MMDocIR
收藏arXiv2025-01-15 更新2025-01-17 收录
下载链接:
https://huggingface.co/MMDocIR
下载链接
链接失效反馈官方服务:
资源简介:
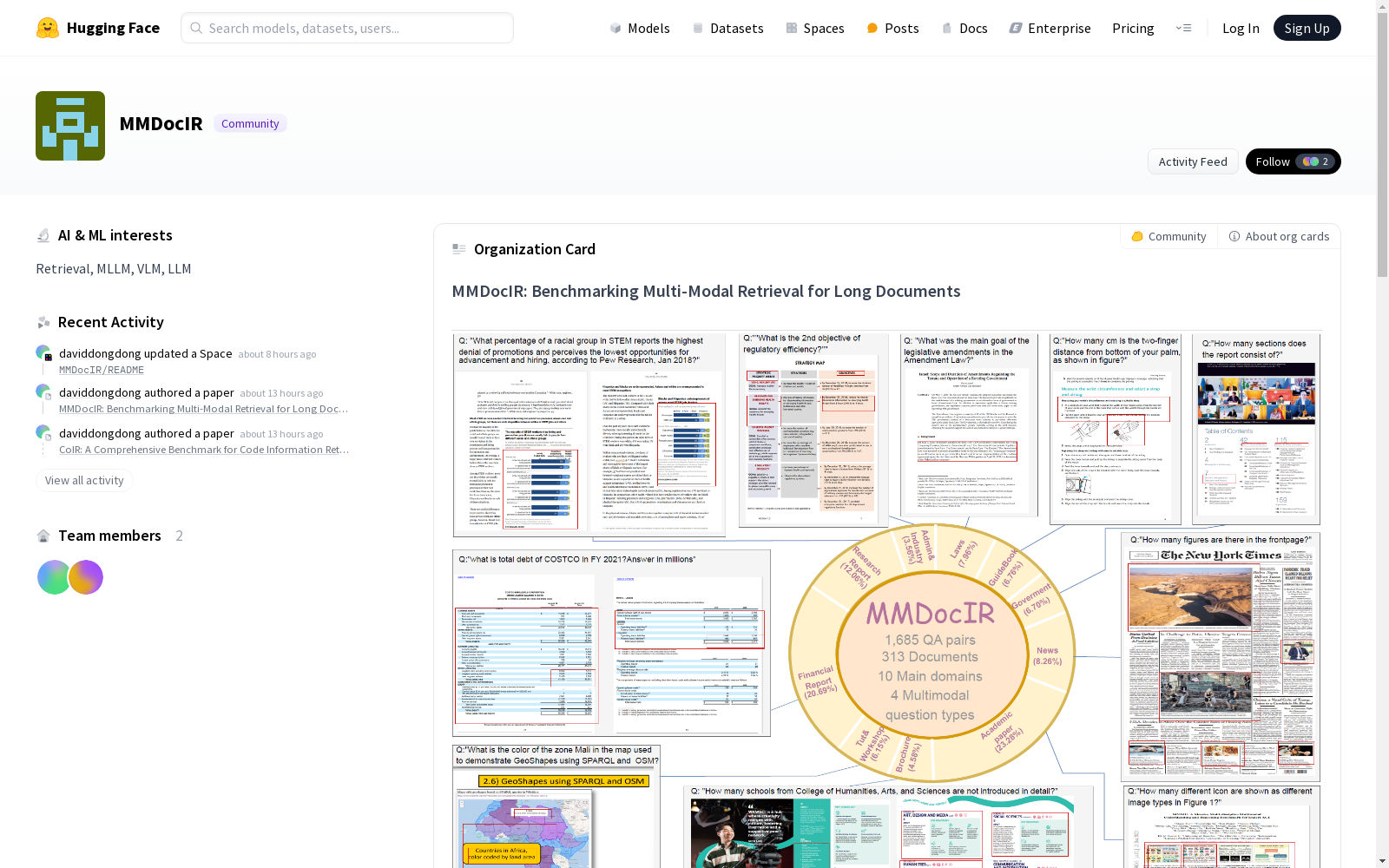
MMDocIR是由华为诺亚方舟实验室创建的多模态文档检索基准数据集,旨在解决长文档中多模态内容的检索问题。该数据集包含313个文档和1685个问题对,涵盖了10个主要领域,如学术论文、财务报告、政府文件等。每个问题都附有页面级和布局级的注释,帮助精确定位文档中的相关信息。数据集的创建过程包括从现有文档视觉问答(DocVQA)基准中筛选和修订问题,并通过专家注释确保问题与检索任务的相关性。MMDocIR的应用领域主要集中在多模态文档检索系统的训练和评估,旨在提升系统在处理复杂文档时的检索能力。
MMDocIR is a multimodal document retrieval benchmark dataset developed by Huawei Noah's Ark Lab, which aims to address the retrieval challenge of multimodal content in long documents. This dataset consists of 313 documents and 1,685 question-document pairs, covering 10 major domains including academic papers, financial reports, government documents and more. Each question is equipped with page-level and layout-level annotations to facilitate accurate localization of relevant information within the target documents. The construction process of MMDocIR involves screening and revising questions from existing document visual question answering (DocVQA) benchmarks, as well as verifying the relevance of these questions to the retrieval task through expert annotations. The primary application scenarios of MMDocIR are the training and evaluation of multimodal document retrieval systems, with the objective of enhancing the retrieval performance of such systems when dealing with complex documents.
提供机构:
华为诺亚方舟实验室
创建时间:
2025-01-15
搜集汇总
数据集介绍
构建方式
MMDocIR数据集的构建基于多模态文档检索的需求,旨在解决长文档中多模态内容(如图表、表格、布局信息)的检索问题。数据集包含313份长文档,涵盖10个主要领域,每份文档平均65.1页。通过从现有的文档视觉问答(DocVQA)基准中筛选和修订问题,确保其适合信息检索任务。随后,专家对1,685个问题进行了页面级和布局级标注,页面级标注标识了包含答案证据的具体页面,布局级标注则通过边界框精确标注了页面内的关键证据。此外,训练集包含73,843个问答对,通过手动或自动方法对6,878份文档进行标注,确保了数据集的多样性和复杂性。
特点
MMDocIR数据集的特点在于其多模态性和细粒度的标注。数据集不仅包含文本,还涵盖了图像、表格、图表等多种模态信息,且通过页面级和布局级标注提供了更精细的检索粒度。页面级标注帮助定位相关页面,而布局级标注则进一步细化到页面内的具体元素(如段落、图表、表格等)。此外,数据集的问题设计复杂,部分问题需要跨模态理解或多页推理,挑战了模型的多模态推理能力。数据集还通过交叉验证确保了标注的高质量,页面级和布局级标注的F1分数分别达到95.2和87.1。
使用方法
MMDocIR数据集的使用方法主要围绕页面级和布局级检索任务展开。页面级检索任务旨在根据用户查询定位文档中最相关的页面,而布局级检索任务则进一步细化到页面内的具体布局元素。用户可以通过视觉驱动或文本驱动的检索器进行实验,视觉驱动检索器直接利用文档截图进行多模态信息编码,而文本驱动检索器则通过OCR或视觉语言模型(VLM)将多模态内容转换为文本后再进行检索。实验表明,视觉驱动检索器在性能上显著优于文本驱动检索器,尤其是在处理复杂多模态内容时。数据集还提供了丰富的训练和评估资源,支持模型在多模态文档检索任务中的训练和性能评估。
背景与挑战
背景概述
MMDocIR数据集由华为诺亚方舟实验室的研究团队于2025年提出,旨在解决多模态文档检索领域的核心问题。该数据集包含313份长文档和1,685个问题-答案对,涵盖10个主要领域,如学术论文、财务报告、政府文件等。MMDocIR的独特之处在于其不仅支持页面级检索,还引入了布局级检索任务,能够更精细地定位文档中的特定元素,如段落、图表和表格。该数据集的构建基于现有的文档视觉问答(DocVQA)基准,并通过专家标注和自动化方法相结合的方式生成高质量的标签。MMDocIR的发布为多模态文档检索系统的训练和评估提供了重要的基准资源,推动了该领域的研究进展。
当前挑战
MMDocIR数据集在构建和应用过程中面临多重挑战。首先,多模态文档检索任务本身具有复杂性,需要同时处理文本、图像、表格等多种模态信息,如何有效融合这些信息并实现精准检索是一个关键难题。其次,数据集的构建过程中,文档的多样性和长度增加了标注的难度,尤其是布局级标注需要精确识别文档中的特定元素,如段落、图表等,这对标注的准确性和一致性提出了更高要求。此外,现有的多模态检索模型在处理高分辨率文档时,计算成本和复杂度显著增加,如何在保证检索精度的同时提升效率也是一个亟待解决的问题。最后,数据集中部分问题需要跨模态理解和多页推理,这对模型的综合能力提出了更高的挑战。
常用场景
经典使用场景
MMDocIR数据集主要用于多模态文档检索任务,特别是在长文档中定位与用户查询相关的页面和布局信息。其经典使用场景包括在学术论文、财务报告、政府文件等长文档中,通过结合文本、图像、表格和图表等多模态信息,精确检索出与问题相关的页面或特定布局。该数据集通过提供页面级和布局级的标注,支持细粒度的检索任务,帮助模型在复杂的文档结构中高效定位信息。
解决学术问题
MMDocIR数据集解决了多模态文档检索领域中的关键学术问题,特别是在长文档中如何有效整合和检索多模态信息。传统文档检索主要依赖文本信息,而MMDocIR通过引入视觉驱动的检索方法,显著提升了模型在复杂文档中的检索性能。实验表明,视觉驱动的检索器在大多数情况下优于文本驱动的检索器,尤其是在处理包含大量图像、表格和图表的文档时。该数据集为多模态文档检索提供了新的基准,推动了该领域的研究进展。
衍生相关工作
MMDocIR数据集衍生了一系列相关研究工作,特别是在多模态文档检索和视觉语言模型的应用领域。基于该数据集,研究者开发了多种视觉驱动的检索模型,如DPR-Phi3和Col-Phi3,这些模型在页面级和布局级检索任务中表现出色。此外,MMDocIR还推动了多模态文档检索基准的标准化,促进了该领域的进一步发展。相关研究还包括如何优化视觉语言模型以更好地处理高分辨率文档图像,以及如何通过多模态融合提升检索性能。
以上内容由遇见数据集搜集并总结生成


