PandaVT/chinese_verdict_examples
收藏Hugging Face2024-01-09 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/PandaVT/chinese_verdict_examples
下载链接
链接失效反馈官方服务:
资源简介:
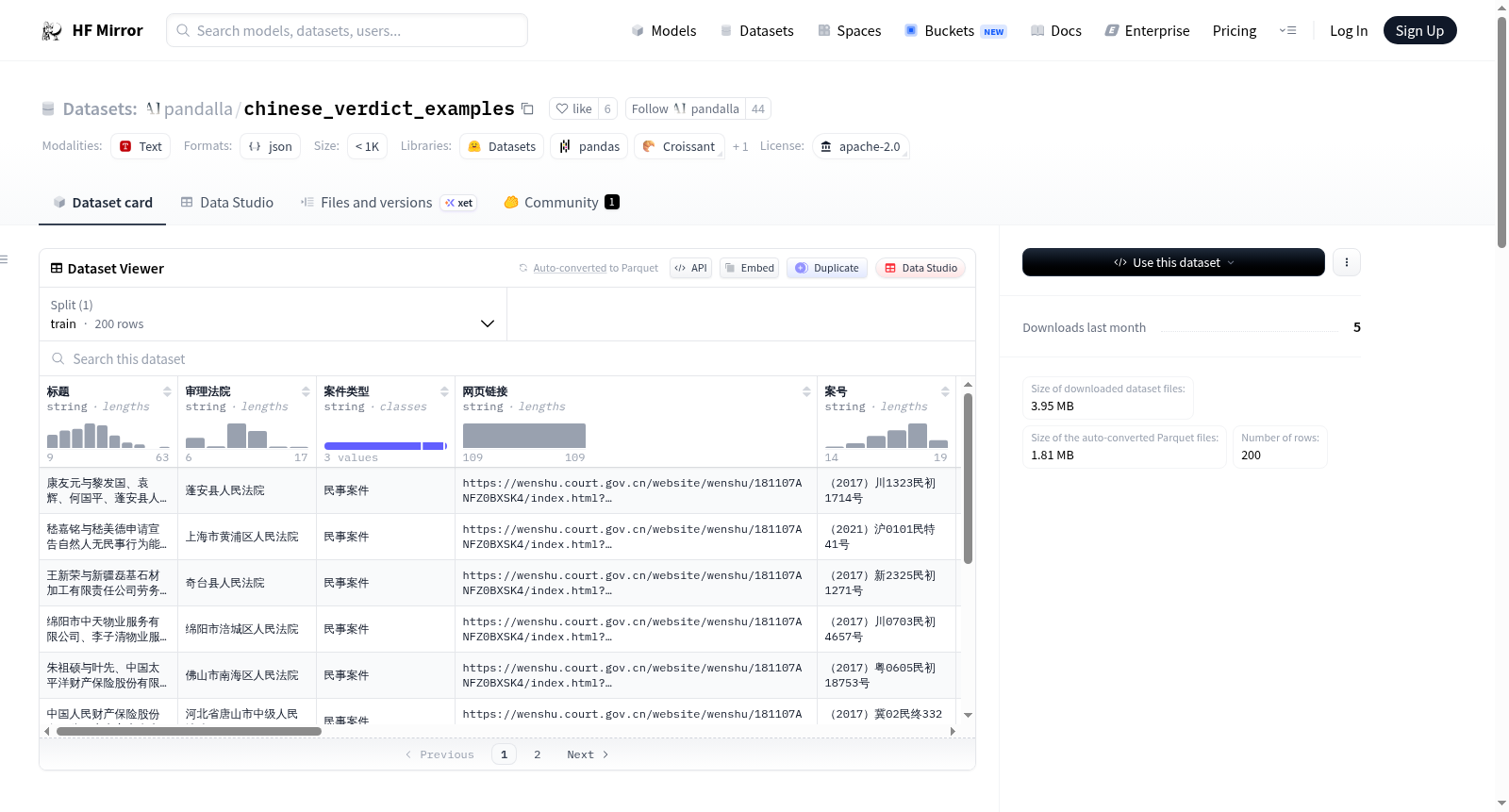
该数据集名为verdicts_200.jsonl,包含了200个来自中国裁判文书网的判决书示例,这些数据经过处理,用于语义检索任务。
This dataset, named verdicts_200.jsonl, contains 200 sample court verdicts sourced from China Judgements Online. All the data have been preprocessed for semantic retrieval tasks.
提供机构:
PandaVT
原始信息汇总
数据集概述
- 数据集名称: verdicts_200.jsonl
- 数据来源: 中国裁判文书网
- 数据内容: 包含200个来自中国裁判文书网的判决书示例
- 处理目的: 用于语义检索
数据使用示例
-
模型: BGE(使用BAAI/bge-large-zh-v1.5模型)
-
功能: 计算查询与判决书之间的相似度
-
示例代码: python from FlagEmbedding import FlagModel from datasets import load_dataset dataset = load_dataset("FarReelAILab/verdicts") model = FlagModel(BAAI/bge-large-zh-v1.5, query_instruction_for_retrieval="为这个句子生成表示以用于检索相关文章:", use_fp16=True) queries = [撞车后,交警不给出全责的认定书,对方车又不签字,事情就将起来了,我该怎么办, 因为做生意资金不足,借款高利贷,写下凭据到时还不了钱就把90㎡的房子抵押给高利贷方这凭据有没有法律效益?] passages = [dataset[train][11][文书内容], dataset[train][173][文书内容]] q_embeddings = model.encode_queries(queries) p_embeddings = model.encode(passages) scores = q_embeddings @ p_embeddings.T print(scores)
-
输出示例: python [[0.5845 0.4473] [0.4902 0.618 ]]
搜集汇总
数据集介绍
构建方式
在司法文书智能检索领域,PandaVT/chinese_verdict_examples数据集通过精选中国裁判文书网公开的200份判决书构建而成。这些文书经过系统化处理,转化为标准化的JSONL格式,每份文书均保留了完整的法律文本结构,包括案由、当事人信息、诉讼请求、事实认定及判决结果等核心要素。构建过程注重文书多样性与代表性,涵盖民事、商事等常见纠纷类型,为语义检索任务提供了结构清晰、内容规范的原始语料。
特点
该数据集以中文法律文书为核心,其突出特点在于文本的专业性与完整性。每份判决书均包含详细的法律事实叙述与裁判逻辑,语言严谨规范,体现了司法文书的正式性与权威性。数据集规模精炼而典型,适用于计算法学研究中的语义相似度匹配、法律问答系统构建等任务。文书内容覆盖交通事故、民间借贷等常见民事案由,为模型理解法律语境提供了真实、多样的语言样本。
使用方法
使用者可通过HuggingFace的datasets库直接加载该数据集,并利用FlagEmbedding工具计算查询与文书之间的语义相似度。具体操作中,可调用BAAI/bge-large-zh-v1.5等预训练模型对查询语句与文书内容进行向量编码,通过内积运算获得相关性分数。该方法支持快速检索与给定法律问题相关的判决案例,为法律智能辅助系统、司法信息检索等应用提供技术基础。数据集的标准化格式便于集成至现有自然语言处理流程,实现端到端的语义匹配实验。
背景与挑战
背景概述
在自然语言处理与法律智能交叉领域,中文裁判文书作为司法实践的文本载体,蕴含丰富的法律逻辑与语义信息。PandaVT/chinese_verdict_examples数据集由相关研究团队于近年构建,旨在针对中国裁判文书在线平台中的判决书进行结构化处理,服务于语义检索任务。该数据集聚焦于民事判决文书,通过提取文书内容,为法律问答、案例匹配及司法辅助系统提供高质量的文本资源。其核心研究问题在于如何从非结构化的法律文本中构建可用于高效语义检索的标准化数据,进而推动法律人工智能在理解、推理与应用方面的发展,对智慧司法与法律科技领域具有显著的实践价值。
当前挑战
该数据集致力于解决法律文本语义检索的挑战,即如何精准匹配用户自然语言查询与复杂法律文书之间的语义关联。法律文本专业性强、表述严谨且富含逻辑结构,传统关键词检索难以捕捉深层语义,需借助先进嵌入模型实现细粒度对齐。在构建过程中,挑战主要集中于数据预处理环节:原始裁判文书格式多样,包含大量法律术语、实体名称及结构化条款,需进行有效的文本清洗与归一化;同时,文书涉及个人隐私与敏感信息,需在数据公开与合规性之间取得平衡,确保脱敏处理符合法律伦理要求。
常用场景
经典使用场景
在司法智能化的浪潮中,PandaVT/chinese_verdict_examples数据集以其精心筛选的200份中国裁判文书实例,为法律文本的语义检索研究提供了关键资源。该数据集的核心应用场景在于构建高效的司法文书检索系统,通过嵌入模型如BGE计算查询与文书之间的语义相似度,从而帮助法律从业者或研究人员快速定位与特定法律问题相关的判例,提升法律信息检索的精准性和效率。
实际应用
在法律实务与公共服务层面,该数据集支撑了智能法律咨询、案例辅助决策等实际应用。例如,普通民众可通过自然语言描述法律困境,系统利用该数据集快速检索相似判例,提供参考解决方案;律师和法官则可借助其进行类案比对,辅助法律论证和裁判文书撰写。这显著降低了法律信息获取门槛,增强了司法透明度和服务可及性。
衍生相关工作
围绕该数据集,已衍生出一系列经典研究工作,主要集中在法律文本嵌入表示学习、跨模态法律信息检索以及判决预测模型构建等领域。例如,基于BGE等预训练模型的法律语义匹配研究,以及利用此类数据训练专门的法律领域检索系统,这些工作不断优化法律AI的性能,并催生了更复杂的司法智能应用,如自动化法律文书生成和裁判结果推理。
以上内容由遇见数据集搜集并总结生成


