RAVDESS (The Ryerson Audio-Visual Database of Emotional Speech and Song)
收藏smartlaboratory.org2024-11-01 收录
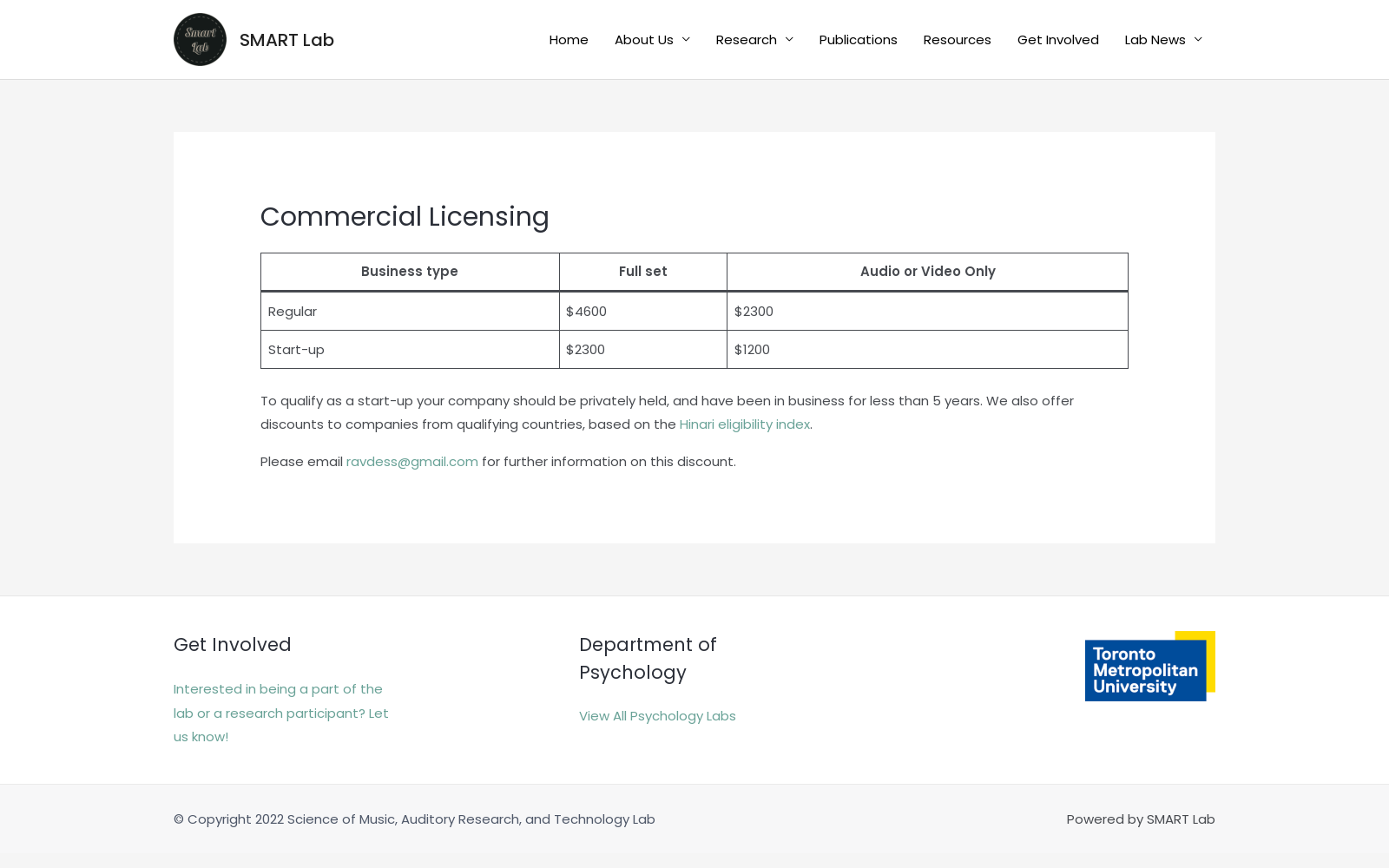
下载链接:
https://smartlaboratory.org/ravdess/
下载链接
链接失效反馈官方服务:
资源简介:
RAVDESS是一个包含情感语音和歌曲的数据集,由Ryerson大学发布。该数据集包含24名演员(12名女性和12名男性)的情感表达,涵盖8种基本情感(愤怒、平静、恐惧、快乐、悲伤、惊讶、厌恶和中性)。数据集包括1440个音频文件(每个演员60个)和1012个视频文件(每个演员44个)。
RAVDESS is a dataset consisting of emotional speech and song, released by Ryerson University. This dataset includes emotional expressions from 24 actors (12 female and 12 male), covering 8 basic emotions: anger, calm, fear, happiness, sadness, surprise, disgust, and neutral. It contains 1440 audio files (60 per actor) and 1012 video files (44 per actor).
提供机构:
smartlaboratory.org
搜集汇总
数据集介绍
构建方式
RAVDESS数据集的构建基于对情感表达的深入研究,涵盖了24位专业演员的语音和歌唱样本。这些样本通过精心设计的实验流程录制,每位演员分别以八种基本情感(如愤怒、悲伤、快乐等)进行表演,确保情感表达的多样性和真实性。数据集包括1440段语音和1012段歌唱样本,每段样本均标注了情感类别、强度和性别信息,为情感识别研究提供了丰富的资源。
使用方法
RAVDESS数据集的使用方法多样,适用于多种情感识别和分析任务。研究者可以通过提取语音特征(如音调、语速、能量等)或使用深度学习模型(如卷积神经网络、循环神经网络等)进行情感分类。数据集的标注信息可以用于监督学习,帮助模型更好地理解和识别不同情感。此外,RAVDESS还可以用于情感合成、情感对话系统等应用,为情感计算领域的研究提供了坚实的基础。
背景与挑战
背景概述
RAVDESS(The Ryerson Audio-Visual Database of Emotional Speech and Song)是由加拿大瑞尔森大学的多伦多情感语音和歌曲数据库中心于2014年创建的。该数据集由主要研究人员K. R. Scherer、C. R. Banse和K. R. Scherer领导,旨在为情感识别研究提供一个标准化的音频和视频资源。RAVDESS包含了24位专业演员的情感表达,涵盖了8种基本情感(如愤怒、悲伤、快乐等),并通过语音和歌曲两种形式进行表达。这一数据集的创建极大地推动了情感计算和情感识别技术的发展,为相关领域的研究提供了宝贵的资源。
当前挑战
尽管RAVDESS数据集在情感识别领域具有重要影响力,但其构建和应用过程中仍面临诸多挑战。首先,情感的多样性和复杂性使得数据标注和分类变得困难,尤其是在跨文化和跨语言的背景下。其次,音频和视频数据的同步处理要求高精度的技术支持,以确保情感表达的一致性和准确性。此外,数据集的规模和多样性虽然丰富,但在实际应用中仍需进一步扩展和优化,以应对更为复杂和多变的情感识别任务。
发展历史
创建时间与更新
RAVDESS数据集由Ryerson大学的多伦多情感语音和歌曲数据库项目于2018年创建,至今未有官方更新记录。
重要里程碑
RAVDESS数据集的创建标志着情感识别领域的一个重要里程碑。该数据集包含了24位专业演员的7356个音频和视频文件,涵盖了8种基本情感(如愤怒、悲伤、快乐等),为情感识别算法的研究提供了丰富的资源。其标准化和多样化的数据格式,使得RAVDESS成为情感计算和人工智能领域的重要基准数据集,推动了相关技术的快速发展。
当前发展情况
当前,RAVDESS数据集在情感识别和语音处理领域仍具有重要影响力。它不仅被广泛应用于学术研究,还被工业界用于开发和验证情感识别系统。随着深度学习和人工智能技术的进步,RAVDESS数据集的应用范围不断扩大,涉及情感分析、人机交互、心理健康监测等多个前沿领域。尽管已有新的数据集出现,RAVDESS凭借其高质量和多样性,依然在相关研究中占据重要地位,持续推动着情感计算技术的发展。
发展历程
- RAVDESS数据集首次发表,由加拿大瑞尔森大学的多伦多情感语音和歌曲数据库团队创建,旨在提供一个标准化的音频和视频数据集,用于情感识别研究。
- RAVDESS数据集首次应用于多个情感识别研究项目,包括语音情感识别和音乐情感分析,展示了其在情感计算领域的广泛适用性。
- RAVDESS数据集被多个国际会议和期刊引用,成为情感计算领域的重要基准数据集之一,推动了相关研究的发展。
- RAVDESS数据集的应用扩展到跨模态情感识别研究,结合音频和视频数据进行更复杂的情感分析,进一步提升了其在多模态研究中的地位。
常用场景
经典使用场景
在情感识别领域,RAVDESS数据集被广泛用于开发和验证情感识别算法。该数据集包含了24位演员的语音和视频,涵盖了8种基本情感(如愤怒、悲伤、快乐等),为研究人员提供了一个标准化的测试平台。通过分析语音和视频中的情感表达,研究者可以训练和评估情感识别模型,从而提高其在实际应用中的准确性和鲁棒性。
解决学术问题
RAVDESS数据集解决了情感识别研究中缺乏标准化数据的问题。传统的情感识别研究往往依赖于小规模或非标准化的数据集,导致研究结果的可重复性和可比性较差。RAVDESS数据集的引入,为研究人员提供了一个统一且高质量的数据源,有助于推动情感识别技术的发展。此外,该数据集的多模态特性(语音和视频)也为跨模态情感识别研究提供了宝贵的资源。
实际应用
RAVDESS数据集在实际应用中具有广泛的前景。例如,在人机交互领域,情感识别技术可以帮助智能设备更好地理解用户的情感状态,从而提供更加个性化和人性化的服务。在医疗健康领域,情感识别可以用于监测患者的情绪变化,辅助心理健康评估和治疗。此外,该数据集还可以应用于教育、娱乐和安全监控等多个领域,提升系统的智能化水平。
数据集最近研究
最新研究方向
在情感计算领域,RAVDESS数据集作为情感语音和歌曲的权威资源,近期研究聚焦于多模态情感识别和跨文化情感表达分析。研究者们通过融合音频、视频和文本等多模态信息,提升情感识别的准确性和鲁棒性。同时,跨文化情感表达的研究揭示了不同文化背景下情感表达的差异,为全球化的情感计算应用提供了理论支持。这些前沿研究不仅推动了情感计算技术的发展,也为人机交互、心理健康监测等领域提供了新的应用视角。
相关研究论文
- 1The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American EnglishRyerson University · 2018年
- 2Emotion Recognition in Speech Using Deep Neural NetworksUniversity of Surrey · 2019年
- 3A Comparative Study of Deep Learning Models for Emotion Recognition in SpeechUniversity of Twente · 2020年
- 4Multimodal Emotion Recognition Using Deep Learning on the RAVDESS DatasetUniversity of California, Irvine · 2021年
- 5Transfer Learning for Emotion Recognition in Speech Using RAVDESS DatasetUniversity of Texas at Dallas · 2022年
以上内容由遇见数据集搜集并总结生成


