ICoS
收藏Hugging Face2025-05-23 更新2025-05-24 收录
下载链接:
https://huggingface.co/datasets/YapayNet/ICoS
下载链接
链接失效反馈官方服务:
资源简介:
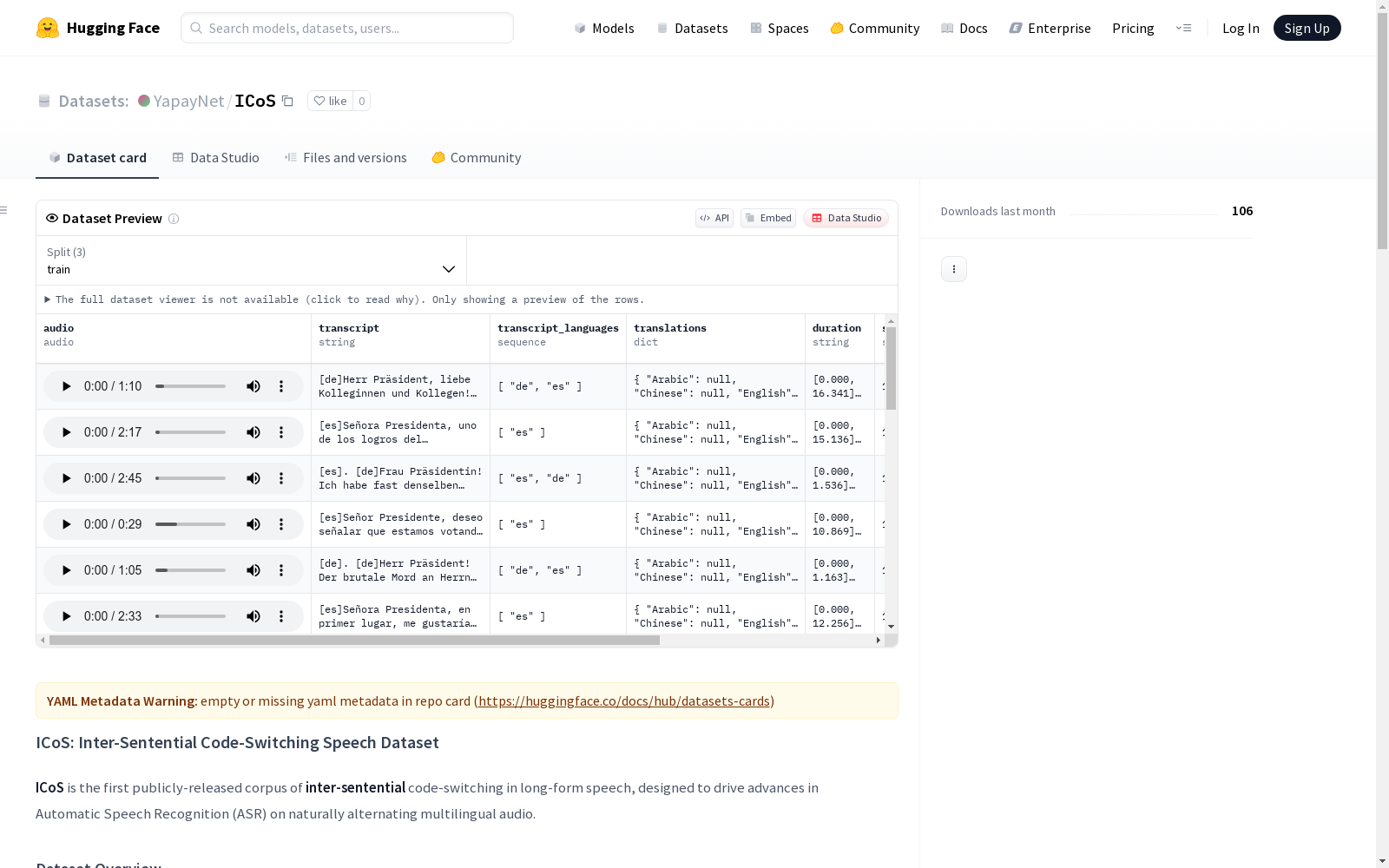
ICoS是一个专注于长篇语音中句子间代码转换现象的公开语音数据集,包含11种目标语言的样本,旨在促进自动语音识别技术在自然交替的多语种音频上的发展。数据集由训练集、验证集和测试集组成,音频采用合成文本语音技术生成,并提供了精确的时间戳对齐的标准转录文本。该数据集特别适用于代码转换的自动语音识别任务,能够解决长篇言语和语言切换点准确度两个核心挑战。
创建时间:
2025-05-20
原始信息汇总
ICoS: 句间语码转换语音数据集概述
数据集简介
- 名称:ICoS(Inter-Sentential Code-Switching Speech Dataset)
- 类型:公开语料库
- 主要用途:推动长语音中自然交替多语言音频的自动语音识别(ASR)研究
核心特征
- 语言现象:专注于句间语码转换(inter-sentential code-switching)
- 语言覆盖:11种目标语言(EN, DE, ES, FR, IT, AR, TR, ZH, JA, UK, KMR)
- 数据来源:Europarl-ST和LLM生成的"LLM-Talks"
- 音频质量:通过Coqui XTTS v2合成的高质量、不间断语音
- 文本标注:包含句子级时间戳的金标准对齐转录本
数据集结构
- 划分方式:三个独立子集(
train,validation,test) - 样本特点:多数样本超过30秒,突破典型模型上下文长度限制
ASR基准测试
- 基准模型:Whisper-largev3
- 转录策略:
- 30秒非重叠窗口
- 30秒窗口+3秒重叠
- 评估指标:
- WER(词错误率)/MER(混合错误率)
- PIER(关注点错误率),专门测量语言切换后第一个词的识别错误
关键性能数据
| 语言对 | WER (30%切换) | PIER (30%切换) |
|---|---|---|
| EN–DE | 16.77% | 45.91% |
| EN–ES | 23.11% | 104.95% |
| EN–FR | 21.65% | 59.25% |
| EN–IT | 18.65% | 84.84% |
数据字段说明
每个样本包含:
audio:音频文件路径或特征transcript:标准文本转录language_key:语言对标识(如"en.de")speaker_id:合成说话人标识duration:音频时长(秒)start_time/end_time:句子级时间戳
使用方式
bash pip install datasets
from datasets import load_dataset
加载完整语料库
ds = load_dataset("YOUR_USERNAME/ICOS")
仅加载测试集
test_ds = load_dataset("YOUR_USERNAME/ICOS", split="test")
加载德-阿测试子集
de_ar = load_dataset("YOUR_USERNAME/ICOS", name="de.ar", split="test")
搜集汇总
数据集介绍
构建方式
在跨语言语音识别研究领域,ICoS数据集的构建采用了创新的混合方法。该数据集通过整合Europarl-ST的议会演讲语料与LLM生成的对话文本,覆盖了11种目标语言的句间语码转换现象。音频数据采用Coqui XTTS v2合成语音技术生成,确保高质量、无间断的长时语音流。文本转录部分经过严格对齐处理,包含句子级时间戳标注,为ASR系统评估提供了精确的基准。数据划分遵循严格的隔离原则,包含训练集、验证集和测试集三个独立子集。
特点
作为首个公开的句间语码转换长语音语料库,ICoS具有鲜明的专业特性。其核心价值在于捕捉段落层级的语言交替现象,同时保持句内语言一致性,这种设计精准模拟了真实场景下的双语转换模式。数据集特别强调长时语音样本的构建,多数样本超过30秒,突破了传统ASR模型的上下文限制。独特的PIER评估指标能有效检测语言边界点的识别错误,配合常规WER/MER指标,形成了多维度的评估体系。基准测试显示,当前主流ASR模型在语言切换点的错误率显著高于平均水平。
使用方法
该数据集为研究者提供了便捷的标准化接入方式。通过HuggingFace datasets库可直接加载完整语料或特定子集,支持按语言对进行精细化检索。数据字段设计兼顾实用性与科研需求,包含音频路径、黄金标准文本转录、语言对标识、说话人ID等关键信息,特别提供的句子级时间戳支持精确的ASR性能评估。使用案例演示了如何加载测试集或特定语言组合,这种模块化设计便于研究者快速开展对比实验。数据集文档包含详尽的基准测试方案,包括30秒非重叠窗口和3秒重叠窗口两种转录策略,为后续研究提供可复现的实验框架。
背景与挑战
背景概述
ICoS数据集作为首个公开的长时语音跨句语码转换语料库,由研究团队针对自动语音识别(ASR)领域中的多语言交替处理问题而构建。该数据集聚焦于句子及段落层面的跨句语码转换现象,涵盖英语、德语、西班牙语等11种语言,语料源自Europarl-ST和LLM生成的合成文本。通过Coqui XTTS v2技术生成高质量连续语音,并配备精确到句子级别的时间戳转录文本,为研究长时语音处理和语言边界识别提供了标准化基准。其创新性体现在首次系统性地量化了跨句语码转换对ASR性能的影响,尤其揭示了现有模型在语言切换点的高错误率现象。
当前挑战
该数据集主要应对自动语音识别领域的两大核心挑战:长时语音序列处理与语言切换边界识别。在领域问题层面,传统ASR模型受限于短时上下文窗口,难以有效处理超过30秒的连续语音;同时语言切换点的首词识别错误率(PIER)显著高于平均错误率,如英语-西班牙语组合的PIER高达104.95%。在数据构建过程中,研究团队需克服多语言语音合成的自然度控制、跨语言文本对齐,以及保持语码转换的句间连贯性等技术难题。这些挑战使得ICoS成为检验ASR系统鲁棒性的重要基准。
常用场景
经典使用场景
在语音识别领域,ICoS数据集为研究者提供了一个独特的平台,专门用于探索句间语码转换现象。该数据集通过长时语音样本和精确的句级时间戳,使得研究者能够深入分析语言切换点对自动语音识别系统的影响。特别是在多语言交替的长时语音场景中,ICoS为模型训练和评估提供了标准化数据。
实际应用
在实际应用中,ICoS数据集可广泛应用于多语言语音识别系统的开发和优化。例如,在跨国企业的多语言会议转录、多语言客服系统的语音识别等场景中,该数据集能够帮助提升系统在语言切换时的识别准确率。此外,ICoS还为语音合成技术的多语言适应性研究提供了重要数据支持。
衍生相关工作
ICoS数据集已经催生了一系列关于多语言语音识别的研究工作。例如,基于该数据集的Whisper-largev3基准测试,研究者们提出了多种针对语言切换点的优化策略。此外,ICoS还被用于探索长时语音的上下文建模方法,推动了多语言语音识别技术的进一步发展。
以上内容由遇见数据集搜集并总结生成


