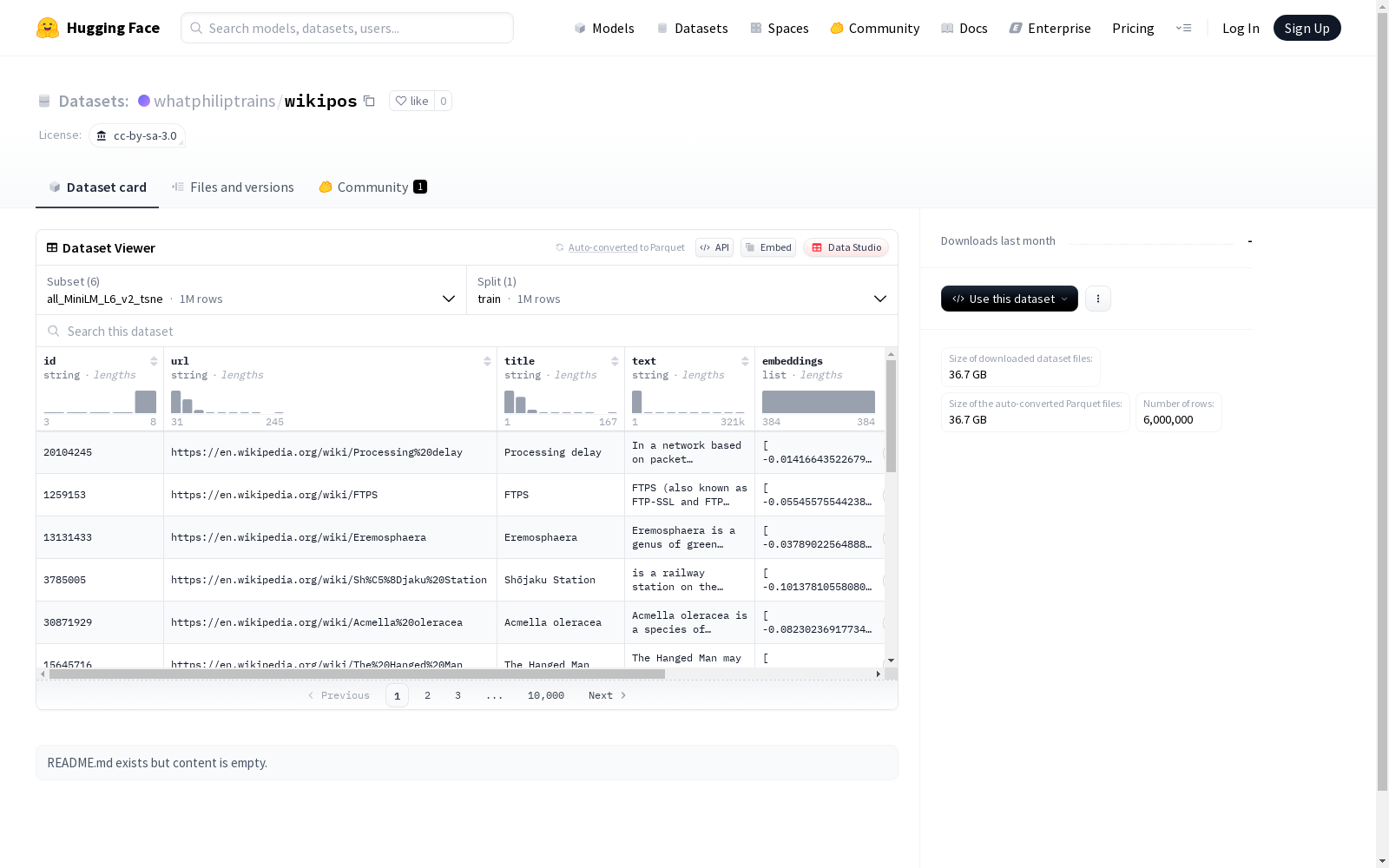
wikipos数据集是一个将维基百科文章映射到二维坐标中的数据集,可以用于可视化、嵌入分析以及文章关系的空间表示。每个条目包括文章标题、第一维坐标x和第二维坐标y。这些坐标用于表示文章之间的语义或结构关系。
创建时间:
2025-09-11
原始信息汇总
数据集概述
基本信息
- 许可证: CC BY-SA 3.0
- 数据集地址: https://huggingface.co/datasets/whatphiliptrains/wikipos
配置信息
all_MiniLM_L6_v2_tsne
- 特征:
- id (string)
- url (string)
- title (string)
- text (string)
- embeddings (sequence of float64)
- x (float64)
- y (float64)
- 数据分割:
- train: 1,000,000 个样本,6,246,699,478 字节
- 下载大小: 4,538,005,665 字节
- 数据集大小: 6,246,699,478 字节
all_MiniLM_L6_v2_umap
- 特征:
- id (string)
- url (string)
- title (string)
- text (string)
- embeddings (sequence of float64)
- x (float64)
- y (float64)
- 数据分割:
- train: 1,000,000 个样本,6,246,699,478 字节
- 下载大小: 4,534,235,798 字节
- 数据集大小: 6,246,699,478 字节
all_mpnet_base_v2_tsne
- 特征:
- id (string)
- url (string)
- title (string)
- text (string)
- embeddings (sequence of float64)
- x (float64)
- y (float64)
- 数据分割:
- train: 1,000,000 个样本,9,318,699,478 字节
- 下载大小: 6,907,407,845 字节
- 数据集大小: 9,318,699,478 字节
all_mpnet_base_v2_umap
- 特征:
- id (string)
- url (string)
- title (string)
- text (string)
- embeddings (sequence of float64)
- x (float64)
- y (float64)
- 数据分割:
- train: 1,000,000 个样本,9,318,699,478 字节
- 下载大小: 6,903,485,890 字节
- 数据集大小: 9,318,699,478 字节
nomic_embed_text_v1_5_tsne
- 特征:
- id (string)
- url (string)
- title (string)
- text (string)
- embeddings (sequence of float64)
- x (float64)
- y (float64)
- 数据分割:
- train: 1,000,000 个样本,9,318,699,478 字节
- 下载大小: 6,893,020,526 字节
- 数据集大小: 9,318,699,478 字节
nomic_embed_text_v1_5_umap
- 特征:
- id (string)
- url (string)
- title (string)
- text (string)
- embeddings (sequence of float64)
- x (float64)
- y (float64)
- 数据分割:
- train: 1,000,000 个样本,9,318,699,478 字节
- 下载大小: 6,889,209,376 字节
- 数据集大小: 9,318,699,478 字节
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,高质量文本表示数据集的构建对语义理解研究至关重要。WikiPOS数据集源于维基百科条目的系统化采集,通过提取每个条目的唯一标识符、原始URL、标题及正文文本,形成结构化语料库。随后采用多种前沿嵌入模型(包括all-MiniLM-L6-v2、all-mpnet-base-v2及nomic-embed-text-v1.5)生成高维向量表示,并分别应用t-SNE和UMAP降维算法生成二维坐标,最终构建成包含百万样本的多配置数据集。
特点
该数据集显著特征体现在多维度表征体系的融合架构中。每个样本不仅保留原始文本的完整元数据(ID、URL、标题及正文),还包含由不同嵌入模型生成的语义向量序列。特别值得注意的是,数据集提供经过两种主流降维算法处理的二维投影坐标,为研究者提供了从原始文本到低维语义空间的完整映射路径。这种多模型并行嵌入的架构,使得数据集能支持跨模型表示学习对比研究。
使用方法
研究者可通过HuggingFace数据集库直接加载特定配置,如选择all_mpnet_base_v2_tsne配置获取对应嵌入表示。每个配置包含训练分割,其中embeddings字段提供高维语义向量,x和y字段对应降维后的二维坐标。使用时可基于原始文本进行语义相似度计算,或利用二维坐标实现可视化分析。不同配置间的对比使用能够揭示各类嵌入模型在语义表示特性上的差异,为模型评估提供基准。
背景与挑战
背景概述
wikipos数据集作为大规模文本嵌入可视化研究的重要载体,由自然语言处理领域的研究团队基于维基百科语料构建而成。该数据集通过集成多种前沿嵌入模型(包括MiniLM、MPNet和Nomic Embed等),为高维文本表征的可视化分析提供了标准化基准。其核心价值在于解决了文本嵌入空间直观解释的难题,为语义相似性计算、知识图谱构建以及跨模态学习提供了关键数据支撑,显著推动了可解释人工智能在文本分析领域的发展进程。
当前挑战
该数据集面临的领域挑战主要在于高维嵌入向量的降维可视化过程中如何保持原始语义结构的完整性,不同嵌入模型产生的向量空间存在异构性对齐难题。构建过程中的技术挑战包括:百万级样本的嵌入计算与存储优化,需要平衡计算效率与表征质量;多模型嵌入结果的标准化处理与一致性验证;以及降维算法(t-SNE/UMAP)参数对可视化效果敏感度的控制问题,这些因素共同增加了数据集构建的技术复杂度。
常用场景
经典使用场景
在自然语言处理领域,wikipos数据集通过预计算的文本嵌入向量及其降维坐标,为研究者提供了大规模文档语义可视化分析的经典范式。该数据集常用于评估不同嵌入模型在语义空间构建中的表现,研究者通过对比t-SNE和UMAP等降维算法生成的二维分布,探索高维文本表征的可解释性与聚类特性,为语义相似性研究提供直观的验证基础。
衍生相关工作
基于wikipos衍生的研究主要集中于多模态语义对齐和动态嵌入更新技术。部分学者利用其基准数据开发了跨语言嵌入映射方法,另一些研究则结合时间序列分析构建了语义演化追踪模型。这些工作显著丰富了文本嵌入在历史文献数字化和跨领域知识迁移中的应用场景,推动了语义计算技术的实用化进程。
数据集最近研究
最新研究方向
在自然语言处理与知识图谱交叉领域,wikipos数据集凭借其百万级维基百科文本嵌入及降维坐标数据,正推动语义表示学习的前沿探索。研究者聚焦于多模态嵌入空间的几何特性分析,利用t-SNE和UMAP等流形学习技术揭示高维语义的拓扑结构。当前热点集中于对比学习框架下的嵌入对齐优化,以及跨语言语义空间的迁移学习应用,这些研究显著提升了知识检索系统和语义匹配模型的性能,为构建更精准的认知智能系统提供理论基础。
以上内容由遇见数据集搜集并总结生成


