KIT Motion-Language Dataset
收藏arXiv2018-08-09 更新2024-06-21 收录
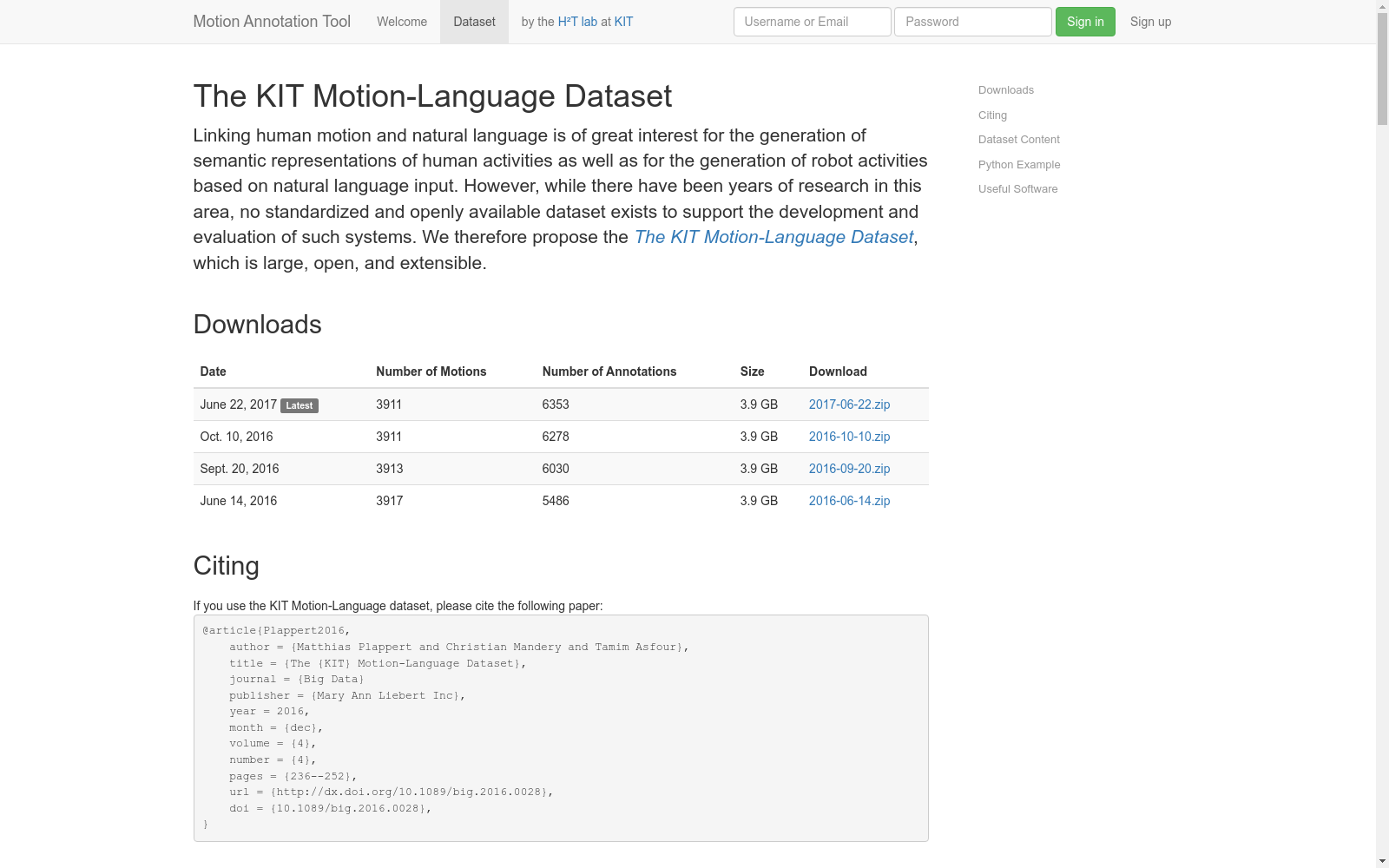
下载链接:
https://motion-annotation.humanoids.kit.edu/dataset
下载链接
链接失效反馈官方服务:
资源简介:
KIT Motion-Language Dataset是由德国卡尔斯鲁厄理工学院的高性能人形技术实验室开发的大型、开放且可扩展的数据集。该数据集整合了多个运动捕捉数据库的数据,并通过统一的表示方法,使其独立于捕捉系统或标记集,便于不同来源的数据处理。数据集包含3911个运动记录,涵盖了行走、操作、交互等多种运动类型,总时长达到11.23小时。通过众包方法和专门设计的网络工具Motion Annotation Tool,获取了6278个自然语言注释,这些注释详细描述了每个运动的动作。数据集的创建过程中,还采用了一种新颖的困惑度基础选择方法,以系统地选择需要进一步注释的运动,确保数据集的全面性和准确性。该数据集主要应用于机器人学领域,旨在通过自然语言输入生成机器人活动,提高人机交互的丰富性和多模态性。
The KIT Motion-Language Dataset is a large-scale, open, and scalable dataset developed by the High-Performance Humanoid Technologies Laboratory at the Karlsruhe Institute of Technology (KIT), Germany. This dataset integrates data from multiple motion capture databases, and adopts a unified representation framework to make it independent of capture systems or marker sets, facilitating data processing from diverse sources. The dataset contains 3911 motion recordings, covering various motion types such as walking, manipulation, interaction, etc., with a total duration of 11.23 hours. A total of 6278 natural language annotations, detailing the actions of each motion, were collected through crowdsourcing methods and a purpose-built web tool called Motion Annotation Tool. During the development of this dataset, a novel perplexity-based selection method was also employed to systematically select motions that require further annotation, ensuring the comprehensiveness and accuracy of the dataset. This dataset is primarily applied in the field of robotics, aiming to generate robot activities from natural language inputs and enhance the richness and multimodality of human-robot interaction.
提供机构:
卡尔斯鲁厄理工学院(Karlsruhe Institute of Technology)
创建时间:
2016-07-14
搜集汇总
数据集介绍
构建方式
KIT Motion-Language Dataset的构建基于对人类动作与语言描述之间关系的深入研究。该数据集通过采集多模态数据,包括人体动作视频和相应的自然语言描述,经过精细的标注和配对处理,确保每一段动作视频都有准确且详细的语言描述。数据集的构建过程中,采用了先进的动作捕捉技术和自然语言处理工具,以确保数据的精确性和一致性。
特点
KIT Motion-Language Dataset的显著特点在于其多模态数据的丰富性和精确性。数据集包含了多种日常生活中的动作,涵盖了从简单到复杂的各种动作类型,且每种动作都有多角度的视频记录和详细的语言描述。此外,数据集还特别注重动作与语言之间的语义一致性,使得研究者能够更好地探索动作与语言之间的深层关系。
使用方法
KIT Motion-Language Dataset适用于多种研究领域,如计算机视觉、自然语言处理和人工智能。研究者可以利用该数据集进行动作识别、动作生成、语言描述生成等任务的研究。使用时,研究者可以通过数据集提供的API或直接下载数据进行分析和模型训练。为了充分利用数据集,建议结合深度学习框架进行模型的开发和验证,以实现动作与语言之间的有效映射和转换。
背景与挑战
背景概述
KIT Motion-Language Dataset,由卡尔斯鲁厄理工学院(KIT)的研究团队于2019年创建,专注于动作与语言的联合理解。该数据集汇集了大量人类动作视频片段及其对应的自然语言描述,旨在推动动作识别与语言生成技术的发展。主要研究人员包括Jens Lehmann和Gerhard Neumann等,他们的核心研究问题是如何在多模态数据中实现精确的动作与语言对齐。该数据集的发布对动作识别、自然语言处理以及人机交互等领域产生了深远影响,为跨模态学习提供了宝贵的资源。
当前挑战
KIT Motion-Language Dataset在构建过程中面临多项挑战。首先,动作与语言的对齐问题复杂,需确保每个动作片段的描述准确且语义一致。其次,数据集的规模和多样性要求高,以涵盖尽可能多的动作类型和语言表达方式。此外,视频数据的采集和标注过程耗时且成本高昂,需克服技术与资源的双重限制。在应用层面,如何有效利用该数据集进行模型训练,以实现高效的动作识别与语言生成,仍是当前研究的重点和难点。
发展历史
创建时间与更新
KIT Motion-Language Dataset由卡尔斯鲁厄理工学院(KIT)于2019年创建,旨在为动作识别与语言描述的跨模态研究提供高质量数据。该数据集在创建后经过多次更新,最近一次更新是在2021年,进一步丰富了数据内容和标注精度。
重要里程碑
KIT Motion-Language Dataset的标志性事件之一是其首次公开发布,这一事件极大地推动了动作与语言结合的研究领域。数据集包含了丰富的动作序列及其对应的自然语言描述,为研究者提供了跨模态学习的宝贵资源。此外,2020年的更新引入了更多的动作类别和更精细的标注,显著提升了数据集的应用范围和研究价值。
当前发展情况
当前,KIT Motion-Language Dataset已成为动作识别与语言描述研究领域的重要基准数据集之一。其在多个跨模态任务中展现了卓越的性能,如动作识别、动作描述生成等。数据集的持续更新和扩展,不仅推动了相关算法的发展,也为多模态学习提供了新的研究方向。未来,随着更多研究者的参与和技术的进步,KIT Motion-Language Dataset有望在更广泛的领域中发挥重要作用,进一步促进人工智能与自然语言处理的深度融合。
发展历程
- KIT Motion-Language Dataset首次发表,该数据集由卡尔斯鲁厄理工学院(KIT)的研究团队创建,旨在为机器人学习和人机交互提供丰富的运动和语言数据。
- KIT Motion-Language Dataset首次应用于机器人导航和任务执行的研究中,展示了其在多模态学习中的潜力。
- 该数据集被广泛应用于多个国际会议和期刊的论文中,进一步验证了其在机器人学和人工智能领域的应用价值。
- KIT Motion-Language Dataset的扩展版本发布,增加了更多的运动序列和语言描述,提升了数据集的多样性和复杂性。
常用场景
经典使用场景
KIT Motion-Language Dataset在人机交互和机器人学领域中,常用于研究语言指令与机器人动作之间的映射关系。该数据集通过收集人类语言指令及其对应的机器人动作序列,为研究者提供了一个标准化的测试平台,用于开发和评估自然语言处理与机器人控制相结合的算法。
实际应用
在实际应用中,KIT Motion-Language Dataset为智能家居、服务机器人和工业自动化等领域提供了关键支持。例如,在智能家居环境中,用户可以通过自然语言指令控制家电设备,而服务机器人则能够根据用户的语言提示执行特定任务,如导航、物品递送等。这些应用极大地提升了用户体验和操作便捷性。
衍生相关工作
基于KIT Motion-Language Dataset,研究者们开发了多种语言到动作的映射模型,如基于深度学习的序列到序列模型和强化学习算法。这些模型不仅在学术界引起了广泛关注,还在实际应用中展现了显著的性能提升。此外,该数据集还激发了关于多模态学习、跨领域知识迁移等新兴研究方向的探索,进一步推动了机器人学和自然语言处理领域的融合与发展。
以上内容由遇见数据集搜集并总结生成


