有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
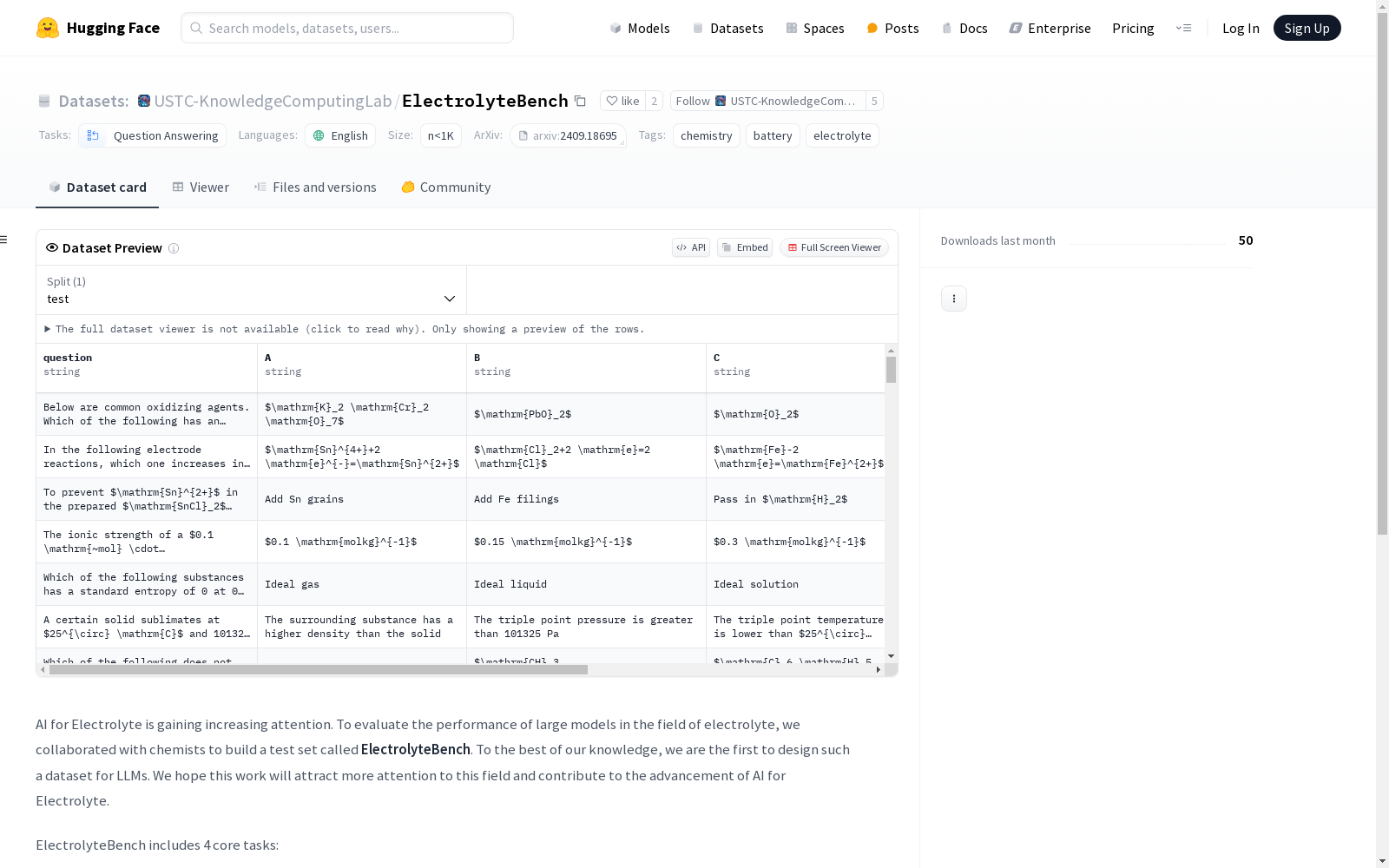
@article{dai2024kale, title={KALE-LM: Unleash The Power Of AI For Science Via Knowledge And Logic Enhanced Large Model}, author={Dai, Weichen and Chen, Yezeng and Dai, Zijie and Huang, Zhijie and Liu, Yubo and Pan, Yixuan and Song, Baiyang and Zhong, Chengli and Li, Xinhe and Wang, Zeyu and others}, journal={arXiv preprint arXiv:2409.18695}, year={2024} }
网易云音乐数据集
该数据集包含了网易云音乐平台上的歌手信息、歌曲信息和歌单信息,数据通过爬虫技术获取并整理成CSV格式,用于音乐数据挖掘和推荐系统构建。
github 收录
FER2013
FER2013数据集是一个广泛用于面部表情识别领域的数据集,包含28,709个训练样本和7,178个测试样本。图像属性为48x48像素,标签包括愤怒、厌恶、恐惧、快乐、悲伤、惊讶和中性。
github 收录
THUCNews
THUCNews是根据新浪新闻RSS订阅频道2005~2011年间的历史数据筛选过滤生成,包含74万篇新闻文档(2.19 GB),均为UTF-8纯文本格式。本次比赛数据集在原始新浪新闻分类体系的基础上,重新整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐。提供训练数据共832471条。
github 收录
DALY
DALY数据集包含了全球疾病负担研究(Global Burden of Disease Study)中的伤残调整生命年(Disability-Adjusted Life Years, DALYs)数据。该数据集提供了不同国家和地区在不同年份的DALYs指标,用于衡量因疾病、伤害和早逝导致的健康损失。
ghdx.healthdata.org 收录
Subway Dataset
该数据集包含了全球多个城市的地铁系统数据,包括车站信息、线路图、列车时刻表、乘客流量等。数据集旨在帮助研究人员和开发者分析和模拟城市交通系统,优化地铁运营和乘客体验。
www.kaggle.com 收录