kpubdata/seoul-apartment-trades
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/kpubdata/seoul-apartment-trades
下载链接
链接失效反馈官方服务:
资源简介:
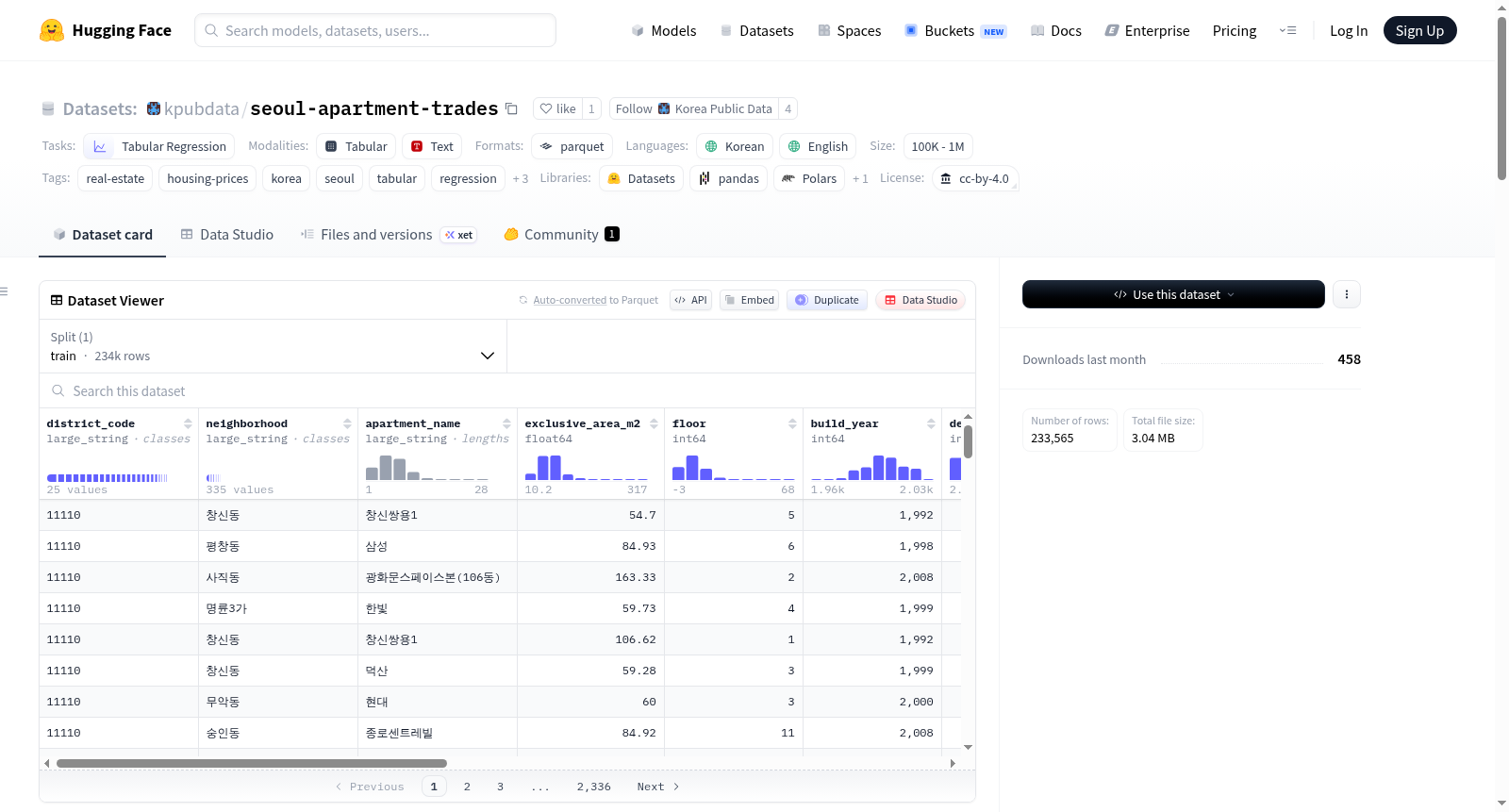
该数据集包含韩国首尔公寓的实际销售交易记录,涵盖了2020年1月至2024年12月(60个月)期间首尔所有25个区(gu)的数据。数据来源于韩国国土交通部(MOLIT)通过data.go.kr公共数据API。数据集包含233,565条记录和14个特征,主要用于表格回归任务,目标变量为`deal_amount_10k_krw`(交易价格,单位为10,000韩元)。文本值(如邻里名称、公寓名称)为韩文,列名为英文以便全球访问。
Real apartment sale transaction records in Seoul, South Korea, covering all 25 districts (gu) from January 2020 to December 2024 (60 months). Sourced from the Ministry of Land, Infrastructure and Transport (MOLIT) via data.go.kr public data API. The dataset contains 233,565 records and 14 features, primarily for tabular regression tasks with the target variable `deal_amount_10k_krw` (transaction price in units of 10,000 KRW). Text values (neighborhood, apartment_name) are in Korean, while column names are in English for global accessibility.
提供机构:
kpubdata
搜集汇总
数据集介绍
构建方式
该数据集源自韩国国土交通部通过data.go.kr公共数据API发布的公寓交易详细资料,经系统性采集与清洗后构建而成。数据收录了2020年1月至2024年12月间首尔特别市全部25个行政区的实际公寓买卖交易记录,共计233,565条样本,涵盖14个特征字段。每个交易样本均包含行政区域代码、法定洞名称、公寓名称、专用面积、楼层、建筑年份及交易日期等结构化信息,并以交易金额(单位:万韩元)作为回归任务的预测目标变量。
特点
数据集在时间与空间维度上展现出显著的覆盖广度与细粒度特征,跨时五年的月度交易数据使时序分析成为可能。特征组合兼顾物理属性(面积、楼层、楼龄)与行政属性(区域代码、洞名),其中专用面积与交易金额的统计分布呈现右偏形态,反映了首尔房市价格分化的典型特征。文本字段(洞名、公寓名)以韩文原貌保存以确保地域识别准确性,而字段命名统一采用英文以降低跨语言使用门槛。
使用方法
数据集以HuggingFace Datasets库格式托管,用户可通过`load_dataset`函数直接加载为表格数据,并便捷地转换为Pandas DataFrame进行后续分析。特别地,该数据集内嵌了行政区域代码与洞名的映射关系,便于研究者按行政区划进行子集筛选或区域对比建模。推荐以`deal_amount_10k_krw`为回归任务标签,构建房价预测模型,并可结合交易日期字段衍生时间序列特征以捕捉市场波动规律。
背景与挑战
背景概述
在房地产经济学与城市计算交叉领域,高细粒度、覆盖多时空维度的房地产交易数据是揭示城市房价动态机制的核心基础资源。Seoul Apartment Trades数据集由韩国国土交通部通过data.go.kr公共数据API发布,并经kpubdata团队整理,收录了2020年1月至2024年12月期间首尔全部25个行政区的逾23万条真实公寓交易记录。该数据集以韩文文本属性(如洞名称、小区名)与英文列名相结合的方式,提供14项特征,涵盖建筑面积、楼层、建筑年份、交易日期及成交价格等关键变量,旨在为房价预测、时空回归等任务提供标准化基准。其开放许可与详实记录,使其成为研究韩国首都圈住房市场波动、政策影响及区域经济差异的重要实证数据源。
当前挑战
该数据集所解决的领域核心挑战在于如何基于多源异质特征实现对首尔公寓价格的稳健回归预测,尤其是面对房地产市场固有的时空非平稳性与稀缺特征交互问题。在数据构建层面,挑战包括:来自公共API的原始数据需经清洗与去重(部分记录存在空白登记日期),且韩文文本属性的编码与对齐(如洞名称与行政代码的匹配)增加了处理复杂度;此外,交易金额分布呈严重右偏(最大值为最小值的400余倍),且少量异常值(如-3层楼层)可能影响模型稳定性。这些挑战要求在预处理阶段采用鲁棒的异常检测、合理的特征工程(如构建住房年龄、交易季节等派生变量)以及针对时空依赖的建模策略,以在现实波动中提取可靠的预测信号。
常用场景
经典使用场景
在房地产经济学与城市数据科学的交叉领域中,首尔公寓交易数据集为研究者提供了长达五年、覆盖首尔全部25个行政区的精细化交易记录。其经典使用场景在于构建基于多元特征的住房价格回归模型,研究者可利用公寓面积、楼层、建筑年龄、交易时间等结构化信息,通过随机森林、梯度提升或神经网络等算法,精准预测单位交易价格(以万韩元计)。该数据集凭借其时间跨度与空间粒度,成为分析韩国首都圈住房市场动态、评估区域级价格差异的基石性资源。
实际应用
在实际应用层面,该数据集为政府住房政策制定者、金融机构评估人员及房地产科技企业提供了关键决策支持。政府部门可借此追踪首尔各行政区住房价格指数变化,为调控措施提供量化依据;银行与担保机构能构建更精细的抵押物估值模型,降低贷款风险;房地产信息平台可利用历史交易数据,向用户提供个性化定价建议与市场趋势报告。此外,数据集的时间序列特性使其能够服务于购房者的时机选择分析,帮助普通消费者在复杂的市场环境中做出更明智的决策。
衍生相关工作
围绕该数据集已催生出一系列具有影响力的衍生产品与研究工作。示例工作包括:基于地理位置与社会经济特征构建首尔公寓价格的时空地理加权回归模型,揭示街区级价格异质性;利用交易时间序列进行房价指数编制与经济景气分析;整合邻近学区、地铁站等外部因素,开发多模态住房估值算法。该数据集还常被用作时间序列预测竞赛的基准,以及新型回归模型在房地产领域效能的验证平台,持续推动着韩国计算社会科学与城市信息学的发展。
以上内容由遇见数据集搜集并总结生成


