mariakmurphy55/testingdatasetcards
收藏Hugging Face2023-10-23 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/mariakmurphy55/testingdatasetcards
下载链接
链接失效反馈官方服务:
资源简介:
这是一个非常简单的多元线性回归数据集,适用于初学者。数据集包含三列和二十行,其中两列是自变量(age和experience),一列是因变量(income)。数据集由HUSSAIN NASIR KHAN在Kaggle上整理,由Maria Murphy分享,使用英语,并遵循CC0: Public Domain许可证。数据集的用途是用于线性回归的练习。
This is a very simple multiple linear regression dataset intended for beginners. The dataset contains three columns and twenty rows, with two columns serving as independent variables (age and experience) and one column as the dependent variable (income). It was curated by HUSSAIN NASIR KHAN on Kaggle, shared by Maria Murphy, presented in English, and licensed under CC0: Public Domain. This dataset is designed for linear regression practice.
提供机构:
mariakmurphy55
原始信息汇总
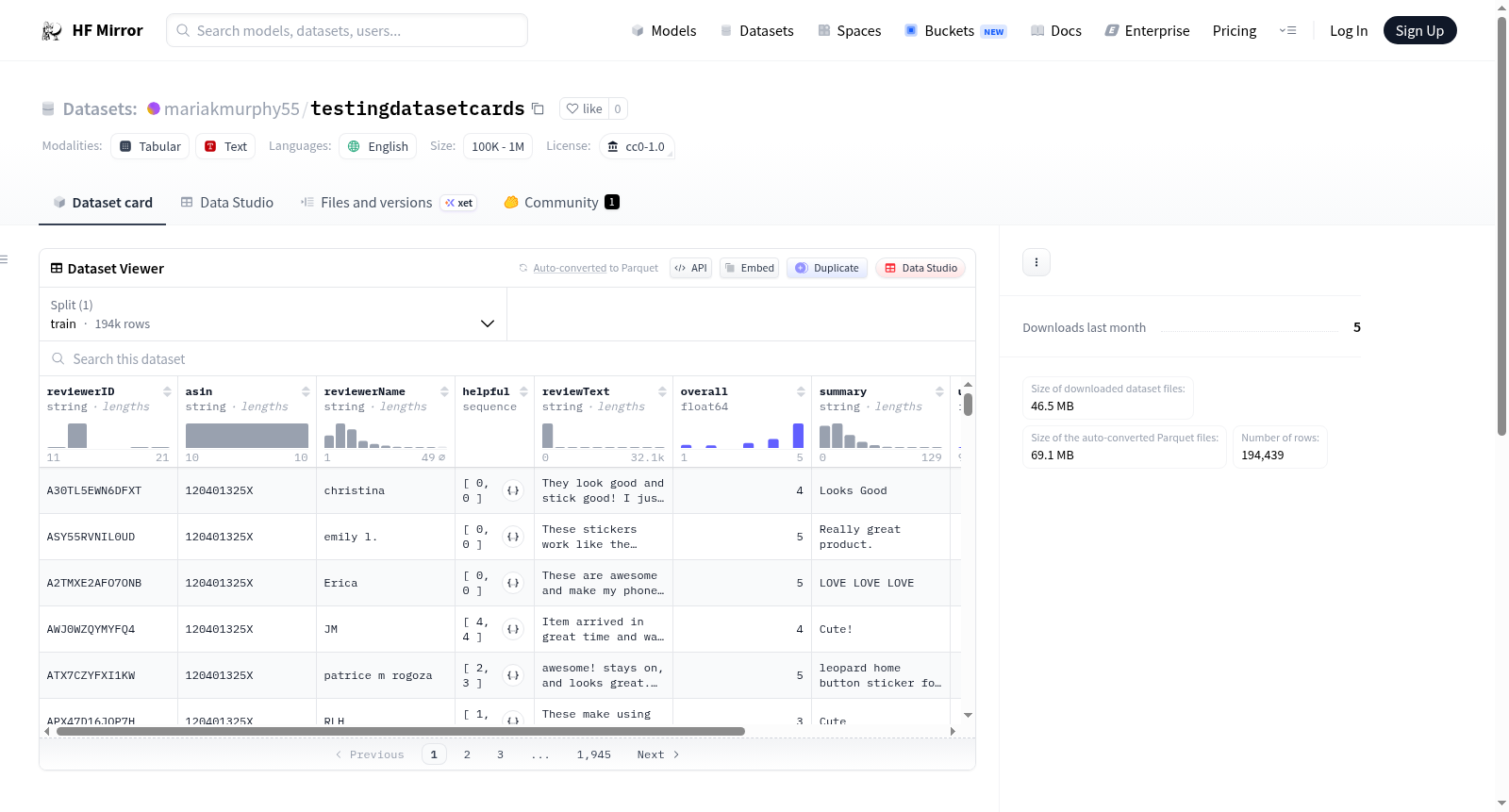
数据集卡片 for Testingdatasetcards
数据集详情
数据集描述
这是一个非常简单的多元线性回归数据集,适合初学者。该数据集只有三列和二十行。包含两个自变量和一个因变量。自变量是 age 和 experience,因变量是 income。
- 由谁策划: HUSSAIN NASIR KHAN (Kaggle)
- 共享者 [可选]: Maria Murphy
- 语言(NLP): 英语
- 许可证: CC0: Public Domain
用途
旨在用于线性回归练习。
数据集结构
包含三列(age, experience, income)和二十个观测值。
搜集汇总
数据集介绍
构建方式
在统计学与机器学习领域,基础数据集常被设计用于教学与实践。该数据集由HUSSAIN NASIR KHAN在Kaggle平台精心整理,并由Maria Murphy共享至HuggingFace社区。其构建过程聚焦于多变量线性回归的入门需求,仅包含二十个观测样本,每个样本涵盖年龄、经验与收入三个关键变量,结构简洁明了,旨在为初学者提供清晰的数据范例。
特点
该数据集以极简主义风格呈现,仅设三列二十行,变量关系直接:年龄和经验作为自变量,收入作为因变量。这种设计避免了冗余信息,突出了线性回归的核心要素——变量间的线性关联。数据规模虽小,却完整覆盖了回归分析的基本结构,便于用户快速理解数据分布与建模流程,尤其适合教育场景中的初步探索。
使用方法
用户可将该数据集直接应用于线性回归模型的实践训练。通过加载数据,可分别以年龄和经验为特征,收入为目标变量,进行模型拟合、参数估计与预测验证。其小巧的体量确保了计算效率,适合课堂演示、算法调试或初学者自主练习,帮助用户掌握数据预处理、模型构建及结果解读的全过程。
背景与挑战
背景概述
在统计学与机器学习领域,线性回归作为基础预测模型,其教学与实践常需简洁明了的数据集支撑。mariakmurphy55/testingdatasetcards数据集由HUSSAIN NASIR KHAN于Kaggle平台创建,后经Maria Murphy共享至HuggingFace社区,发布于CC0公共领域许可下。该数据集专为初学者设计,聚焦于多元线性回归的入门练习,通过仅包含年龄、经验与收入三列共二十条观测数据的极简结构,旨在降低学习门槛,助力用户掌握变量间线性关系的建模核心。其轻量化的特性为教育场景提供了即用资源,虽规模有限,却在基础算法教学中扮演了实用角色。
当前挑战
该数据集所针对的领域挑战在于简化多元线性回归的实践障碍,使学习者能规避复杂数据预处理,直接聚焦模型原理与应用。然而,其构建过程面临显著局限:数据规模极小且特征维度匮乏,仅含两个自变量,难以模拟现实世界中多因素交织的回归问题;样本量不足可能导致模型过拟合或泛化能力弱,无法充分体现统计推断的稳健性要求。此外,数据生成机制与真实分布间的差距可能削弱教学效果,限制其在进阶研究或实际场景中的迁移价值。
常用场景
经典使用场景
在统计学与机器学习领域,线性回归作为基础预测模型,常需简洁数据集以验证算法实现。本数据集以其极简结构——仅含年龄、经验与收入三列变量及二十条观测记录,成为初学者实践多元线性回归的理想工具。通过模拟真实世界变量间线性关系,它允许用户直观理解自变量对因变量的影响,并快速掌握模型拟合、参数估计及残差分析等核心技能。
衍生相关工作
围绕该数据集衍生的经典工作多集中于教学资源开发与算法基准测试。例如,诸多开源机器学习库(如scikit-learn、StatsModels)在其官方示例中采纳类似结构数据,以阐释线性回归API的使用规范;同时,教育研究者常以其为蓝本,构建可视化回归分析工具,动态展示最小二乘法原理。这些衍生成果强化了基础数据科学教育的标准化与普及化,形成了从核心概念到扩展应用的知识传播链条。
数据集最近研究
最新研究方向
在机器学习教育领域,该数据集作为线性回归的入门工具,其简洁结构为初学者提供了直观的实践平台。当前研究聚焦于利用此类小型数据集优化教学模型,结合自动化特征工程与可视化技术,以提升学习效率。热点事件包括在线教育平台对交互式数据集的整合,推动了数据科学普及化。其意义在于降低了机器学习门槛,为后续复杂模型学习奠定基础,促进了教育资源的可及性与标准化发展。
以上内容由遇见数据集搜集并总结生成


