patent_sdg_dataset
收藏Hugging Face2025-12-02 更新2025-12-03 收录
下载链接:
https://huggingface.co/datasets/graziasveva93/patent_sdg_dataset
下载链接
链接失效反馈官方服务:
资源简介:
该数据集通过弱监督学习的方式,使用大型语言模型自动标注专利文档,并将其映射到联合国可持续发展目标(SDGs)。数据集包含三个子数据集:silver、patents和papers,以及从Elsevier Scopus API检索的full_sdg_papers。它为研究SDG在专利文本中的相关性提供了一个银标准资源,支持SDG导向的专利分析、弱监督和基于频率的多标签分类、注重可持续性的创新映射以及基于LLM的摘要/提取用于后续的基于检索的多标签分类任务。
创建时间:
2025-12-01
原始信息汇总
数据集概述
基本描述
- 数据集名称:patent_sdg_dataset
- 创建方法:基于论文《From scratch to silver: Creating trustworthy training data for patent-SDG classification using Large Language Models》中描述的方法论创建。
- 核心内容:包含使用弱监督、多标签分类流程自动标注并映射到联合国可持续发展目标(SDGs)的专利文档。同时包含在所述检索步骤中使用的中间步骤专利/论文功能-解决方案-应用提取数据集。
- 用途:为研究专利文本中的SDG相关性提供银标准资源,支持以下研究方向:
- SDG导向的专利分析
- 弱监督和基于频率的多标签分类
- 以可持续发展为重点的创新图谱绘制
- 用于后续基于检索的多标签分类任务的基于LLM的摘要/提取
数据集结构
数据集包含三个不同的数据子集,对应不同的文件。
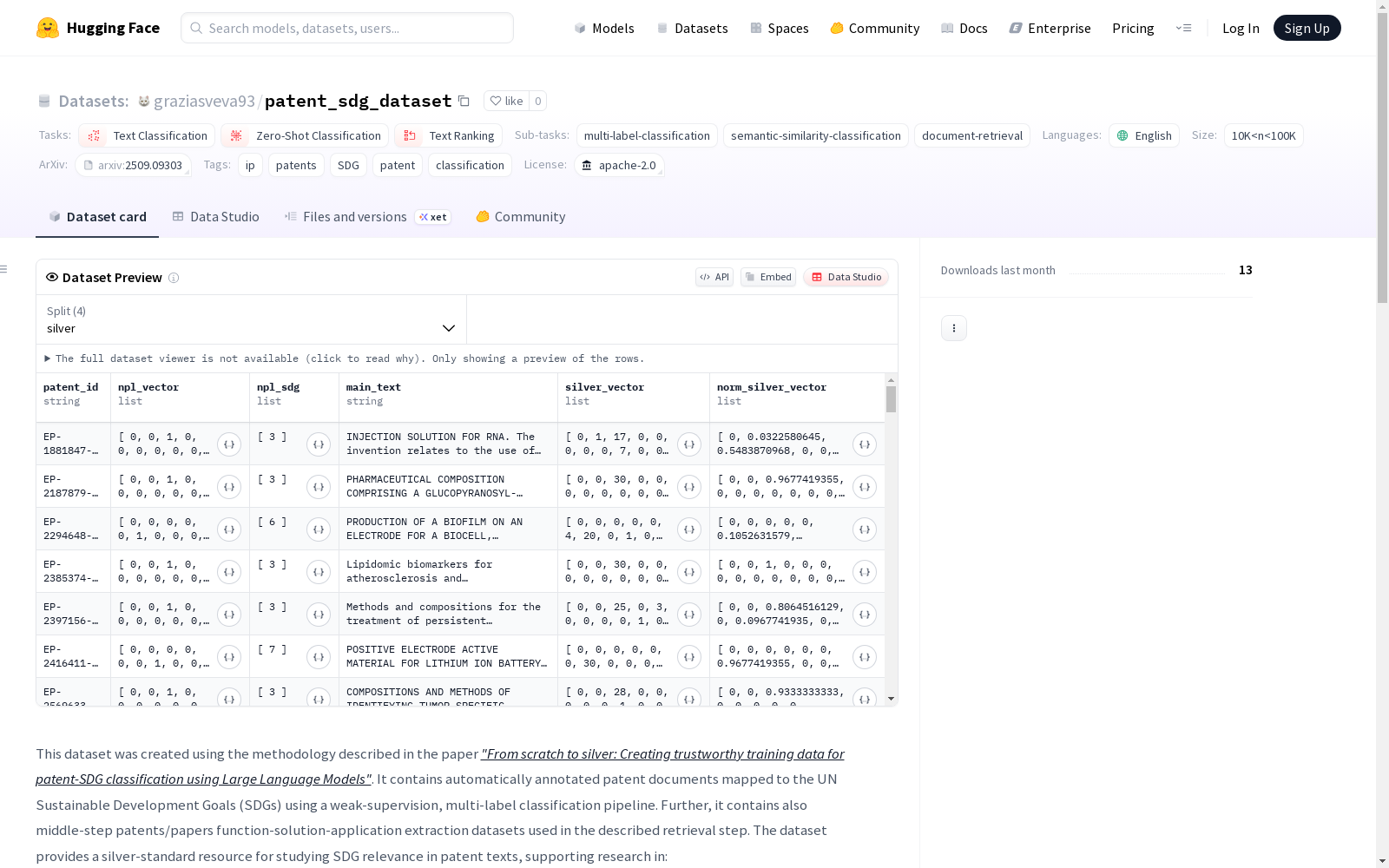
1. silver (patent_sdg_dataset.jsonl)
- 描述:每行对应一项专利。
- 列字段:
patent_id:专利的唯一标识符。npl_vector:与非专利文献引用对应的多标签向量。npl_sdg:与npl_vector列相关的可持续发展目标。main_text:合并的标题和摘要文本。silver_vector:基于频率的SDG多标签向量。norm_silver_vector:归一化的基于频率的SDG多标签向量。
2. patents (patents.jsonl) 与 papers (papers.jsonl)
- 描述:每行对应一项专利或一篇论文。
- 列字段:
patent_id/papers_id:专利/论文的唯一标识符。title:专利/论文的标题。abstract:专利/论文的摘要。main_text:合并的标题和摘要文本。function:LLM提取的专利/论文功能。solution:LLM提取的专利/论文解决方案。application:LLM提取的专利/论文应用。
3. full_sdg_papers (papers_full_list.jsonl)
- 描述:每行对应一篇论文及其从Elsevier Scopus API检索到的相关SDG分类。相关分类源自Elsevier’s SDG Research Mapping Initiative查询。
技术信息
- 许可证:apache-2.0
- 任务类别:文本分类、零样本分类、文本排序
- 任务ID:多标签分类、语义相似性分类、文档检索
- 语言:英语 (en)
- 标签:ip, patents, SDG, patent, classification
- 规模类别:10K<n<100K
- 注释创建者:机器生成
引用
@misc{ascione2025scratchsilvercreatingtrustworthy, title={From scratch to silver: Creating trustworthy training data for patent-SDG classification using Large Language Models}, author={Grazia Sveva Ascione and Nicolò Tamagnone}, year={2025}, eprint={2509.09303}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2509.09303}, }
搜集汇总
数据集介绍
构建方式
在可持续创新分析领域,专利与联合国可持续发展目标(SDG)的关联性研究日益受到重视。该数据集的构建采用了弱监督与多标签分类的先进方法,通过大型语言模型自动提取专利文档中的功能、解决方案及应用信息,并基于频率统计生成银标准标注。具体流程包括从专利文本中检索相关科学文献,利用Elsivier Scopus API获取论文的SDG分类,最终通过多步骤管道将专利映射至对应的可持续发展目标,形成结构化的标注数据。
特点
该数据集的核心特点在于其多层次的结构设计与自动化标注机制。它包含银标准标注、专利与论文的原始文本及其LLM提取的关键要素,以及完整的论文-SDG映射数据,为研究提供了丰富的分析维度。数据集支持多标签分类、零样本分类和文本检索等多种任务,特别适用于可持续创新图谱构建和弱监督学习场景。其标注来源于机器生成,规模介于万至十万条之间,确保了数据的可扩展性与一致性。
使用方法
针对可持续技术评估与专利分析的研究需求,该数据集可灵活应用于不同场景。银标准标注部分可直接用于训练多标签分类模型,以预测专利与SDG的关联;专利与论文的提取字段(如功能、解决方案)可用于文本检索或语义相似性计算,支持创新趋势分析;完整的论文-SDG映射数据则为外部验证或知识增强提供了可靠参考。研究者可依据具体任务选择相应数据分割,结合机器学习或自然语言处理技术,深入探索专利文本中的可持续发展内涵。
背景与挑战
背景概述
在可持续发展目标(SDGs)成为全球创新政策核心导向的背景下,专利文献作为技术发展的重要载体,其与SDGs的关联性分析日益受到学术界与产业界的关注。专利-SDG数据集(patent_sdg_dataset)由研究人员Grazia Sveva Ascione与Nicolò Tamagnone于2025年创建,旨在通过弱监督与大型语言模型技术,自动化构建专利文本与联合国可持续发展目标之间的映射关系。该数据集的核心研究问题是解决专利领域中SDG多标签分类任务缺乏高质量标注数据的困境,为可持续导向的专利分析、创新图谱绘制以及基于检索的多标签分类研究提供了关键的数据基础,推动了计算社会科学与知识产权交叉领域的方法学进展。
当前挑战
专利-SDG数据集所针对的领域挑战在于,专利文本通常具有高度的技术性与领域特异性,其与抽象、多维的可持续发展目标之间的语义关联难以通过传统分类方法准确捕捉。构建过程中的主要挑战包括:如何在没有现成标注数据的情况下,利用弱监督流程与大型语言模型从零生成可信的“银标准”训练数据;如何设计有效的检索与频率统计机制,以处理专利与学术文献的异构信息,并实现稳健的多标签向量生成;以及如何确保自动化标注流程的透明度与可复现性,以支撑后续的SDG导向专利分析研究。
常用场景
经典使用场景
在可持续创新分析领域,专利文本与联合国可持续发展目标(SDGs)的关联性识别是一项关键任务。该数据集通过自动化标注流程,为专利-SDG分类提供了银标准训练资源,其经典使用场景聚焦于多标签文本分类模型的训练与评估。研究者可借助数据集中的专利标题、摘要及频率向量,构建弱监督学习框架,以探索专利技术如何映射至17项SDGs,进而量化创新活动的可持续性导向。
实际应用
在实际应用层面,该数据集支持政策制定者与创新管理机构进行可持续技术监测。通过分析专利与SDGs的关联,可识别绿色技术发展趋势、评估区域或产业的可持续创新绩效,并为科研资助方向提供数据驱动的决策依据。此外,企业亦可利用该数据集进行竞争对手技术布局分析,优化自身的可持续研发战略。
衍生相关工作
围绕该数据集衍生的经典工作主要集中于弱监督学习与检索增强分类方法。相关研究借鉴其构建的“功能-解决方案-应用”提取框架,进一步优化了基于大语言模型的专利文本表示。同时,该数据集也催生了针对多模态专利数据(如结合引文网络)的SDG预测模型,以及用于可持续技术路径绘制的动态图谱分析工具。
以上内容由遇见数据集搜集并总结生成


