Pitts-IAL, SF-IAL-Base, SF-IAL-Large
收藏github2024-07-04 更新2024-07-13 收录
下载链接:
https://github.com/xsx1001/AddressCLIP
下载链接
链接失效反馈官方服务:
资源简介:
Pitts-IAL数据集是从Pittsburgh-250k原始数据集中提取的,用于图像地址定位问题。SF-IAL-Base和SF-IAL-Large数据集是从CosPlace的SF-XL数据集中提取的,同样用于图像地址定位问题。这些数据集包含了图像和相应的地址标注,用于训练和评估图像地址定位模型。
The Pitts-IAL dataset is extracted from the original Pittsburgh-250k dataset and is intended for image geolocalization tasks. The SF-IAL-Base and SF-IAL-Large datasets are derived from the SF-XL subset of CosPlace, and are also used for image geolocalization. These datasets contain images and their corresponding geolocation annotations, which are employed for training and evaluating image geolocalization models.
创建时间:
2024-07-04
原始信息汇总
AddressCLIP 数据集概述
概述
摘要。本研究引入了一个由社交媒体和新闻摄影引发的新问题,称为图像地址定位(Image Address Localization, IAL),旨在预测图像拍摄地点的可读文本地址。现有的两阶段方法涉及预测地理坐标并将其转换为人类可读地址,这可能导致歧义且资源密集。相比之下,我们提出了一种端到端框架名为AddressCLIP,通过对比学习实现图像与地址和场景描述的对齐,并通过流形学习约束图像特征与空间距离的关系。此外,我们专门为IAL问题构建了来自匹兹堡和旧金山的三个不同规模的数据集。实验表明,我们的方法在提出的数据集上取得了令人信服的性能,并优于代表性的视觉-语言模型迁移学习方法。此外,广泛的消融研究和可视化展示了所提出方法的有效性。
图像地址定位数据集
标注
从百度云链接或谷歌云端硬盘链接下载论文中使用的IAL数据集的标注和分割。
Pitts-IAL
下载 Pittsburgh-250k
从这里下载原始的Pittsburgh-250k数据集。
重新组织
解压.zip文件并将它们全部放入./datasets/Pitts-IAL/文件夹。
SF-IAL-Base & SF-IAL-Large
下载 CosPlace
按照CosPlace的说明获取原始的SF-XL数据集。
我们仅使用了/processed文件夹中的图像。下载并将其放入./datasets/processed/文件夹。
搜集汇总
数据集介绍
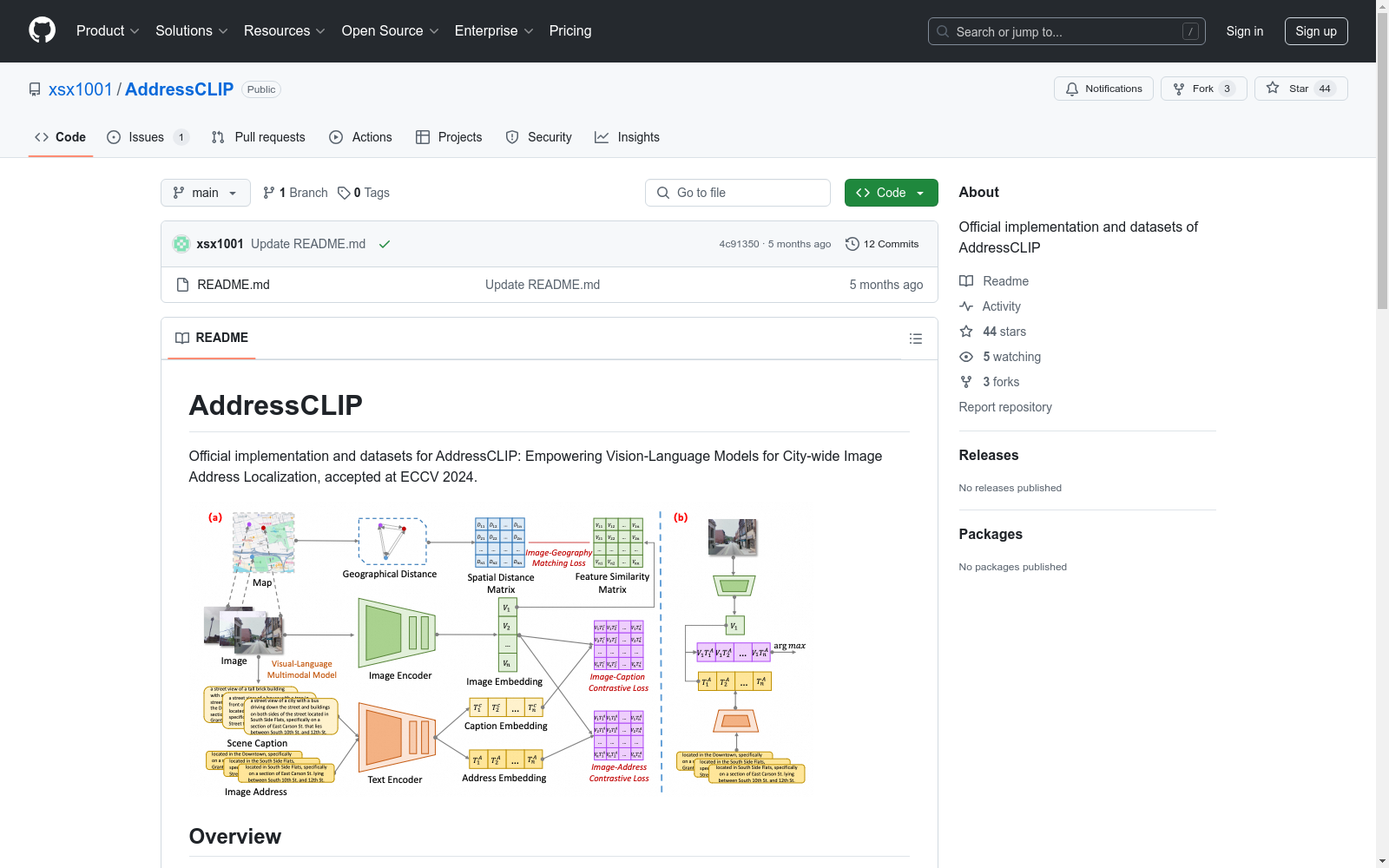
构建方式
在构建Pitts-IAL、SF-IAL-Base和SF-IAL-Large数据集时,研究团队首先从Pittsburgh和San Francisco两个城市收集了大规模的图像数据。对于Pitts-IAL,原始数据来自Pittsburgh-250k数据集,通过解压缩并重新组织到指定文件夹中。而SF-IAL-Base和SF-IAL-Large则基于CosPlace项目中的SF-XL数据集,仅使用其中的/processed文件夹内容,并将其整合到相应目录下。这些数据集的构建旨在为图像地址定位(IAL)问题提供高质量的训练和测试样本,确保数据集的多样性和覆盖范围。
特点
这些数据集的显著特点在于其针对图像地址定位问题的专门设计。Pitts-IAL、SF-IAL-Base和SF-IAL-Large不仅包含了丰富的图像数据,还附带了精确的地址标注和场景描述,这为图像与文本的对齐提供了坚实的基础。此外,数据集的规模从小到大,适应了不同层次的研究需求,从基础的SF-IAL-Base到大规模的SF-IAL-Large,均体现了数据集的灵活性和实用性。
使用方法
使用这些数据集时,用户需首先下载相应的标注文件和数据集,并按照README文件中的指导进行数据组织。对于Pitts-IAL,用户需下载Pittsburgh-250k数据集并解压缩至指定目录;对于SF-IAL-Base和SF-IAL-Large,则需从CosPlace项目中获取SF-XL数据集的/processed文件夹内容并整合。随后,用户可根据研究需求,利用这些数据集进行模型训练和评估,特别是在图像地址定位和视觉语言模型的研究中,这些数据集将发挥重要作用。
背景与挑战
背景概述
在社交媒体和新闻摄影的推动下,图像地址定位(Image Address Localization, IAL)成为一个新兴的研究问题。IAL旨在预测图像拍摄地点的可读文本地址,相较于传统的两阶段方法(预测地理坐标并转换为人类可读地址),AddressCLIP提出了一种端到端的框架,通过图像-文本对齐和图像地理匹配来增强语义信息。该研究由一组主要研究人员在2024年欧洲计算机视觉会议(ECCV)上提出,构建了三个数据集:Pitts-IAL、SF-IAL-Base和SF-IAL-Large,分别来自匹兹堡和旧金山,涵盖不同尺度。这些数据集的创建不仅为IAL问题提供了丰富的资源,还显著推动了视觉-语言模型在该领域的应用和发展。
当前挑战
尽管AddressCLIP在图像地址定位方面取得了显著进展,但其构建过程中仍面临诸多挑战。首先,图像与文本地址的对齐需要高精度的语义理解,这在复杂的城市环境中尤为困难。其次,图像地理匹配的实现依赖于对空间距离的精确建模,这要求数据集具备高度的地理信息准确性。此外,数据集的构建涉及大量图像的收集和标注,这一过程既耗时又资源密集。最后,如何确保模型在不同城市和环境中的泛化能力,也是一个亟待解决的问题。这些挑战不仅影响了数据集的质量,也限制了其在实际应用中的广泛使用。
常用场景
经典使用场景
在城市规模图像地址定位(IAL)领域,Pitts-IAL、SF-IAL-Base和SF-IAL-Large数据集被广泛用于训练和评估视觉-语言模型。这些数据集通过对比学习方法,实现了图像与地址及场景描述的精确对齐。此外,通过图像地理匹配技术,模型能够有效约束图像特征与空间距离之间的关系,从而提升地址定位的准确性。
实际应用
在实际应用中,这些数据集可用于社交媒体和新闻摄影中的图像地址自动标注,极大地提高了内容管理的效率。此外,它们还可应用于智能城市规划和导航系统,通过精确的图像地址定位,提升城市管理的智能化水平。
衍生相关工作
基于这些数据集,研究者们开发了多种视觉-语言模型,如AddressCLIP,显著提升了图像地址定位的性能。此外,这些数据集还激发了对图像地理匹配和对比学习在其他视觉任务中的应用研究,推动了相关领域的技术进步。
以上内容由遇见数据集搜集并总结生成


