eliza-1-training
收藏Hugging Face2026-05-19 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/elizaos/eliza-1-training
下载链接
链接失效反馈官方服务:
资源简介:
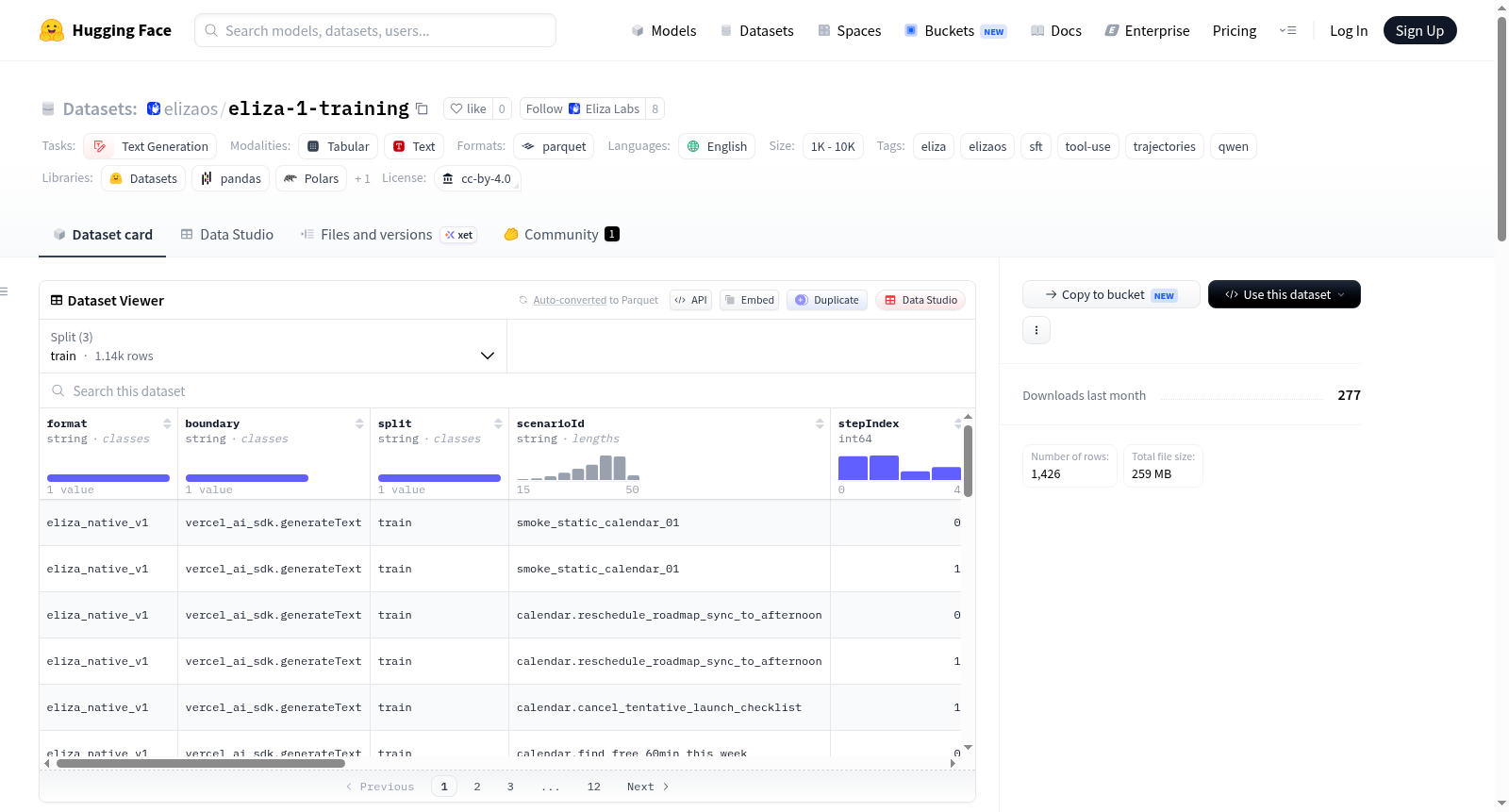
eliza-1训练语料库是专为elizaOS eliza-1 Qwen系列模型设计的规范监督微调轨迹数据集。该数据集旨在用于对Qwen3.5和Qwen3.6因果语言模型进行监督微调和回归评估,特别针对elizaOS智能代理和工具使用的工作负载。数据集包含1426条高质量记录,采用`eliza_native_v1`格式,每条记录对应一个模型交互边界,完整包含请求(包含消息和工具定义)、响应(包含文本和工具调用)以及元数据(如数据分割和质量评级)。数据以JSONL格式提供规范的原生训练、验证和测试分割(train.jsonl, val.jsonl, test.jsonl),同时提供了Parquet格式的Dataset Viewer兼容镜像文件以便于浏览。数据集经过严格验证,所有记录均有效。该数据集基于CC-BY-4.0许可证发布,数据为经过隐私审查的合成LifeOps轨迹数据。
The eliza-1 training corpus is a standardized supervised fine-tuning trajectory dataset specifically designed for elizaOS eliza-1 Qwen series models. This dataset is intended for supervised fine-tuning and regression evaluation of Qwen3.5 and Qwen3.6 causal language models, particularly targeting workloads for elizaOS intelligent agents and tool usage. It contains 1,426 high-quality records in the `eliza_native_v1` format, each corresponding to a model interaction boundary and fully including requests (with messages and tool definitions), responses (with text and tool calls), and metadata (such as data splits and quality ratings). The data is provided in JSONL format with standardized native training, validation, and test splits (train.jsonl, val.jsonl, test.jsonl), along with Parquet-format Dataset Viewer-compatible mirror files for easy browsing. The dataset has undergone rigorous validation, ensuring all records are valid. It is released under the CC-BY-4.0 license, and the data consists of privacy-reviewed synthetic LifeOps trajectory data.
创建时间:
2026-05-05
搜集汇总
数据集介绍
构建方式
该数据集为elizaOS旗下基于Qwen架构的eliza-1模型系列提供了标准化的监督式微调轨迹语料。其构建遵循严格的规范化流程,将原始数据以eliza_native_v1格式封装为JSON Lines文件,每条记录清晰划分格式、边界、请求、响应及元数据等字段,并依托完整的轨迹验证报告确保数据有效性。经严格校验,全部1426条记录均通过完整性检查,无无效数据混入,为模型训练奠定了坚实的质量基础。
使用方法
使用者可通过Hugging Face datasets库加载Parquet镜像文件,并解析native_json字段以还原精确的eliza_native_v1格式行,亦可直接使用规范的JSONL文件配合elizaOS训练脚本进行本地化训练与验证。该数据集专为Qwen3.5/Qwen3.6系列因果语言模型的监督微调与回归评估而设计,适用于智能体及工具调用场景下的文本生成任务,采用CC-BY-4.0许可协议发布。
背景与挑战
背景概述
eliza-1-training数据集由elizaOS团队于2025年创建,旨在为基于Qwen架构的eliza-1系列语言模型提供标准化监督微调轨迹语料库。该数据集聚焦于智能代理与工具使用场景,通过精细的轨迹结构(eliza_native_v1格式)记录模型边界处的请求与响应,为训练具备复杂任务执行能力的大语言模型奠定数据基础。作为elizaOS生态的核心组成部分,该数据集通过严格验证机制(包含1426条有效记录)保障数据质量,对推动面向代理自动化与工具调用的大模型研究具有重要标杆意义。
当前挑战
该数据集所应对的核心领域挑战在于为大语言模型提供结构化、可复现的轨迹数据以支撑智能代理场景下的工具使用与任务规划能力,传统文本生成数据集难以直接捕捉模型与外部工具交互的复杂边界逻辑。构建过程中面临的挑战包括:合成轨迹数据的真实性与多样性平衡,需确保生成的LifeOps数据能够覆盖实际代理场景的复杂工具调用路径;隐私审查与元数据溯源的严格性要求,需在公开发布时保留完整的验证状态和追踪信息;多规模模型系列(0.8B至27B)的统一数据适配架构设计,需兼顾不同参数规模下训练数据的兼容性与有效性。
常用场景
经典使用场景
在人工智能与语言模型微调领域,eliza-1-training 数据集堪称一座精心雕琢的瑰宝,专为 elizaOS 生态中的 Qwen 系列模型量身定制。其经典用法聚焦于监督式微调(SFT)与回归评估,尤其是在智能体(agent)工作流与工具调用(tool-use)场景中。数据以 eliza_native_v1 格式组织,每条记录包含清晰的模型请求与预期响应边界,支持 Vercel AI SDK 的 generateText 接口。研究者通过加载 JSONL 或 Parquet 镜像文件,可无缝复现训练、验证与测试流程,从而优化模型在复杂工具编排任务中的决策能力与响应精度。
解决学术问题
该数据集的核心学术价值在于系统性地解决了语言模型在结构化工具使用与多步骤任务执行中的对齐与泛化难题。传统 SFT 语料往往缺乏对智能体轨迹的严格标注,导致模型在真实工具调用场景中易出现逻辑断裂或指令偏差。eliza-1-training 通过 1426 条经过严格验证(zero invalid records)的高质量轨迹数据,为因果语言模型提供了从请求到响应的完整监督信号。其意义在于推动了“指令遵循-工具交互”这一交叉研究领域的发展,为评估模型在受限环境下的规划与执行能力树立了新范式,并启发了对合成数据隐私审计与验证管线设计的深入探讨。
实际应用
实际应用中,eliza-1-training 数据集赋能 elizaOS 框架下的智能体系统,使其能够精准解读用户意图并驱动外部工具(如 API、数据库、文件系统)完成自动化工作流。例如,在客户服务场景中,模型可基于该数据集微调后,自主解析查询、调用知识库检索工具并生成可操作回复。此外,该数据兼容多种模型规模(从 0.8B 到 27B 参数),支持从轻量级边缘设备到云端大模型的弹性部署。其合成数据的隐私审查特性,更使其成为金融、医疗等敏感领域自动化助手开发的理想基础语料。
数据集最近研究
最新研究方向
当前,eliza-1-training数据集聚焦于面向智能体系统与工具调用工作负载的监督微调与回归评估,为elizaOS生态中的Qwen3.5/Qwen3.6系列因果语言模型提供标准化训练语料。该数据集以合成LifeOps轨迹数据为核心,通过严格的轨迹验证协议和分片设计,确保模型在复杂多步骤任务中的行为一致性。其前沿研究方向在于构建高保真度的智能体交互轨迹库,推动大语言模型在自动化代理、任务规划与工具编排领域的应用突破。这一工作与当下AI Agent规模化部署的热点事件紧密相连,为提升模型在动态环境中的自主决策能力与安全性奠定了数据基础,对推动可信赖的智能体系统发展具有里程碑意义。
以上内容由遇见数据集搜集并总结生成


