AnyEdit
收藏AnyEdit 数据集概述
数据集描述
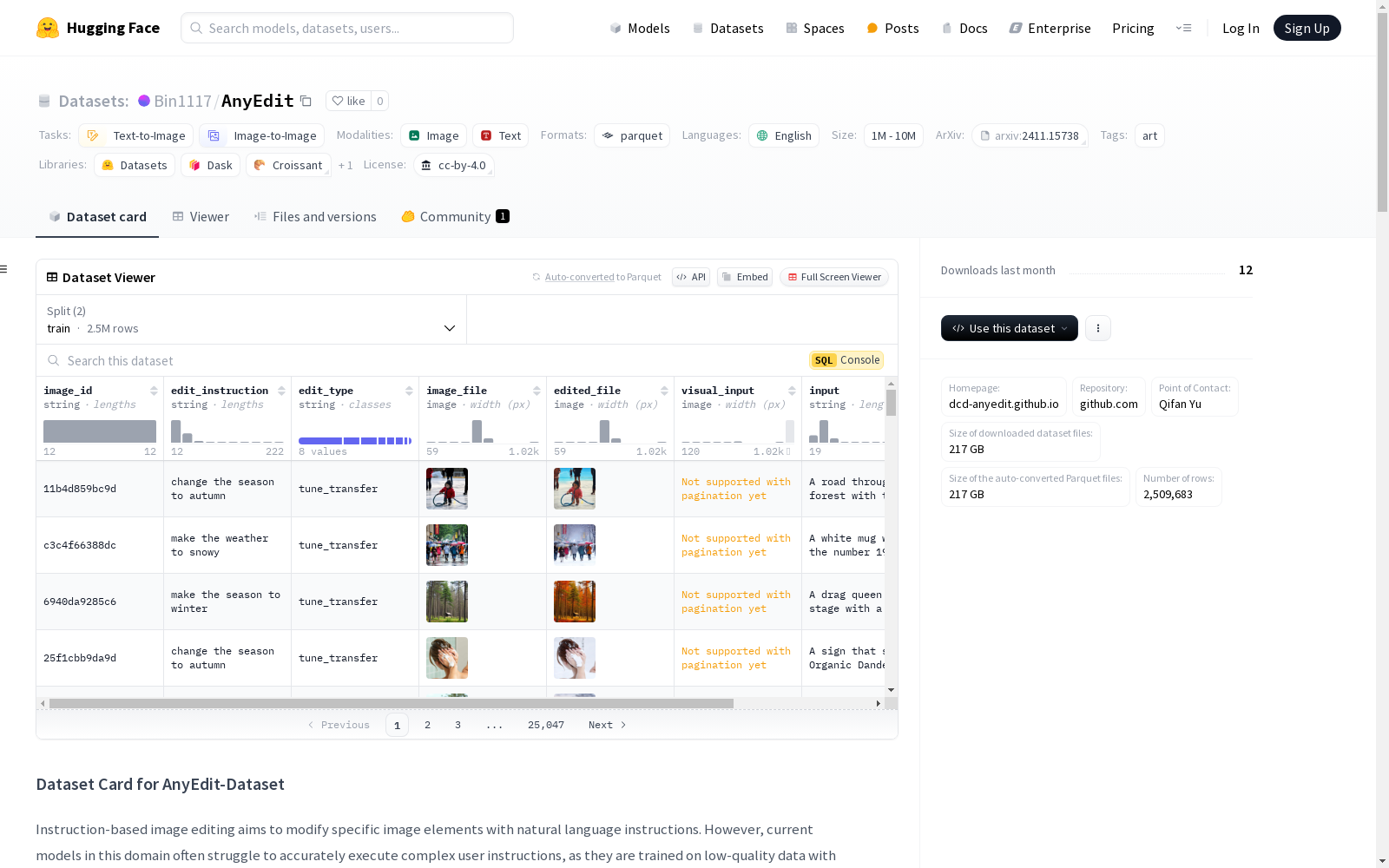
AnyEdit 是一个综合的多模态指令编辑数据集,包含 250 万高质量编辑对,涵盖 25 种编辑类型和五个领域。该数据集旨在通过自然语言指令修改特定图像元素,主要用于文本到图像和指令驱动的图像编辑研究。
数据集详情
特征
- image_id: 字符串类型,图像的唯一标识符。
- edit_instruction: 字符串类型,编辑指令。
- edit_type: 字符串类型,编辑类型。
- image_file: 图像类型,原始图像文件。
- edited_file: 图像类型,编辑后的图像文件。
- visual_input: 图像类型,视觉输入图像(用于多模态编辑)。
- input: 字符串类型,原始图像的描述。
- output: 字符串类型,编辑后图像的描述。
数据集划分
- validation: 包含 5000 个样本,数据大小为 975424085 字节。
- train: 包含 2504683 个样本,数据大小为 170705820774.855 字节。
数据集大小
- 下载大小: 218175371035 字节。
- 数据集大小: 171681244859.855 字节。
配置
- default: 包含训练和验证数据文件。
任务类别
- 文本到图像
- 图像到图像
语言
- 英语
标签
- 艺术
数据集结构
数据集文件结构如下:
├── anyedit_datasets │ ├── train (~2.5M) │ │ ├── remove │ │ ├── background_change │ │ ├── rotation_change │ │ ├── visual_material_transfer │ │ └── ... │ ├── validation (5000) │ ├── anyedit-test (1250)
使用示例
python from datasets import load_dataset from PIL import Image
加载数据集
ds = load_dataset("Bin1117/AnyEdit")
打印样本总数并显示第一个样本
print(f"Total number of samples: {len(ds[train])}") print("First sample in the dataset:", ds[train][0])
获取第一个样本的数据
data_dict = ds[train][0]
保存原始图像
input_img = data_dict[image_file] input_img.save(input_image.jpg) print("Saved input image as input_image.jpg.")
保存编辑后的图像
output_img = data_dict[edited_file] output_img.save(edited_image.jpg) print("Saved output image as edited_image.jpg.")
保存视觉输入图像(如果有)
if data_dict[visual_input] is not None: visual_img = data_dict[visual_input] visual_img.save(visual_input.jpg)
引用
bibtex @misc{yu2024anyeditmasteringunifiedhighquality, title={AnyEdit: Mastering Unified High-Quality Image Editing for Any Idea}, author={Qifan Yu and Wei Chow and Zhongqi Yue and Kaihang Pan and Yang Wu and Xiaoyang Wan and Juncheng Li and Siliang Tang and Hanwang Zhang and Yueting Zhuang}, year={2024}, eprint={2411.15738}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2411.15738}, }